Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Dealing with identical rows of data
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dealing with identical rows of data
Hoping someone could help answer this query and hopefully suggest a possible solution for an issue I think I'm having...
My source data looks like this:
| Name | Age | Favourite colour |
|---|---|---|
| John | 30 | Blue |
| John | 30 | Blue |
| Sarah | 41 | Yellow |
| Malcolm | 28 | Green |
| Malcolm | 24 | Green |
And my load statement is simply:
LOAD
Name,
Age,
[Favourite colour]
From....
Firstly, how will QV deal with the first 2 rows when loaded in? They are identical, so will QV load them both, or automatically combine them into just one row. I.e. If I did a count of 'Names' (but not distinct names) would John be included once or twice?
Secondly, how can I avoid the issue in the last two rows? If there is ever a case in the data (such as this) where the row is identical expect for the 'Age' field, I want to keep the row with the youngest age and remove the other row.
I would prefer to do this manually. I.e. I would like to flag it up somehow in a table so that I can sort it out in the original data source.
So far, I have tried creating a straight table using all three dimensions and then as an expression:
IF(COUNT(Name&[Favourite colour]>1),'Duplicate entry')
But this doesn't seem to be working for me...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Have you tried LOAD DISTINCT? That would address the first issue, but not the last one. barryharmsen has a good article on this - http://www.qlikfix.com/2013/07/30/distinct-can-be-deceiving/. May need last name, to make the "key" more selective.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
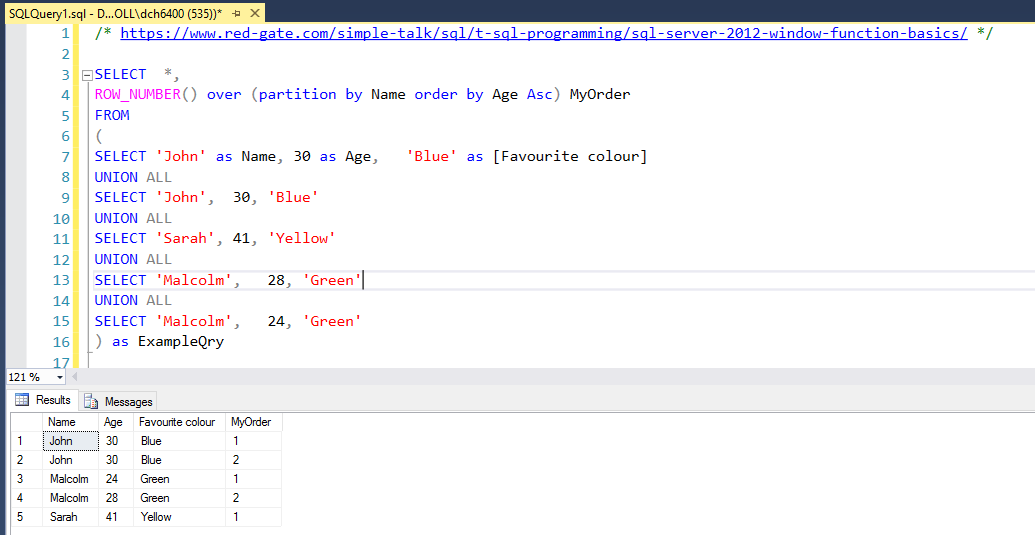 SELECT *,
SELECT *,
ROW_NUMBER() over (partition by Name order by Age Desc) MyOrder
FROM
(
SELECT 'John' as Name, 30 as Age, 'Blue' as [Favourite colour]
UNION ALL
SELECT 'John', 30, 'Blue'
UNION ALL
SELECT 'Sarah', 41, 'Yellow'
UNION ALL
SELECT 'Malcolm', 28, 'Green'
UNION ALL
SELECT 'Malcolm', 24, 'Green'
) as ExampleQry
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jessica,
I'd try something like this:
Map_LastRecord:
Mapping LOAD
Name&'|'&MaxAge,
1
;
LOAD
Name,
Max(Age) as MaxAge
Group By
Name
;
LOAD * INLINE [
Name, Age, Favourite colour
John, 30, Blue
John, 30, Blue
Sarah, 41, Yellow
Malcolm, 28, Green
Malcolm , 24, Green
];
LOAD
RowNo(),
ApplyMap('Map_LastRecord', Name&'|'&Age, 0) as LastRecord,
*
INLINE [
Name, Age, Favourite colour
John, 30, Blue
John, 30, Blue
Sarah, 41, Yellow
Malcolm, 28, Green
Malcolm , 24, Green
];
EXIT Script;
In the table use
If(Count(TOTAL <Name> Name&[Favourite colour])>1, 'Duplicate entry', 'OK')
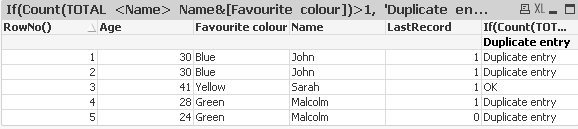
Hope this helps.
Juraj
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In the example above, you can use the MyOrder field as a flag in your set analysis MyOrder={1}. This particular example is for SQL Server 2012 and uses proprietary TSQL functions. However this style solution can be tweaked as needed depending on your data source. I suspect it can be written in the qlik load portion of the script as well (in a slightly different syntax).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think an approach like this: Re: How to flag Duplicate records in Script might be helpful.
- Marcus