Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Sample Sets of Data
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sample Sets of Data
I'm looking to create a flag that randomly selects 5% of my unique identifiers and flags them as a "Trial Group". See my code below
if((rand()<=0.05+now()*0) = 0, 'Standard Group', 'Trial Group') as [Trial Flag]
I'm uncertain if this is doing what I want it to do. At a quick look it does, but I'm a little confused on how this is randomly selecting 5% of unique identifiers without referencing the unique identifier in this line of code??
- Tags:
- qlikview_scripting
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hmmm ignore what I said, I think your method seems to be the accepted solution!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
based on my testing this doesn't produce an accurate 5% figure, on 20,000 rows I got figures between 964 and 1037 over 5 reloads.
How precious are you with it being exactly 5%?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok thank you. So does my code randomly select 5% of unique identifiers or 5% of all data. In my mind, those two things are different. I would want to capture the former. Perhaps, this is a misunderstanding of what this function returns?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This will flag *roughly* 5% of your data in the table.
Can you share any data at all? or at least your column names and expected results, this problem has nagged me for ages so I will find a solution!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here is my working, sorry im just heading out of the office but will pick up in the morning.
This is selecting an EXACT 5% sample, not just a rough one, i.e. in my data 1093 rows every time
Sorry its a work in progress, need to tidy it all up
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I cannot share any data. However, the column names is not an issue.
Sequence is my unique identifier (customer)
All other fields are related to this unique identifier(customer attributes)
I want to randomly select 5% of customers (5% of Sequences) and flag them as "Trial Group" and leave the others as "Standard Group"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Seth,
I am working on this, but decided to make a blog of it as its vexed me for ages, so I am doing some proper testing.
So far I am happy with the results though
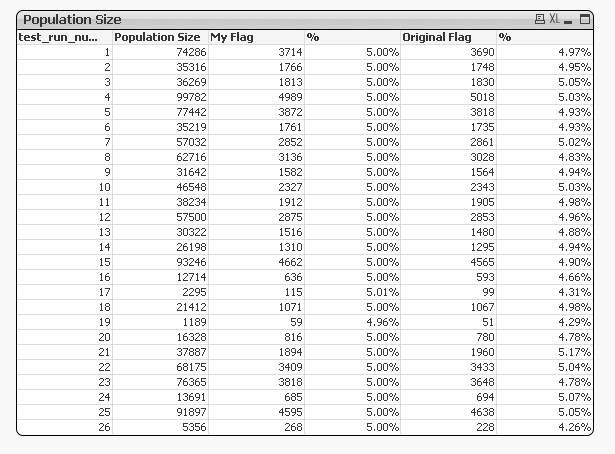
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
OK so the simple answer is:
1- *i assume* your current set up will be loading 5% of all of your transactions not customers
2- the current setup is not completely accurate so if you want your sample tolerance to be within +/- 0.05% then check out my blog (Accurately selecting a random percentage sample)
If you're happy with a tolerance of what appears to be +/- 1% then you can do something like the below.
If your current code is say:
fact:
Load
transactionid,
sequence,
somotherdata,
if((rand()<=0.05+now()*0) = 0, 'Standard Group', 'Trial Group') as [Trial Flag]
from blah;
Then this will be a 5% (ish) sample of all data.
To make this be a 5% sample of sequence then something like this needs to be done (and you could also left join if you wanted) and apologies if my syntax is out anywhere I have written this on the fly:
tmp:
load distinct
sequence
from blah;
noconcatenate
tmp2:
mapping load
sequence
if((rand()<=0.05+now()*0) = 0, 'Standard Group', 'Trial Group') as [Trial Flag]
resident tmp;
drop table tmp;
fact:
Load
transactionid,
sequence,
somotherdata,
applymap('tmp2',source,null()) as [Trial Flag]
from blah;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you want to randomly select 5% of unique Customer names, you can use this in your script:
CustomerTypes:
LOAD FieldValue('CustomerName', RowNo()) AS CustomerName,
if((rand()<=0.05+now()*0) = 0, 'Standard Group', 'Trial Group') as [Trial Flag]
AUTOGENERATE FieldValueCount('CustomerName');
You can use whatever field in whatever facts table to extract only distinct values. Of course, the same would be true if you use a LOAD DISTINCT, but this code loads from the symbol table, which may be faster.
Peter