Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Clean and Filter unstructured text box
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Clean and Filter unstructured text box
Hello My Qlik Friends,
I have a data source to work with that doesn't exactly conform to Codd's Rules. To make things worse, it's been modified over time. Never the less, I'm working with what I have. I have a field that contains a "WorkGroup". It's a free text field that may contain notes embedded in the same field. It also may contain multiple WorkGroups separated by CRLF codes. My goal is to normalize as much as possible, and extract the first conforming WorkGroup from the first line, without any other extraneous characters.
In the Script, I have used variations of the following code (this example is the last variation prior to publishing this request):
If(index([Affected Workgroup], ' ')>0, KeepChar(Upper(Left([Affected Workgroup],index([Affected Workgroup], ' '))), '_ABCDEFGHIJKLMNOPQRSTUVWXYZ'),
If(index([Affected Workgroup], Chr(13))>0, KeepChar(Upper(Left([Affected Workgroup],index([Affected Workgroup], Chr(13)-1))), '_ABCDEFGHIJKLMNOPQRSTUVWXYZ'),
If(index([Affected Workgroup], Chr(10))>0, KeepChar(Upper(Left([Affected Workgroup],index([Affected Workgroup], Chr(10)-2))), '_ABCDEFGHIJKLMNOPQRSTUVWXYZ'),
If(index([Affected Workgroup], '(')>0, KeepChar(Upper(Left([Affected Workgroup],index([Affected Workgroup], '(')-1)), '_ABCDEFGHIJKLMNOPQRSTUVWXYZ'),
Upper(KeepChar([Affected Workgroup], '_ABCDEFGHIJKLMNOPQRSTUVWXYZ')))))) As AffectedWG_Clean,
The input data looks like this:
| Header 1 |
|---|
| AAG_PAPCARE_CUSTSVC_PHN (6 in customer follow-up, 1 in coaching, 1 in a meeting, 1 ACW extended) |
AAG_PAPCARE_CUSTSVC_PHN 4 agents in project 4 agents cust follow-up status 3 agents coaching status 6 agents ACW extended status |
AAG_PAPCARE_CUSTSVC_PHN AAG_PAPCARE_GOLD_PHN |
| AAG_PAPCARE_DIAMOND_PHN |
| AAG_PAPCARE_CUSTSVC_PHN (2 agents in project) |
When I drop the multi-line examples into Notepad++, I get the following:

The problem I'm solving for today, and I'm hoping one of you can point me in the right direction is this: when I run the code (in the above example) against the data shown here, for those lines where there are double sets of CRLF (Multi-line with spaces in between), I get this: AAG_PAPCARE_DIAMOND_PHNAAG_PAPCARE_QBOA_DIAMOND_PHN a concatenation of the first 2 lines rather than simply taking the characters to the Left() of the CRLF.
To be clear, in the above example, all I need is the value of the very first line, nothing else. I hope I've explained this well enough. If not, I'm happy to supply any further information necessary.
Thank you for reading this and special Kudo's for supplying any clues.
Cheers~!
Matthew Cummings
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You could try a replace statement on chr(13) and chr(10) to remove the tricky characters?
Steve
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would try changing the settings on the file import wizard, so that CR/LF are treated as new lines, picking different character sets or delimiters may cause this to work.
You can then treat each line independently and parse it.
Good luck!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Steve,
I connect to the source using an ODBC connection. I'm also new to QlikView. I took a look at the "Connect..." options and but didn't find any options that sounded like they would bring about the result you suggested.
Can you be more specific or is that option only available for Data Files?
Thank you for your response 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Matthew,
In order to load in a flat file your best bet is to use the Table Files button. Once you have selected the source file in there (you may need to change the drop down from All Data Files to All Files if your file extension is not recognised) you will be given a number of options about how to read the file in.
As the data are unstructured you may find that reading it in with no embedded header, as a fixed width file with no boundaries, then gives you the best ability to parse the file using the load script.
Apologies if my previous response confused, but I had assumed you were already using the Table Files button.
Cheers,
Steve
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Steve,
I appreciate the time you're taking to respond. But, I'm using an ODBC connection to a data provider called Quickbase. Think of it like an Access DB but SAAS.
No flatfiles, no Excel, just an old timey ODBC connection with fewer options and not much of a wizard. I used Table Files to create the prototype and didn't have these problems but now, switching to a direct ODBC connection, I find the data coming from the back end is different than what comes out the front end in the form of .csv files. This difference is what's causing me grief, such as the CRLF hidden characters described in my original post.
Any other suggestions would be appreciated.
Cheers~!
mfc
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You could try a replace statement on chr(13) and chr(10) to remove the tricky characters?
Steve
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Steve,
Ultimately, the Replace() function worked! I could not get either Index() nor Replace() to recognize Chr(13) (CR), although Notepad++ recognized the CR code (see screen shot above), this turned out to be a major source of confusion. Then I dropped the snippet into a Hex Editor which revealed the hex values OD OA.
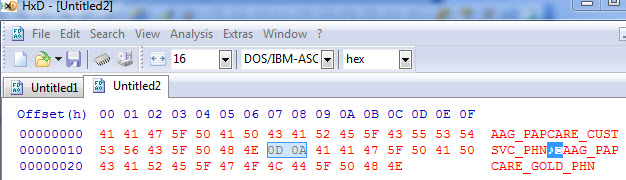
Now that I know there is no CR and only LF, I knew the path I needed to be on. It took further manipulation and toying with replacement values but I found the bar '|' worked where space ' ' didn't. I'm learning a lot about working with hidden characters so this was a good exercise.
Thank you for your help Sir! 
Matthew Cummings