Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics & AI
- :
- Products & Topics
- :
- Visualization and Usability
- :
- Re: Help with Logic
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Help with Logic
Hi all ( stalwar1)
I have a question:
I have sthing like this:
Date1,2 and 3; and for every ID, I want to create a rank field, to rank the dates in ascending order; is there a way to do this? without long if else..?
and one remark: NOT ALL DATES are always there; u can find many IDs with one or many missing dates.
| ID | Date1 | Date2 | Date3 | Rank |
|---|---|---|---|---|
| 1 | 17/06/2017 | 15/01/2018 | 15/11/2016 | Date3 - Date1- Date2 |
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The most generic way would be the suggestion from Sunny and if there are no serious performance impacts I would probably go with it.
But it could be also resolved on a record-level with a comparing from each value against each value. This may seem a quite heavy scripting with many if-loops but it could also be done more elegant - and I think the following could be even more optimized maybe by using some (parametrized) variables or a better algorithm - and you don't need to split it in respectively keep all intermediate steps:
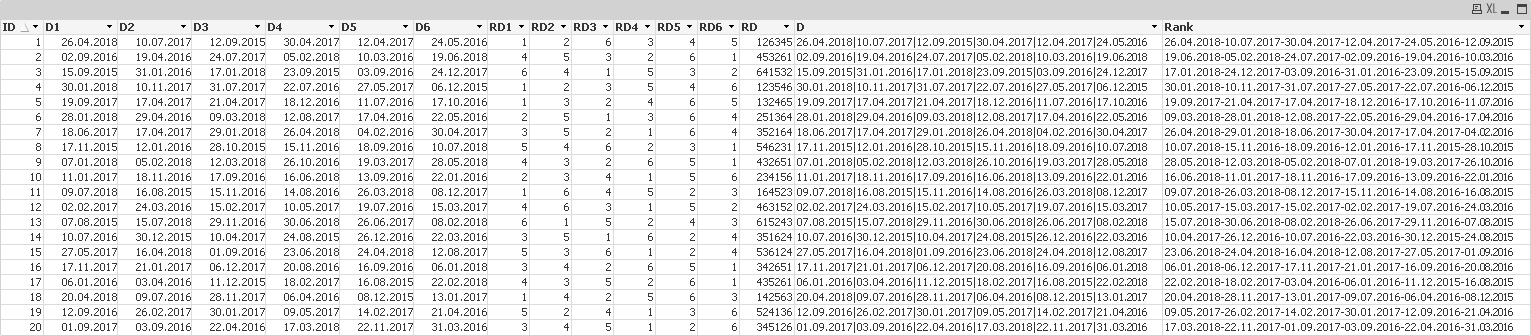
t1:
load
*,
subfield(D, '|', index(RD, 1)) &'-'&
subfield(D, '|', index(RD, 2)) &'-'&
subfield(D, '|', index(RD, 3)) &'-'&
subfield(D, '|', index(RD, 4)) &'-'&
subfield(D, '|', index(RD, 5)) &'-'&
subfield(D, '|', index(RD, 6)) as Rank;
load
*,
(rangesum(-(D1>D2),-(D1>D3),-(D1>D4),-(D1>D5),-(D1>D6))-6)*-1 as RD1,
(rangesum(-(D2>D1),-(D2>D3),-(D2>D4),-(D2>D5),-(D2>D6))-6)*-1 as RD2,
(rangesum(-(D3>D1),-(D3>D2),-(D3>D4),-(D3>D5),-(D3>D6))-6)*-1 as RD3,
(rangesum(-(D4>D1),-(D4>D2),-(D4>D3),-(D4>D5),-(D4>D6))-6)*-1 as RD4,
(rangesum(-(D5>D1),-(D5>D2),-(D5>D3),-(D5>D4),-(D5>D6))-6)*-1 as RD5,
(rangesum(-(D6>D1),-(D6>D2),-(D6>D3),-(D6>D4),-(D6>D5))-6)*-1 as RD6,
(rangesum(-(D1>D2),-(D1>D3),-(D1>D4),-(D1>D5),-(D1>D6))-6)*-1 &
(rangesum(-(D2>D1),-(D2>D3),-(D2>D4),-(D2>D5),-(D2>D6))-6)*-1 &
(rangesum(-(D3>D1),-(D3>D2),-(D3>D4),-(D3>D5),-(D3>D6))-6)*-1 &
(rangesum(-(D4>D1),-(D4>D2),-(D4>D3),-(D4>D5),-(D4>D6))-6)*-1 &
(rangesum(-(D5>D1),-(D5>D2),-(D5>D3),-(D5>D4),-(D5>D6))-6)*-1 &
(rangesum(-(D6>D1),-(D6>D2),-(D6>D3),-(D6>D4),-(D6>D5))-6)*-1 as RD
;
load *, recno() as ID, D1&'|'&D2&'|'&D3&'|'&D4&'|'&D5&'|'&D6 as D inline [
D1 D2 D3 D4 D5 D6
26.04.2018 10.07.2017 12.09.2015 30.04.2017 12.04.2017 24.05.2016
02.09.2016 19.04.2016 24.07.2017 05.02.2018 10.03.2016 19.06.2018
15.09.2015 31.01.2016 17.01.2018 23.09.2015 03.09.2016 24.12.2017
30.01.2018 10.11.2017 31.07.2017 22.07.2016 27.05.2017 06.12.2015
19.09.2017 17.04.2017 21.04.2017 18.12.2016 11.07.2016 17.10.2016
28.01.2018 29.04.2016 09.03.2018 12.08.2017 17.04.2016 22.05.2016
18.06.2017 17.04.2017 29.01.2018 26.04.2018 04.02.2016 30.04.2017
17.11.2015 12.01.2016 28.10.2015 15.11.2016 18.09.2016 10.07.2018
07.01.2018 05.02.2018 12.03.2018 26.10.2016 19.03.2017 28.05.2018
11.01.2017 18.11.2016 17.09.2016 16.06.2018 13.09.2016 22.01.2016
09.07.2018 16.08.2015 15.11.2016 14.08.2016 26.03.2018 08.12.2017
02.02.2017 24.03.2016 15.02.2017 10.05.2017 19.07.2016 15.03.2017
07.08.2015 15.07.2018 29.11.2016 30.06.2018 26.06.2017 08.02.2018
10.07.2016 30.12.2015 10.04.2017 24.08.2015 26.12.2016 22.03.2016
27.05.2017 16.04.2018 01.09.2016 23.06.2018 24.04.2018 12.08.2017
17.11.2017 21.01.2017 06.12.2017 20.08.2016 16.09.2016 06.01.2018
06.01.2016 03.04.2016 11.12.2015 18.02.2017 16.08.2015 22.02.2018
20.04.2018 09.07.2016 28.11.2017 06.04.2016 08.12.2015 13.01.2017
12.09.2016 26.02.2017 30.01.2017 09.05.2017 14.02.2017 21.04.2016
01.09.2017 03.09.2016 22.04.2016 17.03.2018 22.11.2017 31.03.2016
] (txt, delimiter is \t);
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is awesome marcus_sommer, thanks for sharing this. I guess the only issue I see with this is if that if somebody needs to add more date types, then there will be some work upfront to add the new date to the code in multiple places.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, you are right - in this way the code is quite static and in some cases additionally efforts will be needed to get the approach more dynamically whereby the number of date-fields shouldn't be a big problem because they could be counted and within a loop the code could be created on the fly. More complicated would be cases with NULL's or missing/invalid values or in which any other exceptions needs to be handled ...
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for this great work Marcus; I have a question though, would this work in case of NULL dates?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
With some more manipulation this should work with NULL as well... but did you not like the CrossTable/Concat approach? I thought you wanted to something generic 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Omar,
how about this? Is this what you are looking for?
RawData:
Load * Inline [
ID,Date1,Date2,Date3
1,17/06/2017,15/01/2018,15/11/2016
2,17/05/2017,15/08/2018,15/11/2019
];
temp:
CrossTable(DateType,Date,1)
load * Resident RawData;
left join (RawData)
Result:
load ID,Concat(DateType,'-',Date#(Date,'DD/MM/YYYY')) as Rank Resident temp group by ID;
drop table temp;
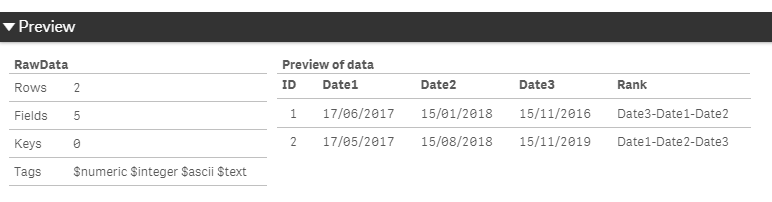
Hope it helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Did offered this same solution above, not sure why Omar doesn't like it
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In general I think it could. But it will need some additionally steps:

Here I removed 3 values - in D3 & D4 just a removing and in D2 I applied an alt(D2, 0) on the field. Only removing/cleaning the effects from the Rank field will be rather easy but if the ranking itself needs also to be adjusted in any way it might need some more efforts - so it will depend ...
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I was busy all day long with meetings.. did not have the time to test anything sunny; I'll test it once I'd have time; thank u everyone !
- « Previous Replies
-
- 1
- 2
- Next Replies »