Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Association based on a range of values possibl...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Association based on a range of values possible ?
Hi,
We have a requirement to join the hiring information from two HR data sets. The only possible key would be a combination of employee_id and hiring date which I call %HiringKey. This approach works for 85% of the cases. But for 15%, the hiring date in both systems vary by 1-2 days since the source teams for these systems operate and report separately and there would sometimes be a delay in entering the information to the systems.
Let me take an example to explain such a scenario:
In data set A, we have employee_Id=1234 and hiring date as 07/01/2015. So the key generated would be 1234-07/01/2015
In date set B, we have the same transaction for employee id 1234 but the hiring date is slightly different as 07/02/2015. The key thus generated would be 1234-07/02/2015. And since these keys doesn't match, the required association is lost for this record between the systems.
Is there anything that we can do at qlikview side so that an association is made if the dates at either side falls within a range plus or minus 10 days. Because, the scenario where same employee having hired twice within a 20 day period was ruled out by the business team.
Please let me know your thoughts.
Regards,
Vishnu S
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You could round the date to the nearest 20 of the date value. So the key would then be
employee_Id & '-' & Date(Round([hiring date], 20))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try to create one mapping table using Emp_id and joining date from first set.
Now do applymap for the second data set, based so for the emp id joining date will be changed.
In general,I think data should be correct at source level only.
Because joining date should be same, no matter from where the data was coming 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You could round the date to the nearest 20 of the date value. So the key would then be
employee_Id & '-' & Date(Round([hiring date], 20))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
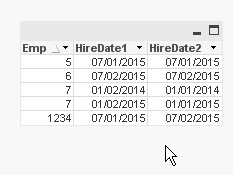
I think you can join (full outer) the 2 tables and then check the hire date difference
SET DateFormat='MM/DD/YYYY';
DS1:
load * inline [
Emp, HireDate1
1234, 07/01/2015
5, 07/01/2015
6, 07/02/2015
7, 01/02/2014
7, 01/02/2015
];
DS2:
load * inline [
Emp, HireDate2
1234, 07/02/2015
5, 07/01/2015
6, 07/02/2015
7, 01/01/2014
7, 01/01/2015
];
join (DS1) load * Resident DS2;
DS1Final:
NoConcatenate load
*
Resident DS1
where fabs(HireDate2-HireDate1)<=10;
DROP Table DS1;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks all.
I found the solution by Jonathan most fitting in my scenario.
When I did a employee_Id & '-' & Date(Round([hiring date], 20)), there were still a couple of similar dates which fell in different 20' bucket and missed the join. Since I was using this in an applymap, in the null condition parameter I included one more similar join, this time with a range of 10.So the missed out joins in the first attempt made sure to join correctly in the second.