Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Set Analysis and Data Model
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Set Analysis and Data Model
I have a question about how set analysis expression evaluate depending on your data model. I have a situation where I have cases and each case has several materials associated with it and each material is either used or unused. I wanted to use set analysis to get the set of cases with certain materials that were also used (the intersection of the set containing just those materials and the set containing only used materials).
The case identifier is linked to the material usage with a key dimension. Like this: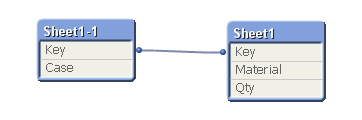
When I use the expression that does the intersection and returns the Key dimension, the intersection works properly.
({<Material = {'A', 'B'}> * <Qty = {'>0'}>} Key)
When I use the expression that does the intersection and returns the Case dimension, the intersection does not work properly and returns additional cases as belonging to the set.
({<Material = {'A', 'B'}> * <Qty = {'>0'}>} Case)
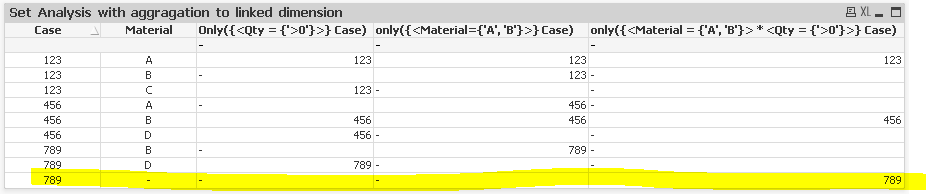
I have attached an example QVW illustrating this example.
Obviously there is something that I don't understand about how set analysis expressions interact with the data model. Any help or explanation is much appreciated!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Try with Aggr()
Like
Aggr(only({<Material = {'A', 'B'}> * <Qty = {'>0'}>} Case),Key)
Regards
Please appreciate our Qlik community members by giving Kudos for sharing their time for your query. If your query is answered, please mark the topic as resolved 🙂
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Try this,
Aggr(only({<Material = {'A', 'B'}> * <Qty = {'>0'}>} Case),Key,Material)
Regards
Please appreciate our Qlik community members by giving Kudos for sharing their time for your query. If your query is answered, please mark the topic as resolved 🙂
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yep, that works for getting the intersection correctly and returning the Case! Thanks! Can you explain what is happening here? I'm new to QlikView, and I don't uderstand what the aggr() function is doing here.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Basically it is like simple mathematics.
When you use intersection of two sets it takes all possible combination of result of two sets.
So find the required data we have to use aggregate using Key field and dimension field
Here Key and Material will give you unique data.
By the way I am very bad in explaining  .I hope you understand what i want to suggest.
.I hope you understand what i want to suggest.
Regards
Please appreciate our Qlik community members by giving Kudos for sharing their time for your query. If your query is answered, please mark the topic as resolved 🙂