Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Help with normalization of table.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Help with normalization of table.
Hi,
I am a big subscriber to denormalization in QlikView and appreciate the performance advantages of using denormalized tables.
HOWEVER in my case I am dealing with transactional data which runs into millions of records and I am trying to "compact" my data model as much as I can because we are hitting performance issues.
Below is a small extract (changed the names for simplicity) from a very large file (i.e.many fields) - many of the fields are text (long strings). In the example "DeclineReason" is down to about 10 variants (obviously the data creator is picking from a pick list) - same with "CardNetwork" - when you multiply these by 10s of millions you have a lot of data duplication.
I wish to remove these fields from the Auth table and reference them using a numeric key. I started by LOAD DISTINCT these fields (see below) but I am stuck on how to replace the string field with a numeric key in my final transactional table (Auth)
Any help would be appreciated.
Alexis
Auth_tmp:
LOAD MerchantID,
TerminalID,
AuthorisationDate
Amount,
DeclineReason,
CardNetwork
....
FROM <somedatasource>...
DeclineReasons:
LOAD DISTINCT
DeclineReason As DeclineReasonDesc,
AutoNumber(DeclineReason) As DeclineReasonDesc_KEY
RESIDENT Auth_tmp;
CardNetworks:
LOAD DISTINCT
CardNetwork As CardNetworkName,
AutoNumber(CardNetwork) As CardNetworkName_KEY
RESIDENT Auth_tmp;
Auth:
LOAD MerchantID,
TerminalID,
AuthorisationDate
Amount,
...
NO CONCATENATE
RESIDENT Auth_tmp;
// I guess I need to DROP FIELDS DeclineReason and CardNetwork here etc..
DROP TABLE Auth_tmp;
- Tags:
- normalization
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I probably would add a qualifier to the Autonumber like
AutoNumber(DeclineReason, 'Decline')
I think it should be enough to use the same code in the Auth table then:
Auth:
NOCONATENATE
LOAD MerchantID,
TerminalID,
AuthorisationDate
Amount,
Autonumber(DeclineReason, 'Decline') as DeclineReasonDesc_KEY,
...
RESIDENT Auth_tmp;
No reason to drop fields if you leave them out already in your resident load.
But I wonder if this would make any real difference, since in your original Auth table, the values are not stored as strings, but as bit stuffed pointer to the symbol table. I think you won't gain anything.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Alexis,
Can you post a snapshot sample of your data model here?
Regards,
MB
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I probably would add a qualifier to the Autonumber like
AutoNumber(DeclineReason, 'Decline')
I think it should be enough to use the same code in the Auth table then:
Auth:
NOCONATENATE
LOAD MerchantID,
TerminalID,
AuthorisationDate
Amount,
Autonumber(DeclineReason, 'Decline') as DeclineReasonDesc_KEY,
...
RESIDENT Auth_tmp;
No reason to drop fields if you leave them out already in your resident load.
But I wonder if this would make any real difference, since in your original Auth table, the values are not stored as strings, but as bit stuffed pointer to the symbol table. I think you won't gain anything.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Braga
Thanks for responding.
In the context of this example I don't have a data model - it is a SINGLE table (I called it "auth_tmp") in the example and I simply wish to remove long, repeated string fields (DeclineReason and CardNetwork) and put them in separate tables "DeclineReasons" and "CardNetworks" in the example, and link with then using a numeric key...
Any assistance would be appreciated
Alexis
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From the script you have posted I can see no reason to create the DeclineReasons, CardNetworks and Auth tables as that seems to be just normalizing a table into multiple tables that is already denormalized in a single table.
As suggested earlier could you share your Data Model and that may make understanding easier.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
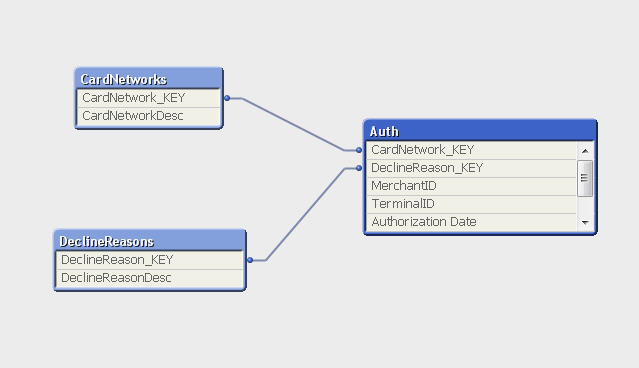
Hi Bill and Braga
Here is the schema I ended up with with swuehl's help. As stated this part of the puzzle is just a SINGLE table with a lot of repeated, duplicated text fields which I wanted to remove to make my main table as small as possible as I do a lot of calculations, aggregations, comparative analysis.
As swuehl seems to suggest, maybe this is a fruitless exercise as QlikView is "clever" enough to detect all the duplications and uses bit-stuffed pointers to the symbol table. I'll test it both ways (normalised and denormalised) and see if it makes a difference.
Thanks
Alexis
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi swuehl,
Thanks for your reply - as I stated in my reply to Bill, I am trying to "optimise" my application (it's many time more complex than my example 🙂 ) and I had assumed that the millions of repeated strings might not be helping but as you state maybe I'm wasting my time looking in this direction as QlikView detects this and uses pointers to a symbol table for optimisation...
Thanks again
alexis
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If fields DeclineReason and CardNetwork have only few distinct values, there is no benefit to move them to separate table (normalize). You will not save any space or gain performance. More info: Symbol Tables and Bit-Stuffed Pointers
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Saulius that was very helpful. I will look elsewhere for my optimisation!
rgds
Alexis