Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Is this a bug with the new outer set analysis ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is this a bug with the new outer set analysis syntax?
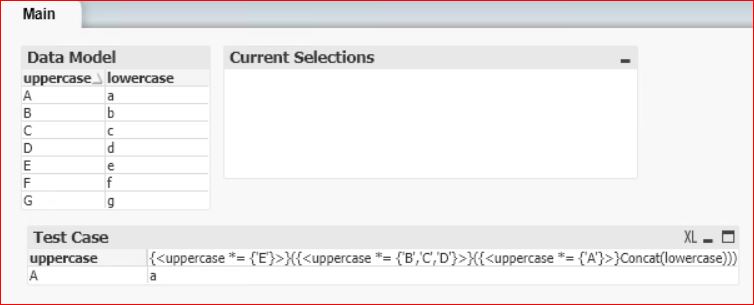
It doesn't seem like this should return a (see screenshot).
{<uppercase *= {'E'}>}({<uppercase *= {'B','C','D'}>}({<uppercase *= {'A'}>}Concat(lowercase)))
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I respectfully disagree. If what you are saying is true, then the following should return 'a', but it returns blank:
{<uppercase *= {'A','X'}>}({<uppercase *= {'E','X'}>}({<uppercase *= {'B','C','D','X'}>}({<uppercase *= {'A','X'}>}Concat(lowercase))))
or why does this also return blank and not all results?
{<uppercase *= {'E'}>}({<uppercase *= {'B','C','D'}>}Concat(lowercase))
The above 2 results contradict your conclusion that "With the first two steps you get an empty set of field values for the selection. That means that all values are possible for the field 'uppercase' in the third step." A null set (set of no values) is not equivalent to the set of all values.
What I am saying is that the inheritance appears to be bugged. What you are suggesting is to not use inheritance, and while that works, it does not answer the question of whether or not inheritance is bugged. There are definitely ways of writing the expression to not use inheritance in the outer set or not using outer sets all together, but those features are not where I am seeing unexplained behavior.
Your example works because the inheritance issue appears to happen to set analysis after the null set happens.
{<Location *={'Canada'}>}
({<Department *= {'Groceries'}>}(ALT(SUM(Sales)/SUM(Cost),1)-1) * 0.6)
+ ({<Department *= {'Pharmacy'}>}(ALT(SUM(Sales)/SUM(Cost),1)-1)*0.4)
The issue is highlighed when you add a set after the null set, which breaks it (when selecting one department).
{<Location *={'Canada'}>}
({<Department *= {'Groceries'}>}({<Location *={'Canada'}>}ALT(SUM(Sales)/SUM(Cost),1)-1) * 0.6)
+ ({<Department *= {'Pharmacy'}>}({<Location *={'Canada'}>}ALT(SUM(Sales)/SUM(Cost),1)-1)*0.4)
These are all using *=, so there is no reason for <set1>(<set2>sum(...)) to work and <set1>(<set2>(<set1>sum(...))) to not work. They look mathematically equivalent to me. This is pretty much the same notation as what is used in the help text on inheritance.
I can give more examples... Why does the following return different results with no selections? (10% for the 1st one and 20% for the 2nd one)
({<Department *= {'Groceries'}>} ({<Location *= {'Canada'}>}(ALT(SUM(Sales)/SUM(Cost),1)-1)))
({<Department *= {'Groceries'}>*<Location *= {'Canada'}>} ({<Location *= {'Canada'}>}(ALT(SUM(Sales)/SUM(Cost),1)-1)))
This following expressions are returning 240, which is sum of sales in all departments. It doesn't even have a null set at any step of the inheritance. There appears to be no proper inheritance at all happening.
({<Department *= {'Groceries'}>*<Location *= {'Canada'}>} ({<Location *={'Canada'}>}SUM(Sales)))
({<Department *= {'Groceries'}>*<Location *= {'Canada'}>} ({<Sales *={"*"}>}SUM(Sales)))
({<Department *= {'Groceries'}>*<Location *= {'Canada'}>} (SUM({<Sales *={"*"}>}Sales)))
({<Department *= {'Groceries'}>*<Department *= {'Groceries'}>} ({<Location *={'Canada'}>}SUM(Sales)))
({<Department *= {'Groceries'}>*<Department *= {'Groceries'}>} (SUM({<Location *={'Canada'}>}Sales)))
It seems difficult to justify why the following would give different results:
({<Department *= {'Groceries'}>*<Department *= {'Groceries'}>} (SUM({<Location *={'Canada'}>}Sales)))
({<Department *= {'Groceries'}>} (SUM({<Location *={'Canada'}>}Sales)))
The intersection of 2 equivalent sets should be functionally equivalent to just itself. (i.e. <Department *= {'Groceries'}>*<Department *= {'Groceries'}> should be the same as <Department *= {'Groceries'}>) I don't see how that would cause inheritance to behave differently, unless it is attributable to a bug in the inheritance logic that handles intersections of sets involving the same field.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I do interpret the help description a bit different and think that the inner and outer set analysis are not completely equally - deduced from the statement that the inner set has a precedence and that the outer sets would inheritance the sets from each other. IMO the inner set has no inheritance-feature unless against the belonging/defined state and further that inheritance is not the same as combining and/or nesting multiple sets with certain orders - regardless if it's applied inner or outer.
In this sense I would like to refer to my above answer and querying the question - is it possible to set the wanted sets just per field-selections? I'm not sure - especially by the multiple selections against a single field. Only from the description it's not really clear how multiple outer set are performed and I wouldn't be surprised if it are multiple actions and may behave like in step 1 selecting a field-value and in step 2 the same field-value is selected which means the selection is removed again.
Beside this I have difficulties to understand what's the aim behind these complex selection approach? The selection-states won't change the belonging data-set and their associations and therefore not providing any views which aren't covered from the data-set and data-model. Only by applying aggr() the belonging data-set could be extended.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I see what you are saying. The documentation makes no claims as to what it means to inherit. Sometimes when inheritance breaks because it gives up when it doesn't like what the set is asking it to do. How it breaks and when it breaks is not documented, so it appears arbitrary. Maybe inheritance is always random like that, but the inner set syntax doesn't allow nested inheritances easily. It always had to be wrapped in a SUM(AGGR(...)) when nested so the AGGR ends the inheritance chain by design. However with the new outer set syntax, it is allowed and made easier to chain nested inheritances with the new syntax and the problem with inheritance is more easily encountered through regular use.
My actual expressions are far more complex. We need access specific sets of data to perform calculations and the calculations are different by different sets and the result all have to be part of a large calculation that produce a single number. We have variables that defines expressions to calculate each step of those calculations, so it easier to reuse the same calculation for a different, but similar set. (e.g. the requirement can be to calculate the result for this set the same as the other set but wrap it in another calculation to adjust it a bit) These calculations are specified in guidelines from government regulatory bodies so I can't really just say I don't want to do it that way. Some of the fields where the calculations are bisected by are fields that I would like the users to filter on so they can see the contribution of each value into the final result. The calculation is quite dense so being able to do this is why the associative engine is used. However, current selection is inherited by the sets defined in the formulas, so like you said, it causes the inheritance engine to ignore it randomly when it doesn't like it. When we expect to see that a particular set of data does not contribute to the final result (i.e. null set), it is showing that particular set contribute to all of the final result. The outcome is very misleading.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I get the impression that you are trying to create views and an usability which I wouldn't recommend because of the complexity within the UI which IMO belonged into the data-model and the restrictions for the users.
That invalide selections didn't lead to an error or to a ZERO/NULL result else are just ignored is an intended behaviour within the design since the earliest days of QlikView. IMO that's a good decision because it leads to more simple and expedient approaches.
In my experience are nearly all ways to implement an own navigation logic not so powerful and useful as the native Qlik logic to select just the data you want to see and the green/white/grey coloring showed the association between the data. In this regard I refer to the main-statement of this great blog-posting: Let the User Select - Qlik Community - 1463978 which isn't outdated nowadays.
One or two on-top measurements here and there to support the users could be very helpful but the reverse way especially in the attempt to develop generic solutions is just an overkill of huge efforts, a high complexity and mostly a more worse performance and a bad user experience. There I suggest to keep it as simple as possible and transfers all essential logic in the data-model (usually as a simple star-scheme).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Actually many Qlik experts have recommended and tried to put the logic in the data model and all have failed after costing millions. Data model is not the simple solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Almost everything is orders of magnitude more complicated within the UI than within the data-model. So it's not very likely to get it solved in the UI if you failed with it in the data-model.
To fail with such projects even with experts and wasting millions is not mandatory an art else often it happens with an announcement because of unclear and incomplete requirements by starting the project and/or permanent changes in the meanwhile. In the last years we had had several of them ... There is no bypass - if the building is unstable you will need to start with the foundation again ...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Let me try to explain how I understand Inheritance:
Without outer sets you have something like:
Sum({<SetA>}Sales)
What happen is: the current selection state is inherited to <SetA> and based on expressions of <SetA> there is created a new data set as context for aggregation Sum().
<SetA> can contains modifiers that change the selection. That means that a modifier for field change the element for this field in the inherits selection state!
There exist at least 2 exceptions: if an expression using the function P() or E(). These functions using their own nested selection state. In this way first is creating a data set for the nested set which is the base for the outer set.
If you are using set operators on sets for example like:
Sum({<SetA> * <SetB>}Sales)
the current selection state will inherited to both sets <SetA> and <SetB>, and then for each set is created a data set and finally both data sets are merged to the final data set for the aggregation.
If not used inheritance than:
Sum({<SetA>}Sales) = {<SetA>}Sum(Sales)
Sum({<SetA> * <SetB>}Sales) = {<SetA> * <SetB>}Sum(Sales)
What means inheritance:
{<Set1>}({<Set2>}Sum({<SetA> * <SetB>}Sales))
= {<Set1>}({<Set2>}({<SetA> * <SetB>}Sum(Sales)))
Now, the current selection state is inherited to <Set1> which make some changes on this selection state and inherited the result to <Set2>, <Set2> make some changes on the selection state and inherited the result to both sets <SetA> and <SetB>. And only now starts the process of creating a data set for aggregation like describe above!
That means:
Only a selection state is the object which is inherited!
During inheritance you can only use expressions that only make changes on the selection state! No others!
Specially for inheritance you can not use expressions with nested sets or set operations on sets!
The answer on your question what the difference is:
As an expression
"<Department *= {'Groceries'}>" is inheritable.
"<Department *= {'Groceries'}>*<Department *= {'Groceries'}>" is not inheritable.
Finally, back to the problem with the empty set.
If you make a selection in your app and you get a field where no values are available than this is not determined because you have selected “nothing” in this field. It’s determined by the selection in other fields. That’s the logic behind why empty sets for a field are simply removed from the selection state during inheritance.
This is just my understanding. I don't insist on being right!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I agree with 'almost everything', however this case is the exception. When a multi-step calculation access different parts of the data model, the complexity of that calculation depends on:
- Number of individual items being calculated using different formula
- Number of different joins and levels of aggregation required for each formula
- Number of levels of nested calculations where the above calculations are performed
- Number of times the same overall calculation is applied to combinations of subsets of the dataset
#1: Row based calculations, expression/set analysis wins; Column based calculations, data model wins.
#2: Expression wins since there is no need to specify how to join for each formula when using fields from multiple tables.
#3: Data model wins if the nested calculations aggregate using a supported aggregation function (like SUM); Expression wins if the nested calculations aggregate using a non-supported aggregation function. (Square root sum of squares, with floors and ceilings... this is the case with the formulas I have to do. DSE makes this trivial.)
#4: Expression wins since that's what selections are for; Data model would require all possible subsets to be pre-calculated, unless #3 aggregate together using sums, which they are not.
A large number of 1, makes 2 more complex, and a large number of 2 makes 3 more complex, and a large number of 3 makes 4 more complex. Using expressions eliminates 2 and 4 all together. A data model-only solution just cannot compete in this situation.
In terms of the number of each, this application has:
1: 1000-2000
2: 100-400
3: 30-100
4: 100-1000
Those experts failed because they refused to read the requirements. They either thought it was too boring or refused to believe it could be that complicated. To be fair, regulatory text is never an easy read. There were a few that did read the requirements and this is the solution we came up with. I am sure there are better ways of doing it, but the intersection of Qlik experts who are also willing to read the requirements is too small to come up with anything else. That is why this method is used by 70% of the world (by dollar amount) at this moment for this purpose.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For this statement, I can see set operations not being supported, but what do you mean by cannot use expressions with nested sets? Maybe that is what I am missing.
Specially for inheritance you can not use expressions with nested sets or set operations on sets!
I think what you are saying below somewhat fits my observation. However, when the sets being inherited are specified on the same field with *=, determining the inherited state by the selections in the other fields ignores the fact that there is possibly useful information in the filtered field that is being lost. In the case of the simple example, both the selection on Department and the set analysis filter on Department are ignored. If I created a copy of the Department field as Department.Selection and selected Department.Selection field instead, then rather than ignoring one or both of the 2 fields because there is no values available, it does not remove either from the selection state during inheritance and keeps both. (actually gets the correct result)
Both inheritances encountered a situation where no values are available, yet one decided to remove both and the other decided to remove neither. Does that not feel like an issue with the *= inheritance?
If you make a selection in your app and you get a field where no values are available than this is not determined because you have selected “nothing” in this field. It’s determined by the selection in other fields. That’s the logic behind why empty sets for a field are simply removed from the selection state during inheritance.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Trying to classify the requirements in this kind is surely not bad but I wouldn't go with the hinted derivations. Not with the estimation which type of calculation/matching is working better in the UI or within the data-model and not with (pre) determining of the solution-design.
Depending on the requirements you may really need 100% of all wanted views which means the frequency of calculation-types and where and how of solving them couldn't be a valide signpost of the design decision.
Further it seems that your experts were none. Not reading the requirements is an absolute guarantee of - No Go! It sounds that your project is rather large and with some complexity - so the experts should have at least 10+ years of experiences with project-business and with the technically/conceptual part of QlikView (not just the sales/marketing guys) and those should be also do the main-work and not the apprentices.
Therefore I remain by my above suggestion to restart the project with doing the essential work within the data-model. This doesn't mean to pre-calculate everything else to associate the data in a sensible way. This may include to categorize the dimensions in more ways and/or creating n flag-fields and/or applying The As-Of Table - Qlik Community - 1466130 and other things more ...
And this by starting with a star-scheme and vertically/horizontally merging all facts into a single table by harmonizing field-names and data-structures as much as possible. It might be in the end not the final data-model but it's very simple to start with it and very often it will already cover all needs.