Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Blogs
- :
- Technical
- :
- Design
- :
- Recipe for a Pareto Analysis – Revisited
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
This type of question is common in all types of business intelligence. I say “type of question” since it appears in many different forms: Sometimes it concerns products, but it can just as well concern any dimension, e.g. customer, supplier, sales person, etc. Further, here the question was about turnover, but it can just as well be e.g. number of support cases, or number of defect deliveries, etc.
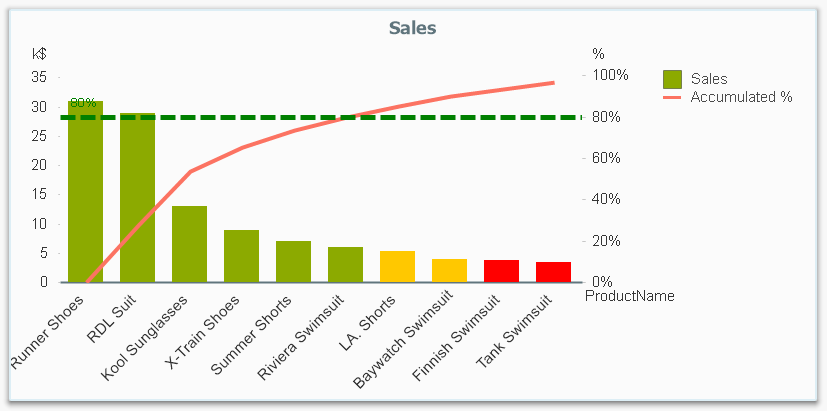
It is called Pareto analysis or ABC analysis and I have already written a blog post on this topic. However, in the previous post I only explained how to create a measure which showed the Pareto class. I never showed how to create a dimension based on a Pareto classification – simply because it wasn’t possible.
But now it is.
But first things first. The logic for a Pareto analysis is that you first sort the products according to their sales numbers, then accumulate the numbers, and finally calculate the accumulated measure as a percentage of the total. The products contributing to the first 80% are your best, your “A” products. The next 10% are your “B” products, and the last 10% are your “C” products. In the above graph, these classes are shown as colors on the bars.
The previous post shows how this can be done in a chart measure using the Above() function. However, if you use the same logic, but instead inside a sorted Aggr() function, you can achieve the same thing without relying on the chart sort order. The sorted Aggr() function is a fairly recent innovation, and you can read more about it here.
The sorting is needed to calculate the proper accumulated percentages, which will give you the Pareto classes. So if you want to classify your products, the new expression to use is
=Aggr(
If(Rangesum(Above(Sum({1} Sales)/Sum({1} total Sales),1,RowNo()))<0.8, 'A',
If(Rangesum(Above(Sum({1} Sales)/Sum({1} total Sales),1,RowNo()))<0.9, 'B',
'C')),
(Product,(=Sum({1} Sales),Desc))
)
The first parameter of the Aggr() – the nested If()-functions – is in principle the same as the measure in the previous post. Look there for an explanation.
The second parameter of the Aggr(), the inner dimension, contains the magic of the sorted Aggr():
(Product,(=Sum({1} Sales),Desc))
This structured parameter specifies that the field Product should be used as dimension, and its values should be sorted descending according to Sum({1} Sales). Note the equals sign. This is necessary if you want to sort by expression.
So the Products inside the Aggr() will be sorted descending, and for each Product the accumulated relative sales in percent will be calculated, which in turn is used to determine the Pareto classes.
The set analysis {1} is necessary if you want the classification to be independent of the made selection. Without it, the classification will change every time the selection changes. But perhaps a better alternative is to use {$<Product= >}. Then a selection in Product (or in the Pareto class itself) will not affect the classification, but all other selections will.
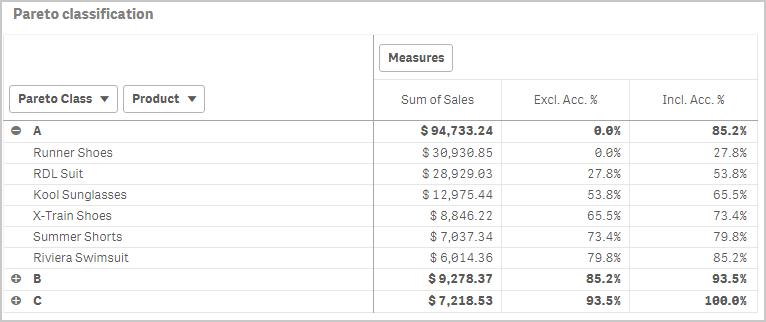
The expression can be used either as dimension in a chart, or in a list box. Below I have used the Pareto class as first dimension in a pivot table.
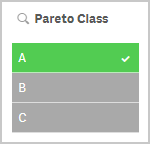
If you use this expression in a list box, you can directly select the Pareto class you want to look at.
The other measures in the pivot table are the exclusive and inclusive accumulated relative sales, respectively. I.e. the lower and upper bounds of the product sales share:
Exclusive accumulated relative sales (lower bound):
=Min(Aggr(
Rangesum(Above(Sum({1} Sales)/Sum({1} total Sales),1,RowNo())),
(Product,(=Sum({1} Sales),Desc))
))
Inclusive accumulated relative sales (upper bound):
=Max(Aggr(
Rangesum(Above(Sum({1} Sales)/Sum({1} total Sales),0,RowNo())),
(Product,(=Sum({1} Sales),Desc))
))
Good luck in creating your Pareto dimension!
Further reading related to this topic:
- « Previous
- Next »
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.