Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- Connectivity & Data Prep
- :
- Re: Load from QVD gives different values compared ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Load from QVD gives different values compared to source db table
Hi,
I hope somebody here can help me. I am re-writing a QS application to use QVD files in stead of reading directly from the database. I come across some very strange behaviour while doing that. Probably the strangest is the following. I have a table in an Oracle 11 database. I have a field called 'GEOGRAPHY_CODE' which has datatype VARCHAR2(200 Char) at database level. There are 67 rows for the specific geography I am looking for with values 01 - 66 + 99. When I query the database it returns 67 rows with for all of them 2 character values (which are numeric chars), as it should be. However, when I store this table into a QVD and then load from that QVD, I get 67 rows as expected, but some of the values are all of a sudden 3 characters in stead of 2. But not all of them..... I cannot find any logic in this.
Among the same lines, the tables I am using have ID fields (all NUMBER(16) on database level). When in the LOAD from the QVD I match this field using the WildMatch() function, for some tables I get a match (no matter whether I use a constant or a variable in the function), and for others I don't, whereas on database level (and even visually) the field contains the exact same value as the value I am matching against.
As it seems something is not working as I would expect it to. Anybody got any thoughts on this?
Thanks in advance!
HP
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Marcus,
Thanks for thinking along. I have made a little change to you script to be able to better check some things. Output is surprising, to say the least. It does not seem to be a problem in the QVD storage, but with dataretrieval/display in QS. When I retrieve the same data from db (tried OLE, ODBC, Microsoft driver, Oracle driver) or qvd, the same results are displayed. It seems values are 'confused' between records. Let me try to explain the structure of the data and the issue a bit more in depth. We have 3 geography levels, of which the codes are partially overlapping, partially similar. The codes are numeric values, stored as varchar in the database. When querying the database directly, the codes are displayed properly:
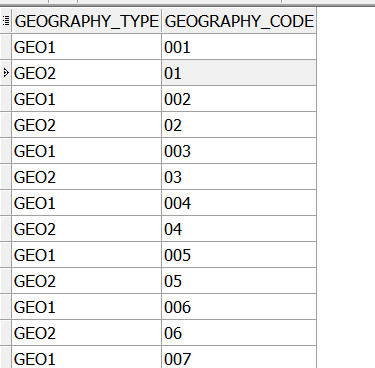
It seems that the GEO1 and GEO2 codes are mixed up in QS, but strangely enough, not for all values:
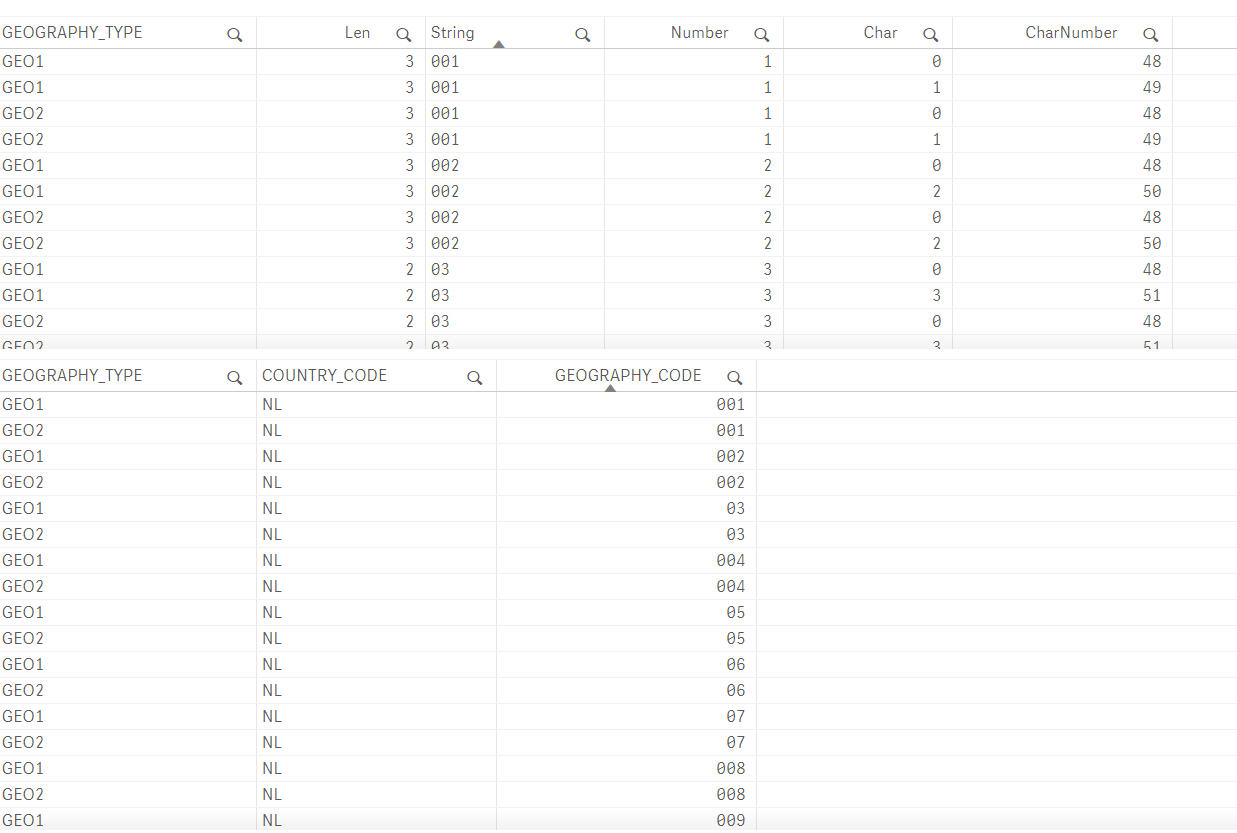
The wierdest thing is that QS reports the field as 3 positions for the faulty values, but then iterates only 2 chars in the script Marcus gave me.
When explicitely converting datatypes while loading and storing the QVD, the results from teh load from the QVD are displayed correctly:
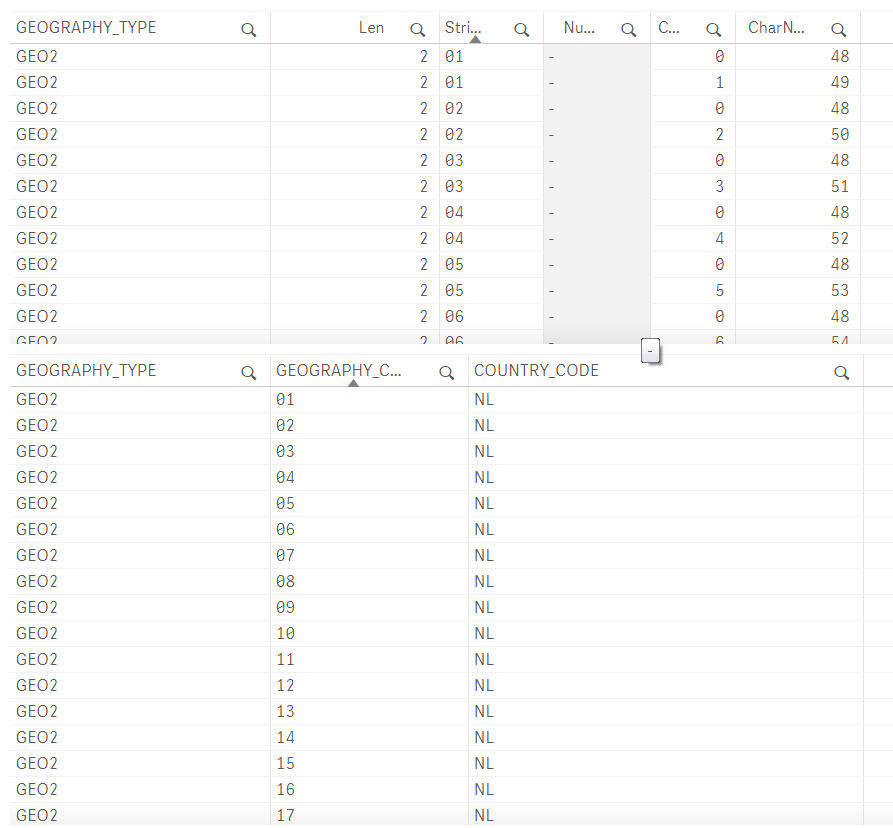
Because it is explicitely converted to text, apparently QS can't translate it back to a number, which is fine in this case.
I have found a way to automatically explicitely concert types by building a load statement based on the ALL_TAB_COLUMS system table in Oracle, however, this remains a workaround, and I consider filing this as a bug (if only I knew how and where  ).
).
TmpCols:
SQL SELECT COLUMN_NAME,DATA_TYPE FROM ALL_TAB_COLUMNS WHERE TABLE_NAME = '$(sTableName)';
LET z = NoOfRows('TmpCols')-1;
SET sLoad = 'LOAD ';
For i = 0 to $(z)
LET sColName = peek('COLUMN_NAME',$(i),'TmpCols');
LET sDataType = peek('DATA_TYPE',$(i),'TmpCols');
LET sLoad = sLoad & if(match(sDataType,'DATE','TIMESTAMP(6)','TIMESTAMP(6) WITH LOCAL TIME ZONE') > 0,'date(',
if(wildmatch(sDataType,'NUMBER*') > 0,'num(','text(')) & sColName & ') as ' & sColName & ', ';
Next
LET sLoad = mid(sLoad,1,len(sLoad)-2) & ';';
Tmp:
$(sLoad);
SQL SELECT * FROM $(sTableName) WHERE
.....;
STORE * from Tmp INTO '$(sQVDTrgFolder)$(sFilePrefix)NEXXUSMIDEMO_GEOGRAPHY.QVD' (qvd);
DROP TABLE Tmp;
It will slow down the QVD creation because we have to loop through every column of every table, but at least the results are correct....
HP !
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think it's a good solution to ensure that each field could be loaded and stored as it should. Especially as I wouldn't expect a quite significantly increasing of the load-times because querying the fieldnames and formattings from the db systemtables and building a load-statement on the fly within the loop shouldn't be take very long. Also the additionally transformations within the preceeding load shouldn't add a significantly amount of time.
Like above mentioned with the most fields there shouldn't be problems by the data-interpretation even or just because Qlik has no datatypes only numeric- or string-fields respectively mixed fields. Problems occur if there are leading spaces or zeros or similar (I know that leading + or - signs lead to a numeric interpretation and probably there are further cases).
Essential how Qlik interprets the data is the first loaded value of each field. This meant adjusting the load-order either within the load or maybe in a foregoing dummy-load will have an effect. You could comprehend it with the following example:
t0:
load text('abc') as F1 autogenerate 1;
t1:
load *, rowno() as RowNo inline [
F1, F2
1, 1
01, 01
001, 001
];
drop tables t0;
which leads (in QlikView but AFAIK Sense should be the same) to this result:

If an approach like this one worked in your case and there aren't too many "problematic" fields you could consider to skip your load-on-the-fly logic and just handle these fields within the application with such a "special" treatment.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
marcus_sommer Thank you for all your time and suggestions! The solution with querying the system tables works for me, so I guess that is the way to go for me. Still think it is a bug though
For the second issue I had, the solution was out here on the forum, but (re) post it here, just in case somebody is looking
The value in the ID field is a large number, and the text representation was in scientific notation. (Mix)Match is a string comparison function so the string I was matching did not match the scientific notation. However
text(num(<id-field>,(dec)) did the job. It converts scientific notation to 'normal'
Kind regards,
HP
- « Previous Replies
-
- 1
- 2
- Next Replies »