Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Folder structure - Document Release Version
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Folder structure - Document Release Version
Hi,
I am in a bit of a mess with my folder structure, I have kind of followed Steve Dark structure based on the following link
http://www.quickintelligence.co.uk/qlikview-folder-structures/
But it is not exactly saying what files should be in where or if they are not providing a example file for each one and that is where I am trying to get my head around this.
So for example if I had the attached Qlikveiw Documents how would you cope with each scenario?
1. The three documents called Product.qvw, Purchase Orders.qvw and Sales.qvw generates a QVD for each one, which folder structure would I put this into?
2. I have a Document called "My First Qlikview Dashboard" which calls the qvd's that are created from point 1, where should I deploy this document to?
3. The Product.qvw, needs a new field called [Status Prefix], this is made up of the first letter of the field [Status] , as I am amending this Document what is the best cause of action with regards to a new version and then replacing the old file and then where do I put this previous version of the document?
4. The product.qvw is now required by a new Qlikview Dashboard Document "My Second Qlikview Dashboard" because the product.qvd is now used across multiple LIVE Documents should The Product.qvw/qvd be in a seperate Folder i.e. Globally?
Basically I need help with the full Qlikview Development/Deployment Lifecycle?
Also does anyone use Source Control? And which is the best one, I have heard there are issues with Variables not being saved etc...
Thanks
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Essential by my suggestion from above is to use a consistent data-architecture which splitted the task of creating a document into several sub-tasks with the aim to simplify and to standardize them into a so called ETL-process.
The first layer in this example is the generator which has the task to extract the data from sources and store them into qvd's without bigger adjustments, maybe some renaming of fields, here and there some formattings or roundings.
In the second layer are the datamodels in which the the data will be transformed in any way like filtered, aggregated, sorted and so on and then matched with other data-areas to build an associative datamodel.
Both layer didn't need a graphical surface which you would create within the third the report-layer. The reports loads then already created qvd's or another datamodel-qvw in a binary-load and provided then the views for the user (charts, listboxes and so on).
Now the question why - where are the benefits for it? The advantages are that you can reuse previous created work and data (you will need your core-data of products, sales hierarchy or a master-calendar in probably each report) and you will be able to develop, maintain and run all these parts quite independently from eachother.
Further I don't think that videos are a good medium for this - they could be very good as howto for small topics but the couldn't cover the variety and complexity what are possible data-architectures and which concept would be suitable for my case. Beside the links from above and many other valuable ressources here in the community I recommend to buy this and that book: Books and literature. For starters I would especially recommend:
QlikView 11 for Developers
Barry Harmsen und Miguel Garcia
ISBN-13: 978-1849686068
QlikView Your Business (December 2015)
Oleg Troyansky
ISBN-13: 978-1118949559
The main-focus of both isn't the data-architecture but they cover many very useful things for a beginner.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Ivan,
Implementation suggest by Steve is a good one but it also depends on the QV implementation within your firm.
A suggestion to categorize your QVW's based on the functionality they perform.
- QVW's which generates QVD's can be placed in one folder. again here we can sub categorize based on the usage, i.e. if its a global QVD generator you may have a global folder and then your stream specific folders
- One can have sub folders within DATA folder for specific streams
- Similarly for Data models and Dashboards we can sub categorize based on streams
Something as follows:
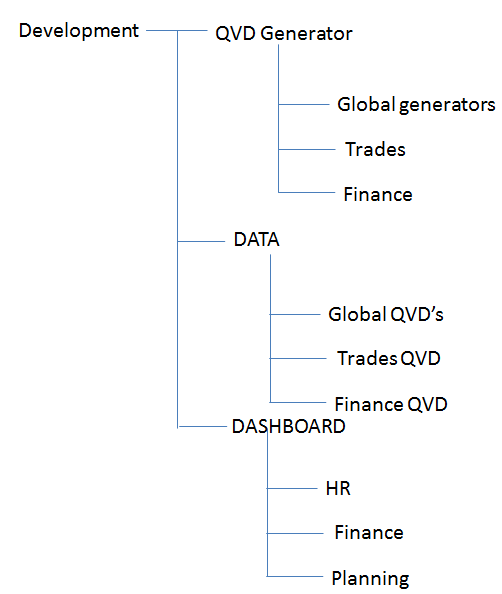
Follow similar approach in other folders as well
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Harshit,
Thanks for the reply, sorry for the late response, where would I put old versions of any amendments I do to a QVW? Say that a user wanted a new field, as per below point:
3. The Product.qvw, needs a new field called [Status Prefix], this is made up of the first letter of the field [Status] , as I am amending this Document what is the best cause of action with regards to a new version and then replacing the old file and then where do I put this previous version of the document?
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi do check this Doc,
PFA
Hirish
“Aspire to Inspire before we Expire!”
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Hirish,
I have looked at this document before, but I am still unsure where to keep old Documents that have had the script changed to it i.e if I make a change to a Document that creates a qvd where I need to add a new field to the script, do I make a copy of last document which had the old script? And where would I keep this incase i had to revert back to to previous changes if I deployed to production and something went wrong?
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Any Experts?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It will be depend on various facts which kind of folder-structure is suitable in your case. The above mentioned suggestion is definitely a good one and could be extended to a even more detailled structure to cover bigger deployments which have large numbers of users and applications across many areas of an enterprise with the possibility to separate those areas to certain servers or users (this could have for instance performance or legal reasons).
But if you just started and you would probaly have lesser then 100 user-reports in the next 3 - 4 years you could make it simpler, maybe in this way:
--> Generators
--> apps
--> qvd
--> log
--> others
--> Datamodels
--> apps
--> qvd
--> log
--> others
--> Reports
--> apps
--> qvd
--> log
--> others
which meant I recommend at least to use a 3-tier data-architecture. More informations could you also find here: More advanced topics of qlik datamodels
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marcus,
Thanks for the reply.
So with the example that you have provided, the four Qlikview Files I have provided where would you put these in?
i.e. In the Generators > Apps folder would I create three new folders as per below:
Sales - Where I would put the document "Sales.qvw"
Purchasing - Where I would put the document "Purchase Orders.qvw"
Global - Where I would put the document "Product.qvw" as this is not specific for a Department
Then in the the qvd folder would I have three new folders in there and call them Sales, Purchasing, Global?
I am just trying to visualise it? Also if I make a change to a Document by adding a new field, where would I keep a backup of old changes?
Confused dot com.
Ideally I want to follow the best practice, I know you have sent me links but for myself I actually need a video to show me my above scenarios as these are the examples I will go through and hard to maintain.
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Essential by my suggestion from above is to use a consistent data-architecture which splitted the task of creating a document into several sub-tasks with the aim to simplify and to standardize them into a so called ETL-process.
The first layer in this example is the generator which has the task to extract the data from sources and store them into qvd's without bigger adjustments, maybe some renaming of fields, here and there some formattings or roundings.
In the second layer are the datamodels in which the the data will be transformed in any way like filtered, aggregated, sorted and so on and then matched with other data-areas to build an associative datamodel.
Both layer didn't need a graphical surface which you would create within the third the report-layer. The reports loads then already created qvd's or another datamodel-qvw in a binary-load and provided then the views for the user (charts, listboxes and so on).
Now the question why - where are the benefits for it? The advantages are that you can reuse previous created work and data (you will need your core-data of products, sales hierarchy or a master-calendar in probably each report) and you will be able to develop, maintain and run all these parts quite independently from eachother.
Further I don't think that videos are a good medium for this - they could be very good as howto for small topics but the couldn't cover the variety and complexity what are possible data-architectures and which concept would be suitable for my case. Beside the links from above and many other valuable ressources here in the community I recommend to buy this and that book: Books and literature. For starters I would especially recommend:
QlikView 11 for Developers
Barry Harmsen und Miguel Garcia
ISBN-13: 978-1849686068
QlikView Your Business (December 2015)
Oleg Troyansky
ISBN-13: 978-1118949559
The main-focus of both isn't the data-architecture but they cover many very useful things for a beginner.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks i am still struggling but I will look at the books you have suggested