Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: SQL equivalent
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
SQL equivalent
Hello Experts,
Could someone please give me equivalent of below SQL script ?
SELECT t1.id,
t1.parent_id,
t1.name,
t2.name AS parent_name,
t2.id AS parent_id
FROM tbl t1
LEFT JOIN tbl t2 ON t2.id = t1.parent_id
START WITH t1.id = 1
CONNECT BY PRIOR t1.id = t1.parent_id
I found solution to one of my tasks ( see previous thread How to find References of table entries recursively ? for more details) using SQL. But i would request your help in resolving to QlikView Script.
- Tags:
- new_to_qlikview
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
Do you try bring as sql?
Load *;
SQL SELECT....
and then put all your sql
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
//** this emulates some hierarchy data
[SOURCE]:
LOAD * INLINE [
parent_id id name
0 1 Level1
1 2 Level2
2 3 Level3
1 2.5 Level2.5
3 4 Level4
](delimiter is ' ');
[t1]:
NOCONCATENATE LOAD parent_id, id, name RESIDENT [SOURCE];
[HIERARCHY]:
Hierarchy(id,parent_id,name,,name,hierarchy,'\',depth)
LOAD * RESIDENT [t1];
DROP TABLE [t1],[SOURCE]; 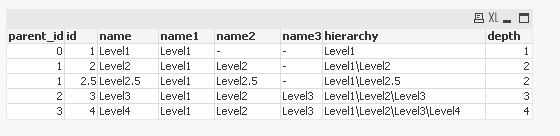
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Vamsi,
Can you attach the sample data for two tables.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
File 1:
UIDs
ABCD
EFGH
HIJK
JKLM
LMNO
OPQR
QRST
STUV
UVWX
WXYZ
File 2:
UIDREF1
ABCD | UIDREF2 LMNO |
| EFGH | WXYZ |
| HIJK | STUV |
| LMNO | WXYZ |
Requirement is that I shall pick each line from File 1, and search for all references in File 2.
Example:
Result 1: ABCD -> LMNO -> WXYZ -> EFGH
Result 2: EFGH -> WXYZ -> LMNO -> ABCD
Result 3: HIJK -> STUV
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Evan,
I am new to QlikView, hence not able to comprehend to my data. I have attached File 1 and File 2 data below, Please let me know how can i achieve the same.
File 1:
UIDs
ABCD
EFGH
HIJK
JKLM
LMNO
OPQR
QRST
STUV
UVWX
WXYZ
File 2:
UIDREF1 ABCD | UIDREF2 LMNO |
| EFGH | WXYZ |
| HIJK | STUV |
| LMNO | WXYZ |
Expected Output :
Result 1: ABCD -> LMNO -> WXYZ -> EFGH
Result 2: EFGH -> WXYZ -> LMNO -> ABCD
Result 3: HIJK -> STUV
.
.
. so on.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Vamsi,
The following will reproduce the results you seek. But really what I was after was something that really captured following the efficiencies of the associations. When you flip the sides of a table and join it back in on itself, is that still technically recursive?

[t1]:
LOAD *, Child AS Level INLINE [
Parent,Child
ABCD,ABCD
ABCD,LMNO
LMNO,WXYZ
EFGH,EFGH
EFGH,WXYZ
HIJK,HIJK
HIJK,STUV
](delimiter is ',');
[HIERARCHY]:
Hierarchy(Child,Parent,Level,,Level,hierarchy,'\',depth)
LOAD * RESIDENT [t1];
//** For your second pass it looks
like you flipped the sides of the table on itself
//** and worked your way back down
[temp2]:
NOCONCATENATE LOAD *, Child2 AS Level2 INLINE [
Child2,Parent2
ABCD,LMNO
LMNO,WXYZ
EFGH,WXYZ
WXYZ,WXYZ
HIJK,STUV
STUV,STUV
](delimiter is ',');
[H2]:
Hierarchy(Child2,Parent2,Level2,,Level2,hierarchy,'\',depth)LOAD * RESIDENT [temp2];
qualify*;
[H3]:
NOCONCATENATE LOAD * RESIDENT [H2];
UNQUALIFY *;
LEFT JOIN(HIERARCHY)
LOAD H3.Level21 AS Child,
H3.hierarchy AS Part2 RESIDENT [H3];
DROP TABLE [H3];
DROP TABLE
[t1],[temp2],[H2];
[h4]:
NOCONCATENATE
LOAD MaxString(Final) AS F2
GROUP BY hierarchy;
LOAD *, hierarchy & Attach AS Final;
LOAD hierarchy, Part2, Right(Part2,Len(Part2)-Len(Subfield(Part2,'\',1))) AS Attach, Subfield(Part2,'\',1) & Subfield(Part2,'\',2) & ':'
& Subfield(hierarchy,'\',-1) & Subfield(hierarchy,'\',-2) AS Flip RESIDENT HIERARCHY
WHERE LEN(Part2)>0
AND NOT Subfield(Part2,'\',1) & Subfield(Part2,'\',2) = Subfield(hierarchy,'\',-1) & Subfield(hierarchy,'\',-2)
;
DROP TABLE [HIERARCHY];
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Also... another result, but this time no extra rows inserted into base table
[t1]:
LOAD *, Child AS Level INLINE [
Parent,Child
ABCD,LMNO
LMNO,WXYZ
EFGH,WXYZ
HIJK,STUV
](delimiter is ',');
[MAP_PARENTS]:
MAPPING LOAD DISTINCT Child, 0 RESIDENT [t1];
CONCATENATE(t1)
LOAD DISTINCT Parent, Parent AS Child, Parent AS Level RESIDENT [t1]
WHERE NOT ApplyMap('MAP_PARENTS',Parent) = 0;
[HIERARCHY]:
Hierarchy(Child,Parent,Level,,Level,hierarchy,'\',depth)
LOAD * RESIDENT [t1];
[H2]:
LOAD *, Right(hierarchy,4) AS [NewField_1];
LOAD MaxString(hierarchy) AS hierarchy
RESIDENT [HIERARCHY]
GROUP BY Level1;
DROP TABLE [HIERARCHY];
FOR i = 1 to 5
j = $(i) + 1
LEFT JOIN(H2)
LOAD Child AS [NewField_$(i)],
IF(Parent=Child,Null(),Parent) AS [NewField_$(j)] RESIDENT [t1];
NEXT
[FINAL]:
NOCONCATENATE
LOAD MaxString(FINAL) AS FINAL GROUP BY Subfield(FINAL,'\',1);
LOAD
hierarchy &
IF(Index(hierarchy,NewField_2)=0 AND Len(NewField_2)>0, '\' &NewField_2 ) &
IF(Index(hierarchy,NewField_3)=0 AND Len(NewField_3)>0, '\' &NewField_3 ) &
IF(Index(hierarchy,NewField_4)=0 AND Len(NewField_4)>0, '\' &NewField_4 ) &
IF(Index(hierarchy,NewField_5)=0 AND Len(NewField_5)>0, '\' &NewField_5 ) &
IF(Index(hierarchy,NewField_6)=0 AND Len(NewField_6)>0, '\' &NewField_6 ) AS FINAL RESIDENT [H2];
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Evan,
This almost provided me with results i am looking for. But some how it is missing one line item here. Please see below.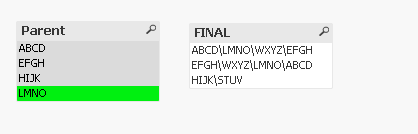
1. For some strange reason, i dont see results of LMNO.
2. Also I got few open queries . I have file 1 from where i pick up each entry and have to look in File 2 starting from column 1 in file 2. Kindly let me know how that can be done.
3. Your script is using the number of lines present in the input file (FOR i = 1 to 5). How can i use this for my scenario, where File 1 is having 120 million records and File 2 is have 3.5 Billion Records (spread across two columns).
P.S: I know i am getting all done from you, but believe me I have done this using C code, but not finding useful. Also i am too far from QlikTech.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Based on the 3 result rows you outlined and isolated from the larger list of possible sub-chains, here's how I interpreted the "rules" of your data:
The only result rows you are seeking are the longest chains of association per absolute parent. A valid chain cannot include any given node twice. A chain built from parent & child LMNO would have produced LMNO/WXYZ/EFGH, but this is a subset of your Result 1 chain: ABCD/LMNO/WXYZ/EFGH.
This means that any result row that begins with a node that is also a child is omitted from the result set. Otherwise you would need to modify your own results example with a Result 4.
Result 1: ABCD/LMNO/WXYZ/EFGH
Result 4: LMNO/WXYZ/EFGH
If you want all the sub-node combinations back in there, just start lopping off the WHERE clause filters where I'm trimming the result set down.
Question 2: The best way to work with multiple files is to use the File Wizard. Treat each separate file as you would a database table.
Question 3: The i loop iteration just needs to perform as many re-joins of the table to itself as many times as there is depth to the hierarchy (similar to if you broke open the hierarchy command and applied it in the individual steps). You could probably assign i to the [depth] field generated by the hierarchy() statement on the way in, as when you flip the table and go back down, I think the maximum depth has to be the same coming & going
Rowcounts wouldn't matter, what would matter is how many nodes are stacked onto your longest chain.
Lastly though.. whether this can be done easily in C, or SQL, or I'm sure there's a leaner solution in QlikView, it still seems like the data formats are... convoluted. Without seeing the applicability to a real-life usage, having a hard time visualizing why you'd want to complicate things by having the node chains double-back on themselves, vs. just laying them all out in a straight line.
- « Previous Replies
-
- 1
- 2
- Next Replies »