Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Create QVD
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Create QVD
T1:
| ID | Name |
| 1 | er |
| 2 | fsdf |
| 3 | dfsd |
T2:
| ID | text |
| 7 | nm |
| 8 | f |
| 9 | j |
T3:
| ID | COM |
| 1 | cvd |
| 2 | df |
| 3 | v |
| 4 | sd |
| 5 | sdf |
| 6 | sdfa |
| 7 | fd |
| 8 | dffd |
| 9 | sfdf |
I have 3 tables and a create QVD shold be created on below conditions:
1)T3.ID = T1.ID
2)T3.ID = T2.Id
and the final Qvd will be created as below
expected output:
| ID | COM | Name | text |
| 1 | cvd | er | |
| 2 | df | fsdf | |
| 3 | v | dfsd | |
| 7 | fd | fd | |
| 8 | dffd | dffd | |
| 9 | sfdf | sfdf |
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
T1:
LOAD ID, Name FROM ...;
JOIN
LOAD ID, text FROM ...;
JOIN
LOAD ID, COM FROM ...;
Result:
LOAD * FROM T1
WHERE Len(Trim()Name)> 0 or Len(Trim(text))>0;
Drop Table T1;
talk is cheap, supply exceeds demand
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
T1:
load * inline [
ID Name
1 er
2 fsdf
3 dfsd
] (delimiter is spaces);
join (T1)
load * inline [
ID text
7 nm
8 f
9 j
] (delimiter is spaces);
left join (T1)
load * inline [
ID COM
1 cvd
2 df
3 v
4 sd
5 sdf
6 sdfa
7 fd
8 dffd
9 sfdf
] (delimiter is spaces);
store T1 into T1.qvd (qvd);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
In my case T3 has 20million data so we cannot pull that many records as load time will be increased
so i need to pull the data for T3 which will match from T1 and T2
and we are not supposed to pull complete data of T3
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
In my case T3 has 20million data so we cannot pull that many records as load time will be increased
so i need to pull the data for T3 which will match from T1 and T2
and we are not supposed to pull complete data of T3
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Result:
LOAD ID, Name
FROM T1.qvd (qvd);
CONCATENATE (Result)
LOAD ID, text
FROM T2.qvd (qvd);
JOIN (Result)
LOAD ID, COM
FROM T3.qvd (qvd)
WHERE EXISTS(ID, ID);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
nearly the same as the other solutions, but I used Exists(ID) like Graeme did to keep the load optimized and join the first tables rather than concatenating it to avoid duplicates with your real data:
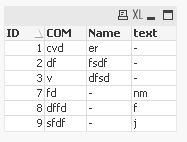
[expected output]:
LOAD * FROM [https://community.qlik.com/thread/204080] (html, codepage is 1252, embedded labels, table is @1);
Join
LOAD * FROM [https://community.qlik.com/thread/204080] (html, codepage is 1252, embedded labels, table is @2);
Join
LOAD * FROM [https://community.qlik.com/thread/204080] (html, codepage is 1252, embedded labels, table is @3)
Where Exists(ID);
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
some test script to compare the performance of the different solutions:
//-------------------------
//test data generation
//
//T1:
//LOAD RecNo() as ID,
// Left(KeepChar(Hash256(Rand()),'ABCDEFGHIJKLMNOPQRSTUVWXYZ'),10) as Name
//AutoGenerate 100;
//STORE T1 into T1.qvd (qvd);
//
//T2:
//LOAD RecNo()+90 as ID,
// Left(KeepChar(Hash256(Rand()),'ABCDEFGHIJKLMNOPQRSTUVWXYZ'),10) as text
//AutoGenerate 100;
//STORE T2 into T2.qvd (qvd);
//
//T3:
//LOAD Ceil(Rand()*10000000) as ID,
// Left(KeepChar(Hash256(Rand()),'ABCDEFGHIJKLMNOPQRSTUVWXYZ'),10) as COM
//AutoGenerate 10000000;
//STORE T3 into T3.qvd (qvd);
//
//DROP Tables T1, T2, T3;
//-------------------------
//-------------------------
//Solution 1
//
//temp:
//LOAD * FROM T1.qvd (qvd);
//Join
//LOAD * FROM T2.qvd (qvd);
//Join
//LOAD * FROM T3.qvd (qvd);
//
//NoConcatenate
//
//[expected output]:
//LOAD * Resident temp
//WHERE Len(Trim(Name))>0 or Len(Trim(text))>0;
//
//DROP Table temp;
//-------------------------
//-------------------------
//Solution 2
//
//[expected output]:
//LOAD * FROM T1.qvd (qvd);
//Join
//LOAD * FROM T2.qvd (qvd);
//Left Join
//LOAD * FROM T3.qvd (qvd);
//-------------------------
//-------------------------
//Solution 3
//
//[expected output]:
//LOAD * FROM T1.qvd (qvd);
//Join
//LOAD * FROM T2.qvd (qvd);
//Join
//LOAD * FROM T3.qvd (qvd)
//Where Exists(ID);
//-------------------------
Graeme's solution using the Exists() function seems to be the fastest by far.
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From the sample data and requirements specified, there did not appear to be a need to handle duplicates across table one and two. As such, concatenating the tables will be much faster. If you need to handle duplicates across these files, then yes, you would have to join them, which would be much slower.
Regards,
Graeme
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As per my requirement
LOAD * FROM [https://community.qlik.com/thread/204080] (html, codepage is 1252, embedded labels, table is @1)
where Name = 'er'
;
Join
04.LOAD * FROM [https://community.qlik.com/thread/204080] (html, codepage is 1252, embedded labels, table is @2);
Join
LOAD * FROM [https://community.qlik.com/thread/204080] (html, codepage is 1252, embedded labels, table is @3)
Where Exists(ID);
T1 and T3 are having 20 millions of data
So I need to pull the records based on above conditions
But it is not working as expected.
- « Previous Replies
-
- 1
- 2
- Next Replies »