Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Question on Data Modelling?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Question on Data Modelling?
Currently I am working with a single dataset (Excel) which contains job requisition data of 140 columns , when I tried to classify dimension and facts in this data set . I am seeing all the data as dimensions say JR ID, Grade,Region,Country .. all are dimension each and every row of data is independent. The only aggregation function I could think of is count(). But still I can do business grouping say all the grade level info in a table,geographic in one, and recruitment manager and hiring manager in separate table.
File size is 70 MB and when I get it in Qlikview app is 7.2 MB already. Performamce is good too.
Question is do I really need to do business grouping( Dimensional Modelling) or can I proceed with single flat table?Ashfaq Mohammed Jagan Mohan
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
For small amount of data you won't see any difference in performance but for huge data you will have performance issues. Refer attached image for the comparison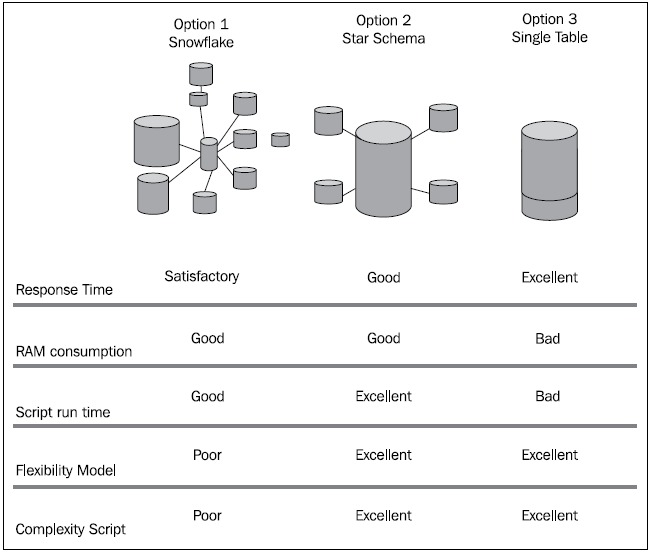
Regards,
Jagan.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
It really Depends on the number of records and the type of calculation required.
If you have simple aggregations like count I prefer you to go with the same Flat file approach, unless it effect any performance.
Regards
ASHFAQ
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Deepak,
If you have just one Transaction table and master tables then you can join the Transaction and Master tables and convert it into a single table, but there are scenarios where you have multiple fact tables like Bill Header and Detail tables then you will have issues converting it into a single table. If you have huge data then the performance issues will arise.
I prefer perfect data model instead of single table.
Regards,
Jagan.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I agree! But in my table there is one and only table which is transaction and each row is independent of another. So now tell me flat or Dimensional grouping??? and there are no columns I could classify for fact because there are literally no numbers in the table I have . Only number I could see Salary range which is again a dimension.
Basic question should I go for Factless Fact table or not???
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
For small amount of data you won't see any difference in performance but for huge data you will have performance issues. Refer attached image for the comparison
Regards,
Jagan.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It depends... 
If your dimensions are truly independent then you will get no benefits from splitting out your model as you only have a single granularity in your data.
If you do have logical dimension entities in your model then you will benefit from splitting out the data as this allows you to pre-calculate measures at the different levels of granularity. For example you may have sales orders and sales order lines. In a single table to provide the number of orders you would have to do COUNT(DISTINCT OrderId) in your chart. However if you split the model into 2 tables you could have SUM(#Orders) which is clearer and faster to calculate.
Hope that helps
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
For your model I prefer to keep it flat
Regards
ASHFAQ