Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Happy Tuesday everyone!. You guys are going to love this one. In this edition of the Qlik Design Blog, our Emerging Technology Evangelist, David Freriks is back discussing integration between Qlik and a powerful big data unstructured search platform called Solr. Not only does David discuss an out-of-the-box approach to this integration, he takes it to the next level and touts the power of the Qlik Platform APIs.
Solr
In case you haven’t seen it – there is a super powerful unstructured search platform used within the big data ecosystem called Solr, built on the Apache Lucene search engine library. What’s great about Solr is that it can index just about anything, text, xml, JSON, PDF, Word, Excel, including almost any kind of text based data. That means you can drop just about anything into Solr and make it searchable using the power of Lucene core which powers the Solr platform.
So, where does Qlik fit in you may ask? Well, let’s observe what a Solr query output looks like:
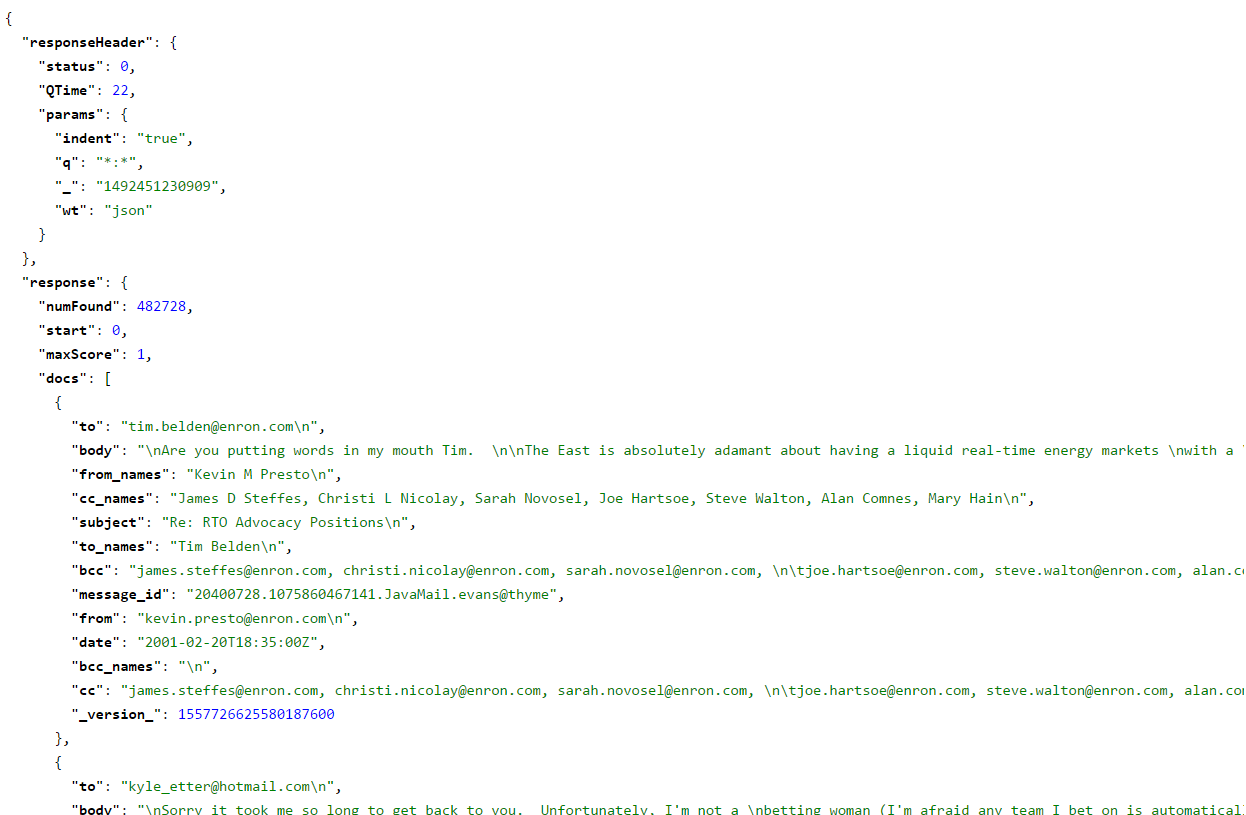
Standard Solr query output
Hmmm, not very user friendly, not to mention it was somewhat slow to execute. Here is a little bit about what we’re looking at:
- This data is the collective set of Enron emails from its infamous collapse in early 2000’s.
- We’ve loaded this data set into our Cloudera cluster and indexed it using Solr.
- Once this data was loaded and indexed we tested with a series of queries.
- A full query on someone with a lot of references such as Ken Lay can run upwards of 15 minutes to bring back every email that contains a reference to him.
Imagine 10’s or 100’s of users each waiting 10-15 minutes for a single question to be answered, it clearly dilutes the effectiveness of the engine as a business tool.
Enter Qlik
Qlik has a tremendously powerful REST connector that is perfectly suited for connecting to sources such as Solr. (A great resource created by Mike Tarallo on the Qlik REST connector can be found here: Working with the Qlik REST Connector, Pagination and Multiple JSON Schemas - check it out to understand the basics of how it works and how the response data is assembled within Qlik)
What follows is how we are using the Qlik REST Connector to connect to Solr.
Qlik In-Memory Analytics with Solr
Now that we are armed with the Qlik REST Connector, and the appropriate Solr REST API connection parameters, we can pull the entire Enron email data set into the Qlik engine via Solr. (Refer to the Apache Solr Documentation to learn more,)
 Qlik REST Connector configuration
Qlik REST Connector configuration
By pulling the entire data set, and loading it into Qlik, we now ensure that all users have sub-second access to all the data down to the most granular level, and thanks to our associative search technology – all the data has been indexed and correlated in-memory. We can gain further insights by incorporating stock market data. Combining Enron’s stock performance with their emails tells an interesting story of rising email volume along with collapsing stock prices and elevating trade volumes.
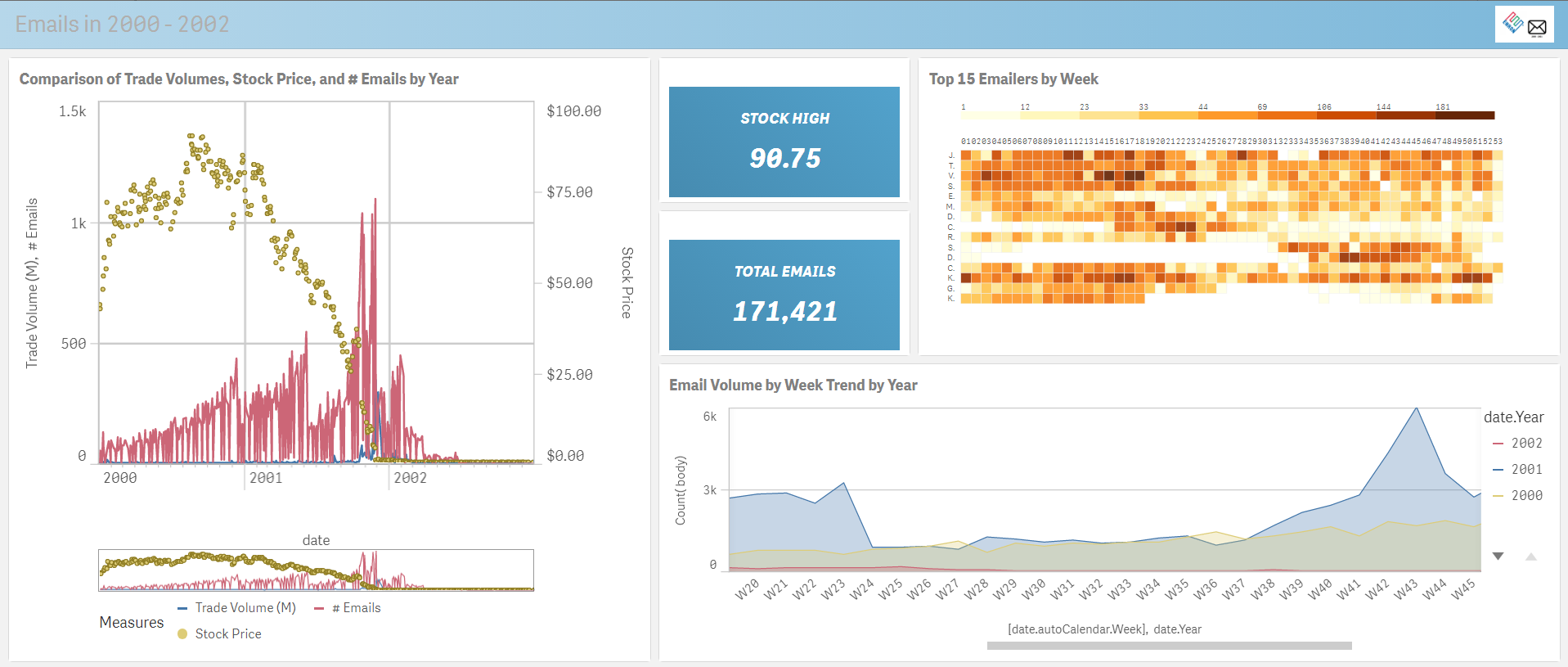
Power of Qlik Data Visualization - Enron stock performance correlated with email volume
Using a mix of visualization techniques, we can see a pretty interesting collection of data, including the famous “deleted emails” gap on the bottom right chart.
Performing some additional analysis, we can drill in on the height of the crash that also correlates with the spike in email volume, followed by a rapid drop in volume.
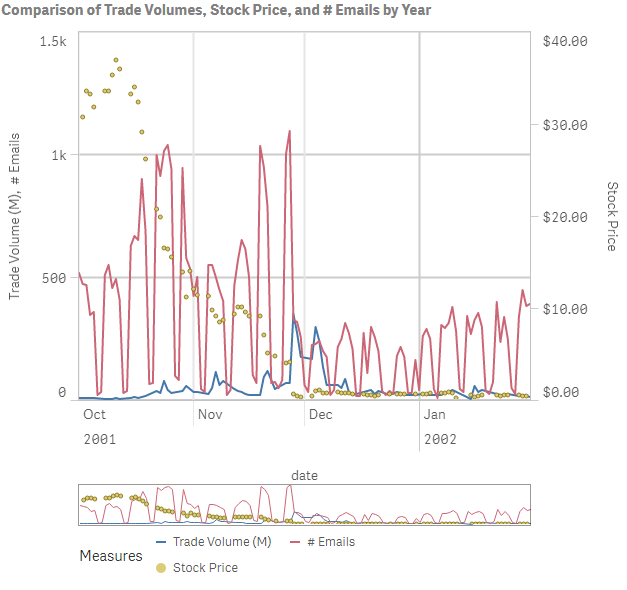 Drop in trade volume
Drop in trade volume
Making a few more selections we can dive down into a specific name, or comment to filter down the result sets further.
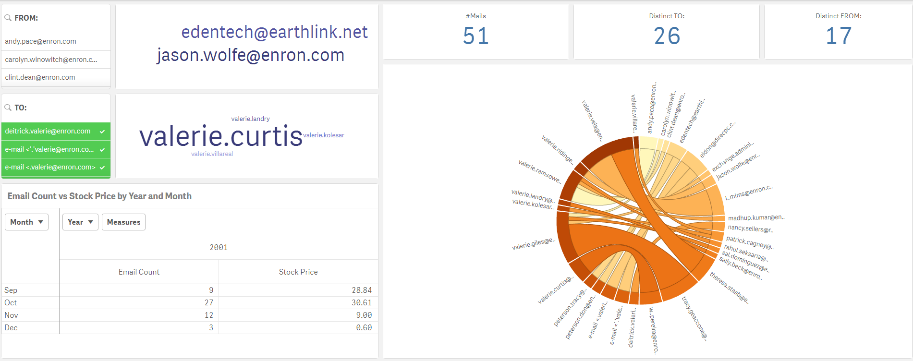 Detail and specifics - name, email address
Detail and specifics - name, email address
This associative search allows us to dive down into the details of the “TO” elements of the data set and see the metrics affiliated with those names. We can also jump over to the final sheet of the Qlik Sense app and look at the individual emails body content filtered by our prior selections made in the application.
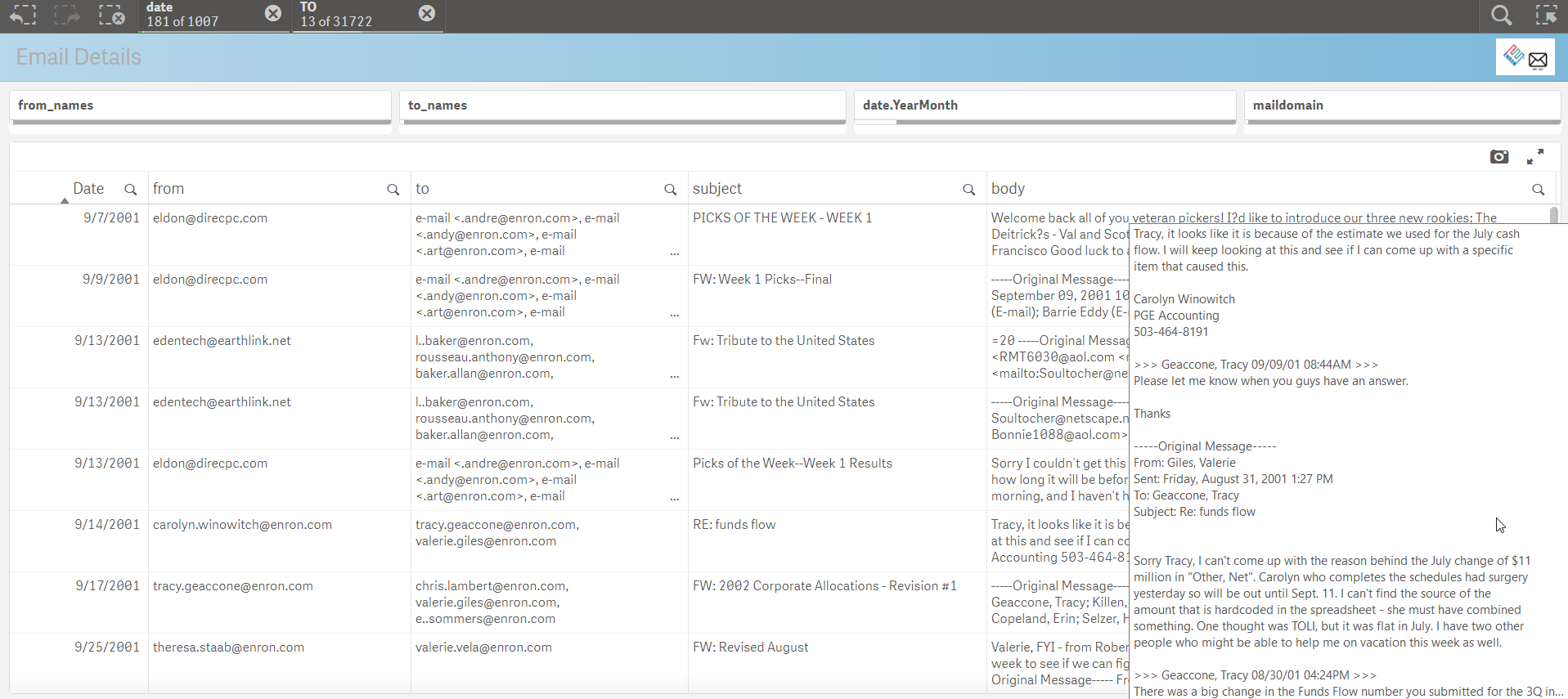
QIX API Powered Solr Search
The above approach of using Qlik in-memory to front end the Solr search engine is just one of the many ways Qlik can access unstructured data in big data systems. Let’s consider another application also using Qlik with Solr – this time with just the Qlik API’s. As a quick refresher, the Qlik engine (called QIX) is a fully API enabled engine with tremendous extensibility that allows Qlik to plug into any web based technology (like Solr). Using the awesome QlikSocial framework from the esteemed Johannes Sunden he adapted the webapp to connect to Solr on demand and build a full webapp from scratch. This is a great example of what we call Custom Analytics.
We start with a search box… And our name(s) of interest:
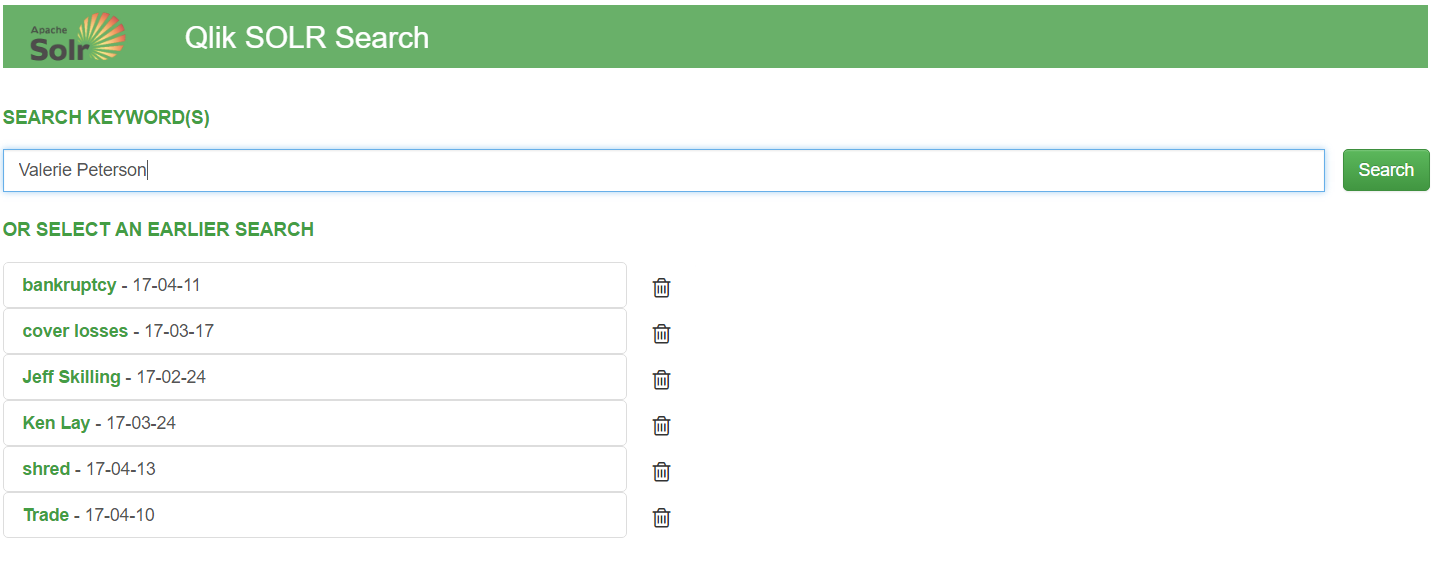
Now unlike the formatted Qlik Sense app, when a user hits the “search” bar – everything will happen dynamically on the fly using the API’s.
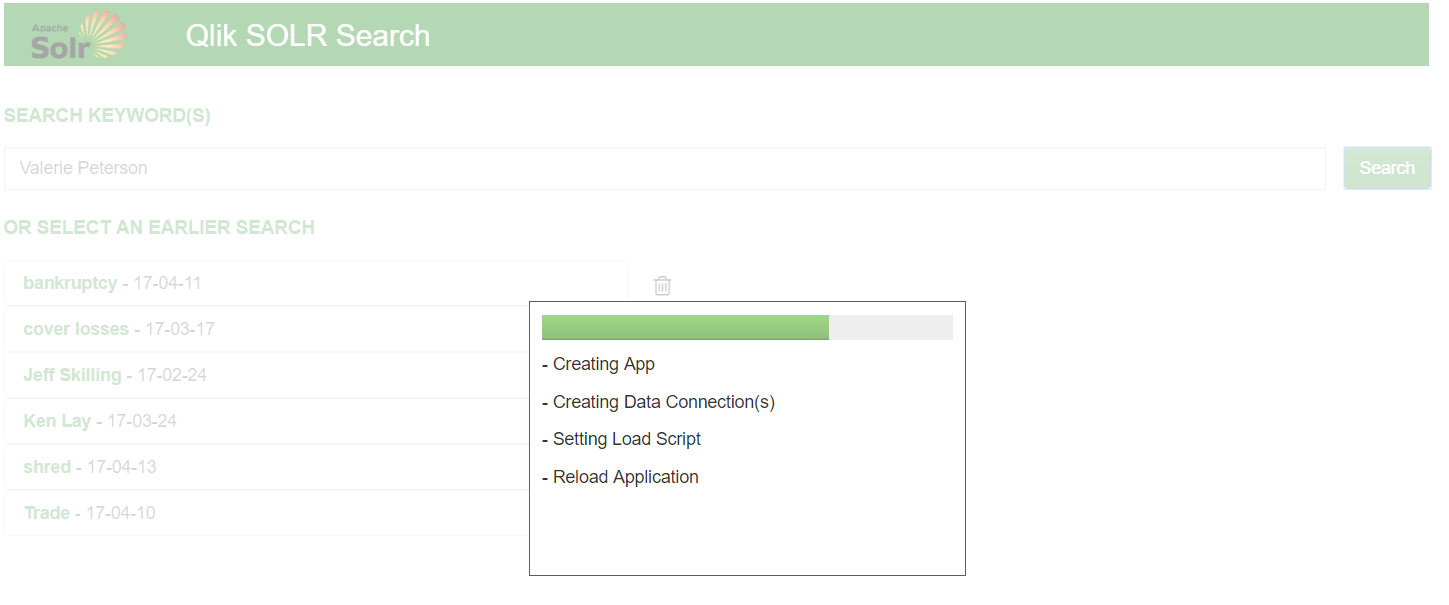
Qlik will dynamically generate a REST connection to Solr, create and load the requesting data into memory, and then build a web app around the data using bootstrap.js and angular.
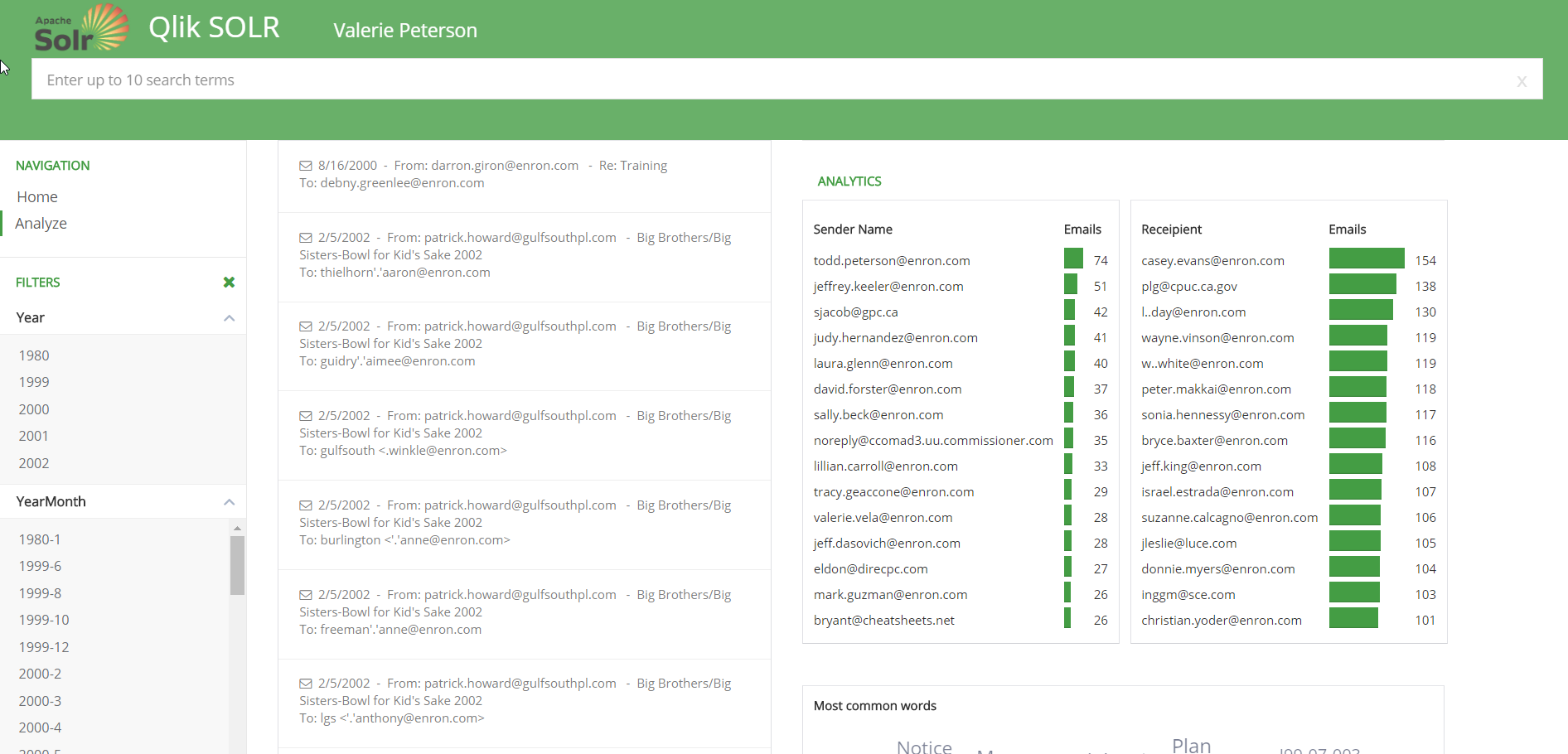
The webapp is still using the Qlik engine, so selections and the search engine are still available – but all the charts and graphics are html and d3js charts – not Qlik. We’re just powering the app and the data interactivity with the QIX engine!
Summary
Solr is an extremely powerful unstructured search engine that can benefit from the speed and structure of Qlik analytics. It can provide a focusing lens on the core Solr search technology. That data can be consumed in a number of formats including a completely structured Qlik Sense app, or as an API powered web application without any Qlik UI components.
For more information, visit our demo site at cloudera.qlik.com
Enjoy!
Regards,
David Freriks (@dlfreriks) | Twitter
Emerging Technology Evangelist
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.