Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: [Perfect Key]?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
[Perfect Key]?
Hi all,
Please see this screenshot from my data model:
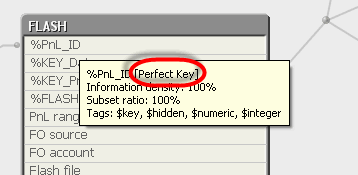
Can anyone please explain what "Perfect Key" means? Not every key has it. I do like to think my model is perfect  ...
...
Thanks,
Jason
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Precise and accurate!
Thanks for this Francesco!
KRgrds,
Paul E.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you provide me Qview Developer 11 Pdf if you have
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Let me try as well...
REF: QlikView 11 For Developers..
Information density of the field, which indicates the percentage of rows that contain a non-null value
Subset ratio, which shows the percentage of all distinct values for a field in the
table compared to all the distinct values for that field in the entire data model. It is
only relevant for key fields since they are present in multiple tables and do not all
share the same value.
Subset ratios can be used to easily spot problems in key field
associations.
For example, when the combined total of subset ratios for multiple
tables is 100 percent, this may indicate that there are no matching keys between
these tables.
Let me give you simple example
Sales:
Load * Inline
[
Customer, Sales
A, 100
B, 200
D, 300
];
Customer:
Load * Inline
[
Customer
A
B
C
D
];
If you write above sample script and will check the Table (CTRL + T), you will find two tables.
Sales and Customers
On Sales Table, if you hover the mouse on Customer field, you can see the Subset Ratio is 75% because there is not sales data for Customer C.
Now if you change the script for table Customer like below..
Customer:
Load * Inline
[
Customer
A
B
C
D
]
Where Exists (Customer);
If will not load the Customer C as there are no sales data for the same.
Now check the Subset Ratio. It will be 100%.
If subset ratio is less than 100%, the key is called as Primary Key
but for 100% it is called as Perfect Key.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
First of all, I like the explanation of Primary key using orphan as well as the simplify one - Primary Key is Perfect Key with subset ratio less then 100%.
Nonetheless, I'm still trying to understand the following statement (which somehow I thought it is not correct or perhaps I am missing some concept in Qlik Data Model, and therefore, may be someone can share their views):
'[Primary Key] indicates that all key values are unique, but not every row contains a key value or the field's subset ratio is less than 100 percent'
SO in the following example given:
InvoiceDetails:
LOAD *
INLINE [
InvoiceID, InvoiceLine, ProductID, Quantity, Amount
Inv001,1,PR01,10,50
Inv001,2,PR02,10,40
Inv002,1,PR01,30,150
Inv003,1,PR03,10,800
];
Invoices:
LOAD *
INLINE [
InvoiceID, ClientID
Inv001,CL0001
Inv002,CL0002
];
As explained, InvoiceID is a Primary Key in Invoces table only because there is an InvoiceID (Inv003) in INVOICEDETAILS table that is not shown in Invoices table.
But the every ROW in INVOICES table contains a Key Value (which is contradict to the statement above). I wanna think that this explanation based on both tables have been joined, but then, the InvoiceID is not unique per row anymore and would become 'Key'.
Hope someone can help to explain. Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Manish i think u r correct, your explanation is meaningful.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi David,
it appears that there is a bit missing from that explanation from the QlikView Developers book from NoStarch. One extra criteria is that this would be a perfect key, except there is a key in the data model that the Invoices table doesn’t have a match for - in other words it’s ”dangling”. This means as it can’t be a perfect key, then it must be a primary key.
- « Previous Replies
-
- 1
- 2
- Next Replies »