Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- Deployment & Management
- :
- Re: Qlik Sense Multi-Node Site over Several AWS In...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Qlik Sense Multi-Node Site over Several AWS Instances
Hi Community,
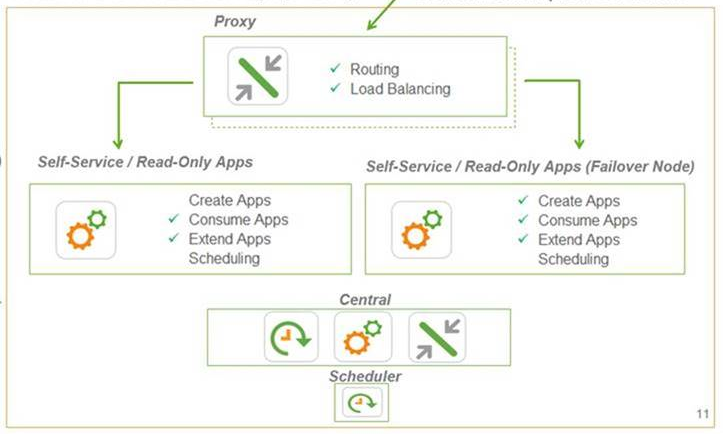
I am currently trying to deploy the below multi-node Production site.
Both Self-Service engine nodes must be hosted on separate AWS instances for disaster recovery, should one AWS instance go down.
Does anyone know of any good documentation to assist the configuration required for this, or can provide some high level guidance?
Your help would be much appreciated! 
- Tags:
- qlik sense deployment framework
- qlik sense in aws amazon
- Qlik Sense on Virtual Private Cloud
- qlik_sense_aws
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi carm1988,
I didn't do yet. But I'm studying an action plan for something similar to your configuration.
There are Shared and Sync Persistence. Sync Persistence is going to being dropped in future releases.
Ref: http://www.bardess.com/qlik-sense-3-2-shared-persistence-goes-mainstream/
Shared Persistence, so.
If you have multiple nodes and consider your objective of resilience, it seems the best solution to move the repository to a database server.
Ref: STT - Understanding Shared Persistence in Qlik Sense - YouTube at 13m:44sec
Database Server.
On AWS, database server means RDS. That's great because you can manage snapshots and replicas at last protection from your data. RDS is very stable, and all the maintenance is easily managed. With monitoring, you can evaluate when increase RDS instance (CPU, storage, ram).
Ref: Bardess Group: Business Analytics & Data Strategy. 973-584-9100
RDS on AWS
For the data sharing, I guess that the solution is to save the data on Central Node using EFS. I didn't find yet any reference or guide. Some reference to EFS here:
Ref: Re: Amazon RDS for the repository database with Shared Persistence? (& related questions)
EFS on AWS
For the license, I'm still trying to understand better. In a multi-node environment with Shared Persistence, you have only 1 repository with 1 License (in RDS). Logins and Tokens are managed from the central node using information ad session on the repository. I'm not 100% sure of this. For the extension of the license (for example: on standby servers), I wrote a post more specific in another thread; if you: have any information or more question, follow-up here:
In my cluster, I plan to use Auto-Scaling clusters for read-only apps. The instance type is the limit for the performance for the user: for heavy load, I could expect also to have 1 user for instance. I could consider also 2 classes for clusters:
Standard with m4.2xlarge, and Deluxe with m4.4xlarge. In the night and weekend should slow down to 1 instance running for clusters. This is just theory.
In my case, the dataset is not so big so I don't use all the RAM and CPU of m4.16xlarge.
Ref: Qlik Sense Server: RAM usage
Read-only Nodes with AWS Auto-scaling
For the Development, I'm using a separate server with a Test Site License. Developers works on a separate server with the last release of QS, attempted configurations, and when ready Apps are exported from Dev to Production. Dev Server is now a on-Demand m4.4x, but I will try on the weekend to move to Spot Requests (2 launches per day, only weekdays).
Ref: Qlik Sense on AWS Spot Request Instances
Developer Nodes on AWS sport requests.
Extend Apps. I don't know exactly how it works on a Multi-Node Cluster. I will search; if you have something, please add to this post.
For disaster recovery (usually developers or sysadmin that mess up the cluster or should be an issue in the AWS zone), I usually keep AMI of the last released software in the same zone and in other zones. I will start manually the new node, and reconnect, reload manually RDS and EFS snapshots. This is the last resource that requires me awake and prompt and 1-2 hours to setting up everything.
Comment: my general perception is that Qlik Sense is relatively new (comparing to Qlik view), but often purchased from Qlik View clients, that are 'old school' clients working with on-premise data farms, not so much scaling, clustering. (expensive metal provided after weeks with high cost of maintenance and updating cycles of years). So not much versatility yet for AWS. Partners mostly don't have a clue on AWS and clouds (it's a new thing for most of them). I can count in the community probably a few dozens of Qlik Sense cloud active users. Comparing to thousands of QlikView, on-premises clients.
I also write a post on Windows Server platform: Qlik Non-Sense Windows Server.
Re: Qlik Sense Enterprise road map: Windows to Linux?
I'm going to deploy my production cluster in the next 2 months. Any feedback, comment, reference is welcome.
Vicio
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you so much for this Vicio, so much help and information.
Carmelle
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Carmelle,
https://www.youtube.com/watch?v=vGsPKLF8T0w
It seems the Qlik is migrating to a new solution based on Linux dockers easy to scale in a cloud cluster.
I can't find more information and my Qlik partner doesn't reply. If that solution can work for you, please
try to ask you Qlik partner (perhaps more responsive than mine 😜 ).
The video link was public this morning, now is unlisted, perhaps they published by mistake
and they could remove it soon.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That video was demo'd at Qonnections and was uploaded as part of this blog I think - Digging in on Docker | Qlik
This is a very forward-looking video and article - the indication was that the functionality shown wouldn't be something we'd see in the next release. I don't think there's anything to look at or test at this stage - it is an insight into what's going on in R&D...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks, alex.walker for the info. All this is very exciting!
Do you know something more about this: https://hub.docker.com/u/qlik/? Docker? Linux? Is related to the hybrid cluster in the video?
Anyway, even without the dockers, do you think is possible to build a scalable, reliable, multi-node cluster on AWS?
Qlik is a little bit late, still, stick to obsolete and expensive Window Server. Most of the enterprise platform already running on Linux dockers from years.
Vicio