Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView
- :
- Levenshtein Algorithm
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Levenshtein Algorithm
Dear All,
Does anyone try to apply Levenshtein algorithm in QlikView?
Your inputs are highly appreciated!!
Regards,
Omer
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am not hear about that can you explain more about the Levenshtein algorithm.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Omer,
This is indeed but just to let you know Levenshtein is not implemented yet in QlikView. Few months before I was wondering for a matrix which could be utilize to measure the period or distance between two things (Months, Days, Years or anything). I believe the most common way to calculate this is by dynamic approach, may be VB script, C# or Java program but this is not the feature of QlikView. I tried and played with variables but did not succeeded.
As of now there is no functions which fulfill levenshtein algorithm in QlikView till version SR6.
I marked this as a priority, as the need for such analysis is present in market.
I hope this is informative and hence request to mark this so other community users can get instant results of the post/questions.
Regards
Advait
https://www.linkedin.com/groups/6513382/
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Have a look at the second page of the second linked thread in my answer here:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Omer,
although it might not be the fastest solution (in terms of execution time), this application might help:
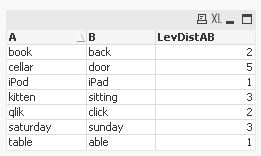

tabLevenshteinDistances:
LOAD
*,
levenshtein(A,B) as LevDistAB
Inline [
A,B
kitten,sitting
saturday,sunday
book,back
table,able
iPod,iPad
cellar,door
qlik,click
];
It's just a copy/paste-solution using a VBScript function found at wikibooks:
http://en.wikibooks.org/wiki/Algorithm_Implementation/Strings/Levenshtein_distance#VBScript
The reload execution time for a 1.000.000 rows xlsx table raised from 45sec to 2min 58sec when adding the levenshtein distance calculation.
hope it might be of any use though
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Here is result of my attempts to implement Levenshtein Algorithm 
I want to think about how to change the formulas to improve presentation:
- by transfer it to pivot ..
- by using Aggr ()
I think that there should be also possible to create some extension for it...
Regards
Darek
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here is version 3.
User may at the application level input string to search.
regards
Darek
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi guys,
Thanks a lot for the help.
It really help me.
Regards,
Omer
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
wow
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
29-04-2014 17:28 użytkownik "Marco Wedel" <qcwebmaster@qlik.com>
napisał:
Qlik Community <http://community.qlik.com/> Levenshtein Algorithm
reply from Marco Wedel<http://community.qlik.com/people/MarcoWedel?et=watches.email.thread>in
Scripting - View the full discussion<http://community.qlik.com/message/518811?et=watches.email.thread#518811>
- « Previous Replies
-
- 1
- 2
- Next Replies »