Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: mark duplicate records
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
mark duplicate records
Hello,
I am trying to mark duplicate rows in my data based on a condition. My data has several fields like name,lifecycleStatus. There are multiple rows with the same name+ lifecycleStatus as well as different entries for one name with different lifecycleStatus.
for e.g.
Name LifecycleStatus
A Disposed
A Disposed
B User Acceptance
B Disposed
C Operational
C User Acceptance
C Disposed
I am trying to mark the duplicates so as to retain the below:
Name LifecycleStatus
A Disposed ( Keep/Mark/flag only one row of the same entries as valid)
B User Acceptance (Keep/Mark/flag only the row that are not marked as Disposed)
C Operational (Keep/Mark/flag only the row(s) that are not marked as Disposed)
C User Acceptance
I did a left join on self to get a count of Name as a new column to mark the duplicates. So anything with count > 2 is a duplicate. But within the duplicates I need to flag them further based on the lifecycle status.
I can create an expression to further flag down the Names with distinct Lifecycle Status with an expression for e.g.
=if(aggr(count(distinct [LifecycleStatus])>1,[Key_Name]),[Key_Name])
How an I achieve something similar during load? I need to mark the duplicates during load. I have attached a sample qvw.
Any help/guidance is highly appreciated.
Thanks,
Samira
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Maybe like
INPUT:
LOAD DISTINCT * INLINE [
Name, Status
A , Disposed
A , Disposed
B , User Acceptance
B , Disposed
C , Operational
C , User Acceptance
C , Disposed
];LEFT JOIN
LOAD Name, Count(Status) as Count
Resident INPUT
Group by Name;RESULT:
NOCONCATENATE
LOAD Name, Status
Resident INPUT
Where Count =1 or Status <> 'Disposed';DROP TABLE INPUT;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
to identify e.g. only the first of each Key/Status combination, maybe something like this might help:
CMDB:
LOAD CMDB_Key_Name,
NodeIP,
CMDB_LifecycleStatus,
CMDB_OperatingSystem,
CMDB_sys_class_name,
CMDB_sys_id,
Key_OS,
AutoNumber(RecNo(),CMDB_Key_Name&'|'&CMDB_LifecycleStatus) as FlagKeyStat
FROM QlikCommunity_Thread_201320.csv (txt, utf8, embedded labels, delimiter is ',', msq, no eof);
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
INPUT:
LOAD DISTINCT rowno() as Id, * INLINE [
Name, Status
A , Disposed
A , Disposed
B , User Acceptance
B , Disposed
C , Operational
C , User Acceptance
C , Disposed
D, Disposed
];
load
Id, Name, Status,
Name <> Peek('Name') or Name = Peek('Name') and Status <> 'Disposed' as Flag // 1 not dupl
Resident INPUT
order By Name, Status desc;
DROP Table INPUT;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just another approach:

Here is the data model:
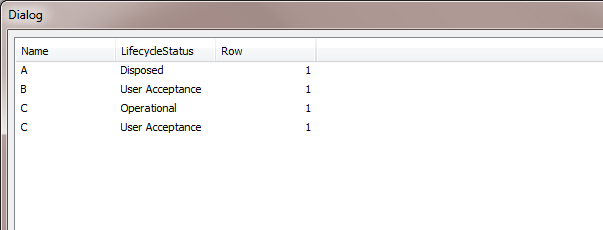
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello, thank you for the fast response. I tried the solution you suggested but I was losing all the entries with same Name and Status. So in my e.g. above I was losing all entries for A but it handled the other scenario pretty well. I was able to use your suggestion (along with below suggestion from MG to use peek) and incorporate it in my model to get the results.
I basically created 2 flags, one for count (distinct Lifecycle status) per Name and another flag for count (Name) per same lifecycle status for itself and then used peek to pick the first record from within the same duplicate entries ( for Name + Status).
Thanks,
Samira
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello M G,
Thank you for your suggestions. When I tried your approach against my data, it retained all rows for duplicates with same Name but different Status, however it handled the duplicates with the same Name + Status very well. In my e.g. above it retained the below
| row | Name | Status | flag |
| 13099 | B | Disposed | -1 |
| 568 | B | User Acceptance | -1 |
| 205 | A | Disposed | -1 |
| 11881 | A | Disposed | 0 |
However the result I was looking for is as below:
| row | Name | Status | flag |
|---|---|---|---|
| 13099 | B | Disposed | 0 |
| 568 | B | User Acceptance | -1 |
| 205 | A | Disposed | -1 |
| 11881 | A | Disposed | 0 |
I was able to create another flag as suggested by swuehl and use your suggestion for peek to get the results.
Thanks,
Samira
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marco,
Good suggestion, thank you. I will try that in my solution as I make further progress. I have multiple data sources that I plan to merge into this and this will come handy for sure.
Thanks,
Samira