Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView
- :
- Synthetic keys >> sometimes a good idea?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Synthetic keys >> sometimes a good idea?
Hi Qlikview experts!
I'm hired by a company that uses qvw's of approx 3 gigabytes...
We have been thinking about optimizing reload-time (it is now about 35 minutes).
My colleague told me that it could be a wise idea to not always resolve synthetic keys, especially when it is about large QVW's.
So my questions are the following:
1: Is it true that (performance-wise) synthetic keys sometimes kan better be kept in the model? If so, why?
2: when are synthetic keys "wrong" (meaning that the data integrity is not guaranteed anymore)
I'm curious and couln't find much details for it (and I didn't do benchmarks yet). Hope you have inputs and perhaps benchmarks!
Roberto
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
My current personal opinion: Restating a lot of what's in this thread and the one I linked to, if your tables are properly linked by two fields, a synthetic key is one valid way to model this link. It is not in and of itself a data model error. It may or may not load or perform better than an equivalent composite key, depending on the situation. However, since a synthetic key is usually a symptom of a bad data model, you would want to document it as completely as possible, or the next person that sees your code will probably assume you made a mistake. A composite key, on the other hand, is self documenting. And often neither is the best approach, and the best approach is to use a different data model completely, one that doesn't require either sort of key.
My current personal advice: If you're a new developer, figure out WHY the synthetic key appeared, and then remove it. At worst, it's good data-modeling practice. If you're an experienced developer, and you're not SURE that a synthetic key is appropriate, then it isn't - remove it. If you're an experienced developer, and you're in a rush, and you KNOW that a synthetic key will work, go ahead, but remove it later. If you're an experienced developer, and you KNOW you have a good reason for having a synthetic key (such as if in this particular case it significantly improves load performance, and load performance is critical for the application), and you've actually taken the trouble to compare the alternatives, go ahead, but document it thoroughly, because otherwise that new developer is going to take my advice and remove it and undo all your hard work.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi,
As per my understanding and experience, Synthetic key doesn't effect the data integrity if your data linking is accurate.
It surley effects the reload time. If you observe when the application loading is completed it tries to create the synthetic key which takes time depending upon your data volume.
I have also observed reduction in performance at front end due to synthetic keys.
Hence i would personally advice to remove synthetic keys(where ever possible)
Deepak
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Roberto,
Take time to read this discussion: http://community.qlik.com/message/72118#72118
Regards,
Michael
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Since the initial post in that thread is corrupted, I suggest starting at this point, where I reposted the initial post, and then continuing again from the top:
http://community.qlik.com/thread/10279?start=30&tstart=0
Edit: My personal final conclusion from the thread was this: "Sometimes a synthetic key is better. Sometimes a composite key is better. It depends on the situation and on what you're trying to optimize (RAM vs. load time, for instance)." Not very useful as a recommendation, of course, but isn't the correct answer to difficult questions always "it depends"?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
To continue that old discussion, I'd say that synthetic keys can be considered as "good" only for one thing - to save the development time that one should spend to clean them up. This approach can pass for a "quick and dirty" solution for a small data set.
People that deal with large data sets, absolutely have to do better than keep the synthetic keys in their databases.
I can't possibly imagine a situation in which a synthetic key could improve performance in any way. Please do me a favor and show me a real-life example of how a synthetic key can perform better than a well-constructed data model.
cheers,
Oleg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would NEVER have synthetic keys in ANY of my documents, large or small. I read through the thread referenced above some time ago and whilst I would accept the possibility that there may be situations in which they perform slightly better than deliberately constructed composite keys (that do the same thing), as far as keeping a neat and tidy data model that can be understood by people other than the developer that wrote it goes - it's a HUGE no!
There are a few things that are incredibly vital to a successful QV environment, including (but by no means limited to):
- Well constructed data models that can be understood on first sight.
- Best practices in scripting and expression building
- Well commented, easy to understand coding
Synthetic keys certainly break rules 1 and 3 above (and I would argue 2). If John's measurments hold true in most environments (and I have no reason to suspect they wouldn't) and if you need to squeeze out that bit more performance - upgrade the hardware. Don't sacrifice a good, clean, well-intended model - it's a false economy as hardware is cheap and developer-time (which would be needed to maintain a model with synthetic keys) is not.
Finally, although there may be times and arguments for deliberately having synthetic keys in one's model - my experience is it is generally down to poor coding.
Jason
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would NEVER have synthetic keys in ANY of my documents, large or small. I read through the thread referenced above some time ago and whilst I would accept the possibility that there may be situations in which they perform slightly better than deliberately constructed composite keys (that do the same thing), as far as keeping a neat and tidy data model that can be understood by people other than the developer that wrote it goes - it's a HUGE no!
There are a few things that are incredibly vital to a successful QV environment, including (but by no means limited to):
- Well constructed data models that can be understood on first sight.
- Best practices in scripting and expression building
- Well commented, easy to understand coding
Synthetic keys certainly break rules 1 and 3 above (and I would argue 2). If John's measurments hold true in most environments (and I have no reason to suspect they wouldn't) and if you need to squeeze out that bit more performance - upgrade the hardware. Don't sacrifice a good, clean, well-intended model - it's a false economy as hardware is che4p and developer-time (which would be needed to maintain a model with synthetic keys) is not.
Finally, although there may be times and arguments for deliberately having synthetic keys in one's model - my experience is it is generally down to lazy coding.
Jason
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
Thanks for all your input.
From what I have read so far, the load-time-improvement does not seem to be very significant...
My colleague heard of a qvw that was reloaded much faster with synthetic keys. I'll ask her for details (I thought an improvement from 60 minutes to 30 minutes or something like that).
When such improvements are true, I'd choose for syn-keys sometimes. If there are similar experiences (or experiences against this) I'd like to hear.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Oleg Troyansky wrote:
I can't possibly imagine a situation in which a synthetic key could improve performance in any way. Please do me a favor and show me a real-life example of how a synthetic key can perform better than a well-constructed data model.
Well, hmmm.
I looked through my largest applications for synthetic keys to try to find such an example. I found a large application with a synthetic key, but even on brief glance I could see that a composite key should load faster. You see, first the application builds a sort of source table. Then it builds two new tables from that source table. All three remain in the data model, connected by two fields - a synthetic key. It should be more efficient to build a composite key ONCE, on the first table, and then copy only that key instead of the two fields onto the other two tables. (The other two tables have additional key fields by the time they're done, so cannot simply be merged with the source table.)
OK, I've now modified the script. Here are the results of two loads each (after a couple "warmup" loads):
composite key 8:41, 9:11
synthetic key 9:06, 8:13
So the synthetic key looks faster, but the margin of error at this point is large. The synthetic key itself appears to take about 10 seconds to create. That's somewhat less than the margin of error between the runs, and I can't just run these two all day long to see which is really better. But I'd bet that the composite key is faster here on average, even if not significantly so. And if not here, surely there is some case like this one where it IS faster.
So now I know of two cases where a composite key can be faster than a synthetic key:
- Incrementally loaded QVDs - a composite key would only need to be created once, while a synthetic key would have to be created on every load of the user application
- Tables loaded from the same source - a composite key would only need to be created on one table, while a synthetic key would be created on all such tables
I'm not saying there aren't other cases. These are just the two I know of.
Unfortunately, I think the few other applications I have synthetic keys in are all small data sets, where the time required to load the synthetic key would be insignificant (not that 10 seconds is significant), and the differences between synthetic and composite keys would be undetectable. So I can't provide a real-life example. I'm not saying they don't exist - I believe they do - I just don't have any from our company. All I have are fake examples built on random data, which I'll admit aren't really the same thing.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jason Michaelides wrote:
There are a few things that are incredibly vital to a successful QV environment, including (but by no means limited to):
- Well constructed data models that can be understood on first sight.
- Best practices in scripting and expression building
- Well commented, easy to understand coding
Synthetic keys certainly break rules 1 and 3 above (and I would argue 2).
1. Well constructed data models that can be understood on first sight.
A synthetic key table IS a composite key table, just one built by QlikView instead of manually, so I'd say the data model is no better or worse constructed - it's essentially the same data model. As far as it being understood on first sight, I think a synthetic key in the source table view is more easily undersood than a composite key. It is admittedly less clear in the internal table view, but I don't recommend using that view unless you're specifically trying to see what QlikView is doing internally. (Yes, these two tables could be concatenated or outer joined, which might be a better solution here. But if they had more fields, and those fields were not common, I'd personally just leave the synthetic key.)
Synthetic key - two data tables clearly connected by two fields:
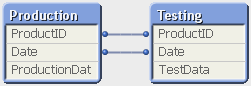
Composite key - takes a longer look to figure out what's going on:

Edit: Actually, I'm going to concede the "understood on first sight" point. I don't like how the source table view looks when you have more than two tables connected, particularly by multiple fields. I personally prefer the internal table view of synthetic keys, which is admittedly less clear on first sight. I almost always use the internal table view. For me to say "nuh uh, synthetic keys look better" based on a non-default view that I don't use and that only looks better for two tables may have been disingenuous. To recommend that people use a view that I rarely use is perhaps a bad idea, even if it may be more clear in some cases. While I do like how synthetic keys look in the internal table view, it's probably only because I've been looking at them that way for years and got used to it. It probably is less clear to most people than a composite key.
3. Well commented, easy to understand coding
I think this favors synthetic keys - no code vs. extra code, like using a sort() function in some language rather than coding your own. Is there a cleaner way to build the composite key than the below? I know I could squeeze more onto one line, but this is the actual spacing I'd use in my actual applications. There may be simpler code, but I can't imagine code that's easier to understand than merely loading the two tables like we do with the synthetic key. If you understand that connections between QlikView tables are by field name, then you understand how the scripted tables will link - by two fields. Maybe this is an atypical example of a composite key, but I suspect this is actually a fairly typical example of one.
Synthetic key:
Production:
LOAD
recno() as ProductID
,makedate(2012,7,recno()) as Date
,ceil(rand()*100) as ProductionData
AUTOGENERATE 20
;
Testing:
LOAD
recno() as ProductID
,makedate(2012,7,10+recno()) as Date
,ceil(rand()*100) as TestData
AUTOGENERATE 20
;
Composite key:
Production:
LOAD *
,autonumber(ProductID&':'&Date) as Composite
;
LOAD
recno() as ProductID
,makedate(2012,7,recno()) as Date
,ceil(rand()*100) as ProductionData
AUTOGENERATE 20
;
Testing:
LOAD *
,autonumber(ProductID&':'&Date) as Composite
;
LOAD
recno() as ProductID
,makedate(2012,7,10+recno()) as Date
,ceil(rand()*100) as TestData
AUTOGENERATE 20
;
Composite:
LOAD
Composite
,ProductID
,Date
RESIDENT Production
;
OUTER JOIN
LOAD
Composite
,ProductID
,Date
RESIDENT Production
;
DROP FIELDS
ProductID
,Date
FROM
Production
,Testing
;
Jason Michaelides wrote:
If John's measurments hold true in most environments (and I have no reason to suspect they wouldn't) and if you need to squeeze out that bit more performance - upgrade the hardware. Don't sacrifice a good, clean, well-intended model - it's a false economy as hardware is che4p and developer-time (which would be needed to maintain a model with synthetic keys) is not.
I agree that developer time is expensive and that we shouldn't sacrifice a good, clean, well-intended data model. And that's why I don't think developers should spend their time building and maintaining data structures (composite key tables) that QlikView can build and maintain for them. It's one more table to maintain in the script. It's one more table to look at in the data model. There can be legitimate reasons for building composite keys yourself (I mention two in the previous post) but I don't think it should be the DEFAULT choice, or even worse, the ONLY accepted choice. Take advantage of the power of the product to simplify development and maintenance.
Jason Michaelides wrote:
Finally, although there may be times and arguments for deliberately having synthetic keys in one's model - my experience is it is generally down to lazy coding.
Bad coding, yeah, I agree. Making up a number, 93.735% of synthetic keys show up accidentally as a symptom of a bad data model. Very few synthetic keys were both intended by the developer and are the best choice for the application. As a result, the primary use of synthetic keys for the vast majority of developers will be to help identify data model mistakes that they should fix, and fixing those mistakes will also usually remove the synthetic keys. But to me that's not the same thing as agreeing that we should never use synthetic keys, and always remove them when they appear. They're just a tool. In a data model where you should legitimately connect two tables by more than one field, and you can choose between equivalent composite and synthetic keys, I think synthetic keys are simpler and clearer. So I favor them for much the same reason that you favor composite keys. We are perhaps merely disagreeing on what is simpler and clearer.
- « Previous Replies
-
- 1
- 2
- Next Replies »