Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: only want to load new records only...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
only want to load new records only...
I am using incremental load scenario and I have the data like this:-
I have receive the file on 21-Mar with data:-
field1 field2 field3 field4
1 a a1 2
1 b b1 2
1 b b2 4
1 c c1 3
and I have the file receive on 22-Mar with data:-
field1 field2 field3 field4
1 a a1 3
1 b b2 3
1 d d1 4
and field1,field2 and field3 all three are making a primary key(field1,field2,filed3) and my requirement is that when I load 22-Mar file then It only pick the record receive on 22-Mar only not on 21-mar file for filed1 with value1.But it is picking the records as shown below:-
field1 field2 field3 field4
1 a a1 3
1 b b1 2
1 b b2 3
1 c c1 3
1 d d1 4
and I am using the script shown below:-
load field1,field2,field3,field4 from 22-Mar file;
load field1,field2,field3,field4 from 21-Mar file
where not exist primary key(field1,field2,field3);
So, Please help me on this ....
I want to show only these records as shown below after incremental load:-
field1 field2 field3 field4
1 a a1 3
1 b b2 3
1 d d1 4
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes its replacing data of tab1 if available in Tab2, otherwise
Loads from Tab1 only...
Example:
Tab1:
Field 1 Field2 Field 3 Field 4
1 a a1 2
Tab2:
Field 1 Field2 Field 3 Field 4
1 a a1 3
Output is having
Field 1 Field2 Field 3 Field 4
1 a a1 3
otherwise previous data from Tab1 is loaded
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
yes sir it is replacing but also loading data from tab1 like shown below:-
field1 , field2 , field3 , field4
1 , b , b1 , 2
1 , c , c1 , 3
these entries are not there in tab2 so it should not come.
Actually Field1,Filed2 and Field 3 makes Primary Key but It will only watch for Field1 and If it repeated then replace all value of tab1 with tab2.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
have you tried the above solution ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the reply but why you are not loading 21-March file.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Oh for your understanding i have sent like that, keep all the files in one folder and correct the path , please put * on loading as given below
Load
field1,
field2,
firstsortedvalue(field3,-Date) as field3 ,
| firstsortedvalue(field4,-Date) | as | field4, |
firstsortedvalue(Date,-Date) as Date
group by field1,field2;
Load *,
date(Date#(trim(filebasename()),'DD-MMM-YYYY'),'DD/MM/YYYY') as Date
from
$(vPath)/*.xls;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the reply prem. But It is just concatenating both files.
It is giving o/p like shown below:-
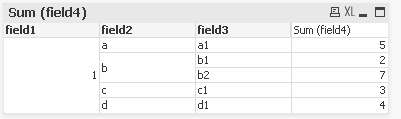
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Anand,
As I understand from your description you want to
- use old data from [Mar21] where field1 does not match with [Mar22].field1 data , and concatenate it with
- new data from [Mar22] file
Please try the following option.. and let me know if it works ..
//Mar22 data
[Mar22]:
LOAD * INLINE [
field1, field2, field3, field4
1, a, a1, 3
1, b, b2, 3
1, d, d1, 4
];
NoConcatenate
//Get unique Field1 values from Mar22 table for using it in the not-exists load
[Mar22_field1]:
LOAD Distinct field1 as Mar22_f1 Resident Mar22;
NoConcatenate
//Mar21 data
[Mar21]:
LOAD * INLINE [
field1, field2, field3, field4
1, a, a1, 2
1, b, b1, 2
1, b, b2, 4
1, c, c1, 3
2, a, a1, 5
2, a, a2, 4
];
NoConcatenate
[Final]:
LOAD * Resident [Mar22]; //load new data
LOAD * Resident [Mar21] where not Exists(Mar22_f1, field1); //load old data where field1 does not match with the new data
DROP Table Mar21, Mar22, [Mar22_field1];
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I found the solution:--
Solution is:-
A:
load distinct field1,1 as status form tab2;
join
load * from tab1;
store A into A.qvd;
drop A;
load * from tab2;
load * from A.qvd where status<>1;
- « Previous Replies
-
- 1
- 2
- Next Replies »