Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Data Integration
- :
- Products & Topics
- :
- Qlik Replicate
- :
- Re: Facing huge latency issues in my child tasks
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Facing huge latency issues in my child tasks
Hello All,
We are in the process of replicating 1200+ tables from an Oracle ERP source to target Oracle datawarehouse. Since there are huge number of tables, we decided to use the logstream and child task setup for it. We split the logstream tasks into 4 buckets of volume of changes that we get in a day (Low,High,Medium and temp). The tables in temporary will be sorted to the other 3 buckets at a later point in time. Also the child tasks are divided into 18, with 8 dedicated task having one table each for high volume, 6 task each for Low volume, 3 task for Medium volume and 1 for temporary.
So the logstream task is running fine with no latency. However I see there are about 5 child tasks that have extremely high latency. I see that there are changes being accumulated at the disk in the target, close to 220,991 transactions and 2654 transactions waiting until target commit. There are no updates happening on the table. Initially I could find the error in target_apply : "01984869: 2025-11-18T00:19:20 [TARGET_APPLY ]T: Failed to execute statement. Error is: ORA-20999: 0 rows affected ORA-06512: at line 1 ORA-06512: at line 1
~{AgAAACJPDXuDj7NuzKKZuhSA2i723IjjATLTcyL3ERn8+QUzNE8RMERqiUYA7kOMnOaX3Wc4W281UX8IYxudA3YrCAEVr5+i0nB5RsPT7yk48GiwfHqoQpYV7luwBuxIIyMYI5MFJmByPPt2Z2ZbsMlhESBsVz"
But after applying upsert mode in apply conflict tab, I see this error no longer exists, but now I see the below message in target_apply :
Got non-Insert change for table 200 that has no PK. Going to finish bulk since the Inserts in the current bulk exceeded the threshold
Could you please advise how can I resolve this issue?
I have attached the screenshot of the UI and also the task logs and DR package.
Can anyone help to fix this?
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If there are no PK's defined on the target table every update & delete operation will cause a full table scan which is exponentially slower.
Please define a primary key for these tables on the target.
Thanks,
Dana
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Dana,
Thanks a lot for your insights on this issue. However when I checked the source tables that we are replicating, which is about 1200+ tables and only very few tables have primary keys defined, but most of them have unique indexes present.
Could you please advise if adding these unique indexes at the target can help in improving the performance of the update/delete operations?
I tried adding unique indexes at the target for few tables and I could see that the latency reduced, however I just want to be 100 % sure before I can implement this as a solution for the rest of the child tasks.
Thanks a lot in advance for your advice on this.
Regards,
Harikesh OP
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello @harikesh_1991 , copy @Dana_Baldwin ,
You’re absolutely right — a unique index does help improve performance.
- If the table has a primary key, please will use that.
- If there’s no primary key but a single unique index exists, that unique index will be used.
- If there’s no primary key and multiple unique indexes exist, you can choose which one to use — otherwise, the first one (sorted alphabetically by name).
Hope this helps.
John.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello @john_wang/@Dana_Baldwin ,
Thanks a lot for your insights on this. I recently had 2 of my child task(CT_WH_ODW_STG_LV6 and CT_WH_ODW_STG_TMP having huge apply latency of more than 50+ hrs. When I checked the logs, I could find this message in the sorter :
2025-12-10T01:55:27:560657 [SORTER ]T: Apply is delayed. Forwarding events to target is postponed. (sorter_transaction.c:1131)
Hence I went through few Qlik documentations on troubleshooting the latency issues and then stopped the task and added the below in the more options present in task settings:
streamBufferSize : 100
streamBuffersNuumber: 20
And also increased the change processing tuning to:
Batch Tuning
Apply batched changes in intervals:
Longer than (seconds):300
But less than (seconds):400
Force apply a batch when processing memory exceeds (MB):1024
Transaction Offload Tuning
Offload transactions in progress to disk if:
Total transactions memory size exceeds (MB):5000
Transactions duration exceeds (seconds):6000
After adding this, I resumed the task and I could see that immediately the latency fell below 1 minute.
I also see the below in the logs:
03101643: 2025-12-10T05:17:17 [SORTER ]T: Begin sent to target. Forward txn Id 59994, Transaction id 000000000000000000000000001f0008. Target Id 886173 (sorter_transaction.c:2003) 03101643: 2025-12-10T05:17:17 [SORTER ]T: Commit sent to target after sending 221546 events. Forward txn Id 59994, Transaction id 000000000000000000000000001f0008. Last Target Id 8
Does this mean that the changes are getting applied at the target tables? Does it speed up the target apply ? Or do we still have to add the unique indexes at the target tables to improve the update/delete operations?
I did check the table at the target, but I still don't see updates in it for today's date.
Am I missing something here? Could you please advise?
I have attached the logs and screenshot of the dashboard.
Any pointers in the right direction would help a lot .
Thanks a lot in advance
Regards,
Harikesh OP
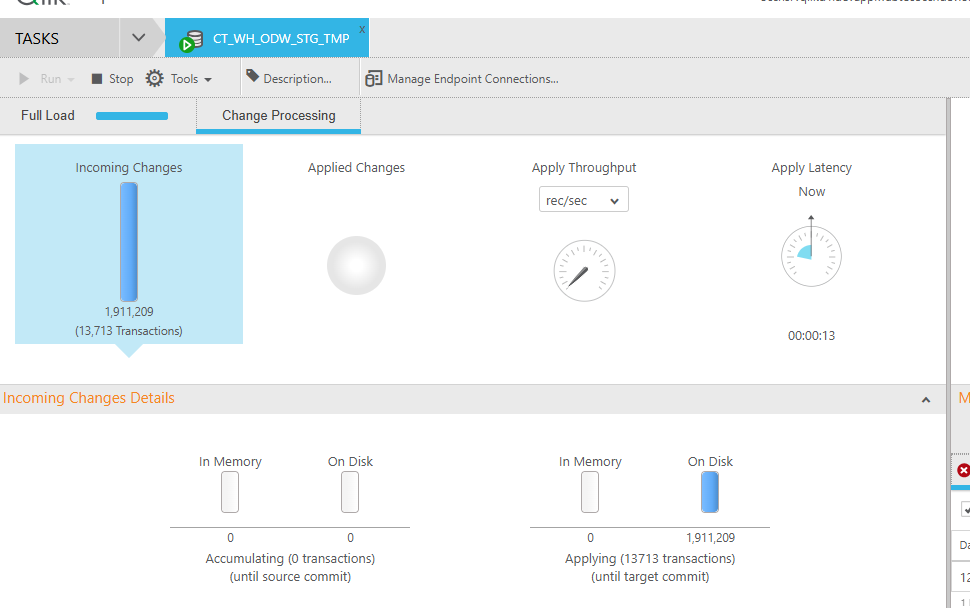{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The logs don't show any significant latency. There are no errors or warnings.
The stream buffer adjustments only help when you have LOB data in your tables.
The sorter entry indicates data is being sent to the target, but the target is not applying them efficiently or quickly as you still have many changes cached on disk waiting for the target to consume them.
No task setting can overcome issues of a full table scan on the target for updates & deletes if there is no primary key index or unique index on the tables. You can ask your target DBA to check if full table scans are happening on the target to confirm this - the issue is that an index provides the database a shortcut to the location of the relevant row of data on disk - without that, the database has to look at every row in the table until it finds the ones it needs - which is VERY slow, and slower the larger the table is.
Thanks,
Dana
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks @Dana_Baldwin and @john_wang for your insights on this. I stopped all my logstream tasks and child tasks and using a separate Full load pipeline, I did a full load for all the tables. Also created unique indexes for all the 1200+ tables.
But its been more than 5 days since I stopped my logstream task. When I resumed the logstream task, I get the below error:
01426748: 2025-12-18T00:59:20 [TASK_MANAGER ]I: Task error notification received from subtask 0, thread 0, status 1020401 (replicationtask.c:3652)
01426748: 2025-12-18T00:59:21 [TASK_MANAGER ]W: Task 'LS_TSK_WH_ODW_STG_HV' encountered a fatal error (repository.c:6536)
01426788: 2025-12-18T00:59:20 [SOURCE_CAPTURE ]E: Archived Redo log for the sequence '623' does not exist, thread 4 [1022318] (oradcdc_thread.c:765)
01426788: 2025-12-18T00:59:20 [SOURCE_CAPTURE ]E: Failed to set stream position on context '00000ff3.b60ceab6.00000004.0001.00.0000:623.4366208.16' [1020401] (oracdc_merger.c:949)
01426788: 2025-12-18T00:59:20 [SOURCE_CAPTURE ]E: Error executing command [1020401] (streamcomponent.c:2060)
01426788: 2025-12-18T00:59:20 [TASK_MANAGER ]E: Stream component failed at subtask 0, component st_0_SRC_WH_STG [1020401] (subtask.c:1512)
01426788: 2025-12-18T00:59:20 [SOURCE_CAPTURE ]E: Stream component 'st_0_SRC_WH_STG' terminated [1020401] (subtask.c:1683)
01426790: 2025-12-18T00:59:21 [SORTER ]I: Final saved task state. Stream position 00000ff3.b60ceab6.00000004.0001.00.0000:623.4366208.16, Source id 266546839, next Target id 6377749, confirmed Target id 6377745, last source timestamp 1765517722000000 (sorter.c:774)
Any idea on how to start my logstream task?
Also how do I start my child tasks? Do I have to resume it or go to advance run option and start the child tasks from the point when the full load was completed?
Any advise on this would be immensely helpful for me to continue my development.
Thanks a lot in advance for your advise on this.
Regards,
Harikesh OP
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No need to use a separate task to reload, you can use the log stream tasks for this as well. No harm either though.
Because the task was down for so many days, the source archived logs needed to resume from where the parent task left off have already been purged by Oracle based on your RMAN / backup strategy. Please make sure the archive logs are not purged too quickly so that you have more recovery options in case you run into issues going forward.
Because you performed a full load, you do not need to start from the point of time when the task was stopped. You can start the parent task from a timestamp corresponding to just before you performed the full load. While the task catches up, there might be duplicate record constraints encountered that may slow the task down, as some of the inserts that occurred during the time the full load ran may already be on the target tables.
Once the parent task is started and running, start the child tasks from a timestamp the same or a minute later than you used to start the parent task. This way you ensure that they start to read from the new timeline folder that the parent task created when you started it from timestamp.
Depending on how far back you ran the full load, the archived logs on the source will need to still be available for the timestamp you use to start the task. If not, they will need to be restored and re-registered with the database, or you can perform another full load for the parent and child tasks.
Thanks,
Dana