Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Data Integration
- :
- Products & Topics
- :
- Qlik Replicate
- :
- Replicate data with dynamic query
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Replicate data with dynamic query
Hi
Now we are replicating data from oracle db onpremise to Mysql AWS RDS.
So, we have several tables with years of data and we want to replicate in a FULL MODE load only the last "x" years.
We don't want to put the date in "hard code" on table option (filter) so we want to use any kind of function to get the results described on the line up.
please, your help.
regards
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
thank you all of you.
Hein, thank you for your response and advices. Will take in count for future help.
Let me comment my case.
We clic CTRL on the table and the double clic as per you said, the Passthru appears but after we try to reload the table shows us an error describing that we must to add the parameter on the config file, but we are afraid to do that, and the question is:
¿although we will put those parameter on the config file, no one table will be affect unless we put something on the PASSTHRU on that table?
Thank you again to both.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @wguerrero
Yes that is correct. Enabling the pass through filter will only affect tables that have a filter specified.
Regards,
Dana
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
thank you for your answers, Hein and Dana.
Hein, we have setup with CTRL + clic on the table on the text box you described. But when we just clic on RUN it shows us a message about we have to put the parameter on CFG file, but we are afraid that something happens with our another tasks.
But we have setup a workaround, (please check the attached), this action works well and send the data to the target without any problem. But we want to know what is your opinion about this method.
Please, your kindly help.
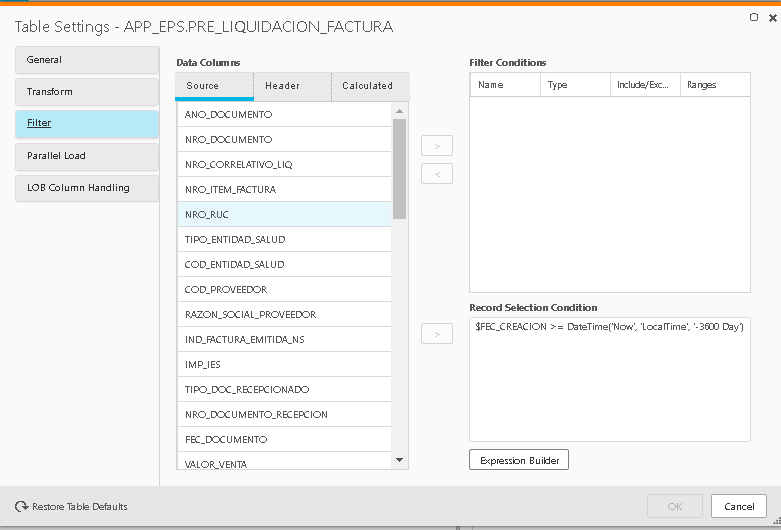{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The issue with the workaround using a 'normal' filter action is the the row needs to be transferred to Replicate for it to decide. If 1 in a 100 rows is filtered out then that's fine. If 99 out of each 100 rows are filtered out then that could be a huge waste of resources. If the total resources used are minimal or dirt cheap than go ahead, but if the reources used are expensive/slow, then there is a point where you really want the filtering to be pushed down to the source such that no needles rows are pushed over the network and handled by Replicate. The Replicate level filtering would still be great for 'tweaking', final filters. Getting rid of more most rows to be filtered (more than 30% of all for example) is obviously best done on the source. The source might even have a index to help, avoiding reading rows which are not needed. Not important for 100 rows, critical for 100 million rows.
Hein.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
ok Thank you.
We will take in count your advice.
regards
- « Previous Replies
-
- 1
- 2
- Next Replies »