Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Count amount of duplications/COUNTIFS for column
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Count amount of duplications/COUNTIFS for column
Hello All,
I am trying to find amount of duplications within a database, based on certain columns.
Below is a sample of the data I have:
- ID, VednorCode, ItemName is the raw data.
- Duplications is what I am trying to get (In Yellow)
| ID | VendorCode | ItemName | Duplications |
| 1 | H90042800 | 6251 | 3 |
| 2 | H90042800 | 6251 | 3 |
| 3 | H90042800 | 6251 | 3 |
| 4 | H90042800 | PD-6251-300 | 2 |
| 5 | H90042800 | PD-6251-300 | 2 |
| 6 | H90042800 | PD-6252-300 | 1 |
| 7 | H03000773 | PD-6252-300 | 1 |
| 8 | H03000773 | PD-6011-300 | 3 |
| 9 | H03000773 | PD-6011-300 | 3 |
| 10 | H03000773 | PD-6011-300 | 3 |
Duplications should show the total amount of times each combination of VednorCode and ItemName appears.
Duplications amount in each line refers to VendorCode and ItemName in the same line.
Basically, it is the same as if I would use COUNTIFS(B:B,$B2,C:C,$C2) in excel.
Any ideas?
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Why 1, 1 for Item code of PD-6252-300 ?? I am assuming, It would be 2, 2
Count(TOTAL <ItemName> ItemName)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
May be like this
Count(TOTAL <VendorCode, ItemName> ID)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Anil,
It is 1,1 because the VendorCode is different.
I want to count the amount of times each unique combination VednorCode and ItemName appears.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sample attached
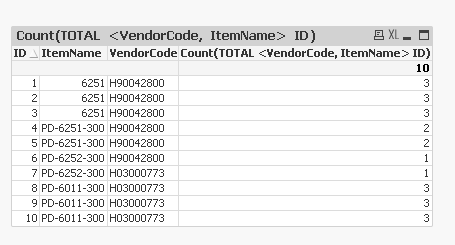
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
After that, I came to know
Count(TOTAL <VendorCode,ItemName> ItemName)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Many thanks Sunny and Anil