Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Performance: Set Analysis vs. IF vs. Multiplicatio...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Performance: Set Analysis vs. IF vs. Multiplication
One of the articles in the Wiki is "Using Flags to avoid IF formulas". The advice certainly seems straightforward and correct on the surface. Yes, doing an IF with a flag should be faster than a more complicated conditional. Yes, it makes sense to have a flag with values 1 and null() to avoid distortions of aggregations (depending on the type of aggregation, anyway). Yes, you can multiply by such a flag instead of doing an IF.
So really, the article itself seems correct, if perhaps incomplete, since it doesn't show any real testing results, and relies instead on a single performance anecdote.
But it was one of the COMMENTS that piqued my interest. Specifically, "SET ANALYSIS is faster than IF, but still slower than a simple multiplication". Based on my understanding of what the computer would have to do for each, I would expect IF to be slightly faster than multiplication, and set analysis to be MUCH faster than either.
Set analysis should be fastest because it takes advantage of QlikView's selection engine to simply toss out all of the rows that don't match. It doesn't even look at the other rows, so it should pull further and further ahead the fewer the number of matching rows. And IF should be next, because checking that one value equals another value is a faster operation than multiplying two values together.
And on my computer, at least, I appear to be right. My analysis also suggests that flags are faster than more complicated comparisons, as we would reasonably expect.
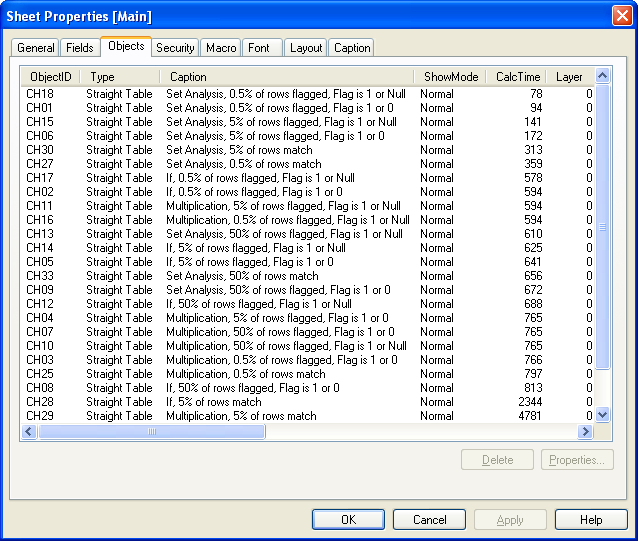
I built a 10,000,000 row table with each row being for one of three customers, and including a random value and random sales. I then built a matrix of charts. The basic idea of each chart was to sum matching sales by customer, where the match was defined by the random value so as to include a specified percentage of rows. I compared set analysis to IF to multiplication. I compared checking the condition vs. checking a 1/0 flag vs. checking a 1/null() flag. I compared at 1/2%, 5% or 50% of the rows of the table being matches.
To make sure I wasn't using any cached data in any way, I rebooted my computer, brought up QlikView, and loaded the file.
Here is the file if you want to try to either duplicate or disprove my results. And perhaps there is a reason why the results are invalid, and perhaps you can come up with a better test.
I changed the number of rows down to 10,000 in the file instead of 10,000,000 so that I could upload it. You'll want to change it to some appropriately high number for your own hardware. 10,000,000 worked well on my antiquated work PC.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
And here are the performance results on my own computer at 10,000,000 rows of data.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
epic thread, i like it.
thanks john.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thanks for the in depth analysis John.
I still don't see performance progresses between Qv9 and Qv9SR5 when intensively employing SA.
I have some big drawbacks when I try to modify an "old" model I built for a customer with 8.5:
charts with SAs are 10x slower on 9SR5 compared to 8.5 in my experience, it seems like there is some recalculation going on every time a small change is made (even on the graphical layout).
I hope there are going to be some good news with Qv10.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Francesco,
It may be obvious but have you checked that you are reducing data on opening? Since those changes are too slow for v9, it could be because of having an "initial selection based on section access" rather than actual reduction of data.
Regards.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In this situation I don't even have a section access to manage.
thanks for pointing me that anyway!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
A concept proof thread
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for doing this test, John. I asked a question around this here: Which will give me best performance - using Boolean Algebra or nested IFs (or CrossTable)?