Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: How to find duplicated values within time inte...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How to find duplicated values within time intervals
Hi
I have a database with the registry of people from a food service. The food service is free, but because the POS has some troubles, sometimes the records are duplicated (i.e. there are two transactions with a difference of 30 seconds, or sometimes max. 2 minutes) .
I need to find record that are duplicated and mark them (Both, the correct and the duplicated!.
What i Have is something like:
1 Person1 Food1 12/05/2014 11:01:00 NEED TO HAVE A MARK (Duplicated)
2 Person1 Food1 12/05/2014 11:01:30 NEED TO HAVE A MARK (Duplicated)
3 Person1 Food2 12/05/2014 12:00:30
4 Person2 Food1 12/05/2014 11:01:20
5 Person2 Food2 12/05/2014 11:01:30
n ...
Mark the registry 2 is (I think..) not a big deal, cause I can use Peek or Previous.. But how do I mark the registry 1?
So in this example, I have to mark the registry 1 and 2, because it is from the same person, same food and in the same day.
I need to have at least two-three Marks, depending the time difference between the registers.
i.e One mark if the difference of time is less than 30 seconds
One mark if the difference of time is less than 2 minutes.. and so on
Thank you!!
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Cristian
It sounds like you want to achieve a result something like this:
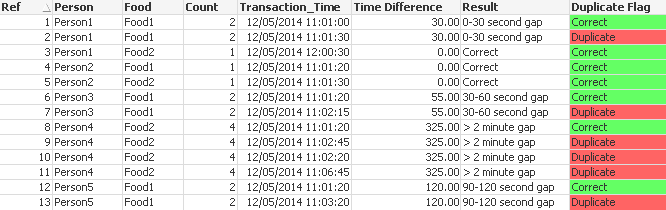
The script below works by counting the number of distinct entries against each combination of person and food. For it to work your data must have a unique key for each Person/Food combination. I achieved this in the example by creating a composite key from your Person and Food fields but in your real data you may have to find something that will offer uniqueness as I imagine there will be more than one Mr or Mrs X having food Y. However, hopefully this example will demonstrate a principle by which you could solve your issue. Of course if your Person and Food fields do generate a unique key for each Person/Food combination then the script will work for you.
The basic steps are:
- Load your data
- Create a composite key to provide unique combinations of Person and Food
- Using the composite key count the number of unique records per key
- Calculate the earliest and latest transaction times then use these to calculate the time difference.
(I have converted the time difference to seconds for simplicity) - Identify the first record for each key and mark it as 'Correct'
- Identify the duplicate records for each key and flag them as 'Duplicate'
- Create the time intervals dimension
- Create a straight table to display the results
I have added a little more test data to the inline load and have included one example where there are multiple duplicate entries so you can see how the script handles such a scenario.
Copy the script below into the script editor then save and reload your application.
Data:
load * inline [
Ref,Person,Food,Transaction_Time
1, Person1, Food1, 12/05/2014 11:01:00
2, Person1, Food1, 12/05/2014 11:01:30
3, Person1, Food2, 12/05/2014 12:00:30
4, Person2, Food1, 12/05/2014 11:01:20
5, Person2, Food2, 12/05/2014 11:01:30
6, Person3, Food1, 12/05/2014 11:01:20
7, Person3, Food1, 12/05/2014 11:02:15
8, Person4, Food2, 12/05/2014 11:01:20
9, Person4, Food2, 12/05/2014 11:02:45
10, Person4, Food2, 12/05/2014 11:02:20
11, Person4, Food2, 12/05/2014 11:06:45
12, Person5, Food1, 12/05/2014 11:01:20
13, Person5, Food1, 12/05/2014 11:03:20
];
left join(Data)
Load
Ref,
Person & Food as KEY
Resident Data ;
left join(Data)
Load
Person & Food as KEY,
Count (Distinct Ref & Transaction_Time) as COUNT_OF_RECORDS,
Min(Transaction_Time) as EARLIEST_TIME,
Max(Transaction_Time) as LATEST_TIME,
Round(((Max(Transaction_Time)-Min(Transaction_Time))*86400),1) as TIME_DIFFERENCE
Resident Data
Group By Person & Food ;
left join(Data)
Load
Ref,
If(Transaction_Time=EARLIEST_TIME,'Correct',
If(COUNT_OF_RECORDS>1 and Transaction_Time>EARLIEST_TIME,'Duplicate',
'Check')) as DUPLICATE_IDENTIFIER
Resident Data;
left join(Data)
Load
Ref,
If(TIME_DIFFERENCE=0,'Correct',
If(TIME_DIFFERENCE>0 and TIME_DIFFERENCE<=30,'0-30 second gap',
If(TIME_DIFFERENCE>30 and TIME_DIFFERENCE<=60,'30-60 second gap',
If(TIME_DIFFERENCE>60 and TIME_DIFFERENCE<=90,'60-90 second gap',
If(TIME_DIFFERENCE>90 and TIME_DIFFERENCE<=120,'90-120 second gap',
If(TIME_DIFFERENCE>120,'> 2 minute gap')))))) as RESULT_FLAG
Resident Data;
Hope that helps.
Kind regards
Steve
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Cristian
It sounds like you want to achieve a result something like this:
The script below works by counting the number of distinct entries against each combination of person and food. For it to work your data must have a unique key for each Person/Food combination. I achieved this in the example by creating a composite key from your Person and Food fields but in your real data you may have to find something that will offer uniqueness as I imagine there will be more than one Mr or Mrs X having food Y. However, hopefully this example will demonstrate a principle by which you could solve your issue. Of course if your Person and Food fields do generate a unique key for each Person/Food combination then the script will work for you.
The basic steps are:
- Load your data
- Create a composite key to provide unique combinations of Person and Food
- Using the composite key count the number of unique records per key
- Calculate the earliest and latest transaction times then use these to calculate the time difference.
(I have converted the time difference to seconds for simplicity) - Identify the first record for each key and mark it as 'Correct'
- Identify the duplicate records for each key and flag them as 'Duplicate'
- Create the time intervals dimension
- Create a straight table to display the results
I have added a little more test data to the inline load and have included one example where there are multiple duplicate entries so you can see how the script handles such a scenario.
Copy the script below into the script editor then save and reload your application.
Data:
load * inline [
Ref,Person,Food,Transaction_Time
1, Person1, Food1, 12/05/2014 11:01:00
2, Person1, Food1, 12/05/2014 11:01:30
3, Person1, Food2, 12/05/2014 12:00:30
4, Person2, Food1, 12/05/2014 11:01:20
5, Person2, Food2, 12/05/2014 11:01:30
6, Person3, Food1, 12/05/2014 11:01:20
7, Person3, Food1, 12/05/2014 11:02:15
8, Person4, Food2, 12/05/2014 11:01:20
9, Person4, Food2, 12/05/2014 11:02:45
10, Person4, Food2, 12/05/2014 11:02:20
11, Person4, Food2, 12/05/2014 11:06:45
12, Person5, Food1, 12/05/2014 11:01:20
13, Person5, Food1, 12/05/2014 11:03:20
];
left join(Data)
Load
Ref,
Person & Food as KEY
Resident Data ;
left join(Data)
Load
Person & Food as KEY,
Count (Distinct Ref & Transaction_Time) as COUNT_OF_RECORDS,
Min(Transaction_Time) as EARLIEST_TIME,
Max(Transaction_Time) as LATEST_TIME,
Round(((Max(Transaction_Time)-Min(Transaction_Time))*86400),1) as TIME_DIFFERENCE
Resident Data
Group By Person & Food ;
left join(Data)
Load
Ref,
If(Transaction_Time=EARLIEST_TIME,'Correct',
If(COUNT_OF_RECORDS>1 and Transaction_Time>EARLIEST_TIME,'Duplicate',
'Check')) as DUPLICATE_IDENTIFIER
Resident Data;
left join(Data)
Load
Ref,
If(TIME_DIFFERENCE=0,'Correct',
If(TIME_DIFFERENCE>0 and TIME_DIFFERENCE<=30,'0-30 second gap',
If(TIME_DIFFERENCE>30 and TIME_DIFFERENCE<=60,'30-60 second gap',
If(TIME_DIFFERENCE>60 and TIME_DIFFERENCE<=90,'60-90 second gap',
If(TIME_DIFFERENCE>90 and TIME_DIFFERENCE<=120,'90-120 second gap',
If(TIME_DIFFERENCE>120,'> 2 minute gap')))))) as RESULT_FLAG
Resident Data;
Hope that helps.
Kind regards
Steve
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Steve!
It worked perfect
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Cristian
You're welcome. Glad it helped. Thanks for marking my answer as correct.
Steve