Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Set analysis to get records related to dimensi...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Set analysis to get records related to dimension in chart in a multilevel aggregation
Dear Qlik Fellows:
I am struggling with an interesting case of a related lookup.
Here is my table: 1 DocumentNumber contains >=1 Accounts.
| DocumentNumber | Account |
| 1 | Accounts Receivable |
| 1 | Duties |
| 1 | Tax |
| 2 | Accounts Receivable |
| 2 | Unrecoverable Debt |
Now, I need to display an overview, by Account, how many other Accounts occur under the same DocumentNumber with this Account. I need a table like this:
| Account | Nr of other Accounts occurring in the documents containing this account | How is this Nr of Accounts obtained? |
| Accounts Receivable | 3 | This account is mentioned in DocumentNumber 1 and 2, and there are 3 other accounts in these documents apart from this one |
| Duties | 2 | This account is only mentioned in DocumentNumber 1, and there are 2 other accounts in this document apart from this one |
| Tax | 2 | This account is only mentioned in DocumentNumber 1, and there are 2 other accounts in this document apart from this one |
| Unrecoverable Debt | 1 | This account is only mentioned in DocumentNumber 2, and there is only 1 other account in this document apart from this one |
So, for each Account dimension value:
- Get every DocumentNumber that contains this Account
- Get every Account in the DocumentNumber set that is not equal to the Account on the row
- Count distinct Accounts
Tried this, did not succeed:
=Count({<DocumentNumber=P({$}DocumentNumber), Account=E({$}Account)>}distinct Account)
I have a feeling there should be an Aggr with set analysis. But I am struggling to formulate the logic described above (get the possible DocumentNumbers, then get all Accounts from this set excluding the one in the dimension row).
Attached my Sense exercise.
Thank you
Igor
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
May be this
=Sum(Aggr(Count(total <DocumentNumber> DocumentNumber), DocumentNumber, Account)) - Count(Account)
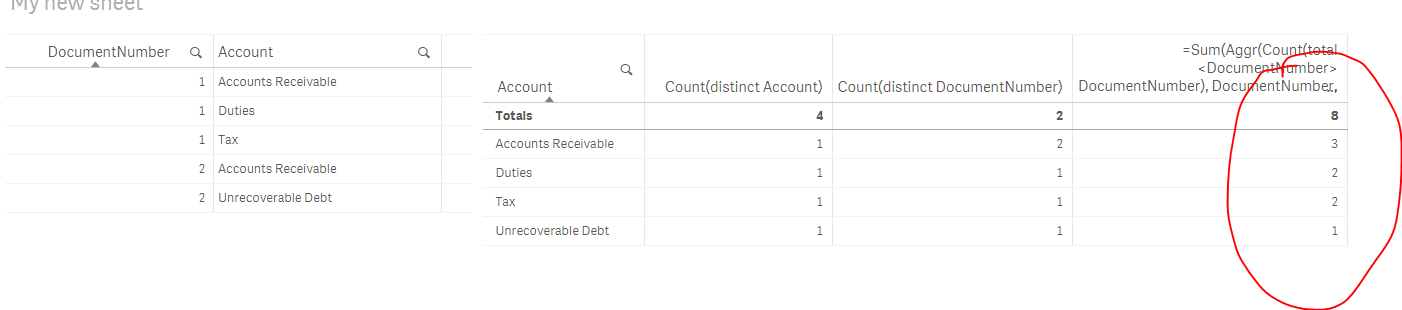
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Kudos to Sunny, very cool! It works as expected!
I have only modified the formula with {1}, and now it works with filters as well
=Sum(Aggr(Count({1} total <DocumentNumber> DocumentNumber), DocumentNumber, Account)) - Count(Account)

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Actually found a problem with this formula now 
I added another document to the sample, and the formula started to double count.
Here you see DocumentNumber 3.
| DocumentNumber | Account |
| 1 | Accounts Receivable |
| 1 | Duties |
| 1 | Tax |
| 2 | Accounts Receivable |
| 2 | Unrecoverable Debt |
| 3 | Accounts Receivable |
| 3 | Duties |
| 3 | Unrecoverable Debt |
I would expect to get 4 for Account = Accounts Receivable. But it is not really counting distinct.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Why 4? Why not 3? Isn't Duties getting double counted also?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
My bad, why is Unrecoverable Debt getting double counted (3 and 4)?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for pointing out, I made a mistake here.
Here's the issue:
For Account that occurs in more than one DocumentNumber in the data, there is double counting. E.g. Accounts Receivable should have 3 related Accounts (Duties, Tax, Unrecoverable Debt), but there are 5.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Probably not the best way in the world to do this... but try this
=SubStringCount(Concat(DISTINCT Aggr(SubField(Concat(Aggr(nodistinct Concat({1} distinct total <DocumentNumber> Account, ','), DocumentNumber, Account), ','), ',', SNo), Account, SNo), ','), ',')
Where SNo is created in the script like this and will depend on how many DocumentNumber/Account combination are there. In this small example, the maximum was 8, but this can very easily be more than that. I would use a bigger number like 10,000 or 15,000 here... but this will somewhat impact performance
SNo:
LOAD RowNo() as SNo
AutoGenerate 20;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the tip Sunny.
My production table contains 360k records, and I would like to minimize any load script actions, so the approach you suggested is not ideal. I think the initial Aggr that you suggested actually looks very promising. It gave pretty close results, and I will continue playing around with it. I'll post here if/when I win.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
All you need in the script is this
SNo:
LOAD RowNo() as SNo
AutoGenerate 20;
This table is not even going to be attached to anything else in your database (it should be an Island Table).... even adding this table is going to be an issue?
Ya, do let us know if you figure something out