Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics & AI
- :
- Products & Topics
- :
- App Development
- :
- Re: Merge files in load editor
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Merge files in load editor
Hi,
I currently have 3 data sources,
1: (Name, Line Manager, Line manager-1, DOB, Age, Age Grp)
2: (OPR 2017)
3: (OPR 2018)
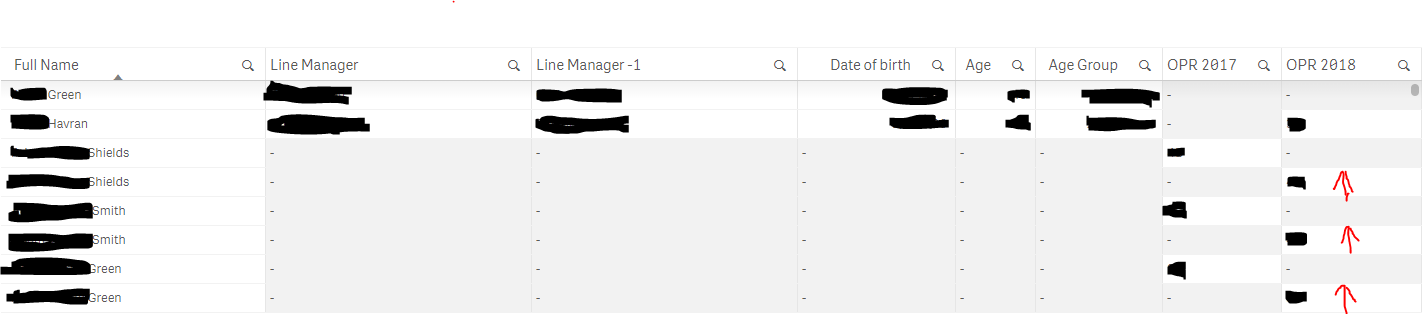
Now 1 merges fine with 2 and 3 separately, but 2 and 3 still distinct themselves.
Due to this, every person shows up twice, once with OPR 2017 and once with OPR 2018
What syntax would I have to use to combine the 2 of these into one row within the Data Load Editor.
I know that it is possible in an expression, but I specifically need it for the data load editor.
Thanks.
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try to make only the columns that you think should be equal to match column names.
This happens because you want two informations from the same line. The program sees that, and to not lose data, it makes separate lines.
Like this:
OPR 2017
load *, keepchar("Last Published OPR Rating 2017",'4A4B3A3B21A1B') as "OPR 2017";
LOAD
"Employee Global ID" as "Global ID",
Capitalize(Name) as "Full Name",
"Position Title of Record 2017",
"Summary Competency Rating - Numeric Value 2017",
"Summary Competency Rating - Scale Value 2017",
"Preliminary OPR Rating 2017",
"Last Published OPR Rating" as "Last Published OPR Rating 2017",
//"Year", // you don't need this anymore
"Plan Name",
"Review Period Start Date 2017",
"Review Period End Date 2017",
"Final Evaluation Workflow State 2017"
FROM [lib://AttachedFiles/OPR 2017.xlsx]
(ooxml, embedded labels, table is [OPR 2017]);
Another approach would be to create another table that understands that it is the same person, like this:
//Load a list of names from any table:
new_table:
LOAD
2017 as Year1,
2018 as Year2,
"Employee Global ID" as EmployeeID
resident "OPR 2017";
So, the problem with your data is that Qlik can't group lines if it will lose data. And it tries to when the column names are the same.
The first approach with change the names to fix that.
The second will create another table and make a correlation between all the tables possible.
I hope this helps.
Like, mark as helpful, mark as the answer. It helps a lot!
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The best practice is with the data load, so you are in the right track!
can you say a bit more about the OPR table? then i will be able to post a example script.
But as you would expect it is done by an if statement.
Like, mark as helpful if it is, it helps a lot!
thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Robin,
If I understand what you're trying to do, you need to handle the data a bit differently.
You need to concatenate both of the OPR data sources, they are your fact table, and leave the first table as a dimension that connects to the fact table.
There is no need to connect all the data to one big flat table, unless you're facing performance issues.
This should be the result ERD for your scenario
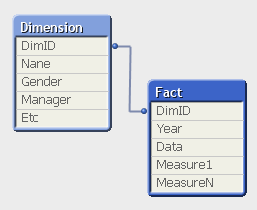
If you still wish to get one flat table:
Fact:
Load * from OPR_2017.qvd (qvd);
concatenate
Load * from OPR_2018.qvd (qvd);
join
Load * from Dimension_Table.qvd (qvd);
I hope it helps,
Eliran.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So all 3 files are connected through a global ID and name.
The OPR scores show :
Global ID, Name, OPR Score 2017
Global ID, Name, OPR Score 2018
Currently "Smith" shows up in 2 rows, once with OPR 2017 and once with 2018.
I would like to have 1 row for Smith having 1 dimension for 2017 and 1 for 2018.
I hope that is clear enough, let me know if you need anymore info.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
use rowno() funtion in 2 tables as a ID field and join with ID or Associate it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So all 3 files are connected through a global ID and name.
The OPR scores show :
Global ID, Name, OPR Score 2017
Global ID, Name, OPR Score 2018
Currently "Smith" shows up in 2 rows, once with OPR 2017 and once with 2018.
I would like to have 1 row instead of 2 for Smith having 1 dimension for 2017 and 1 for 2018.
Where would these QVD files come from that you mentioned?
This is how my current script looks:
OPR 2017
load *, keepchar("Last Published OPR Rating 2017",'4A4B3A3B21A1B') as "OPR 2017";
LOAD
"Employee Global ID" as "Global ID",
Capitalize(Name) as "Full Name",
"Position Title of Record",
"Summary Competency Rating - Numeric Value",
"Summary Competency Rating - Scale Value",
"Preliminary OPR Rating",
"Last Published OPR Rating" as "Last Published OPR Rating 2017",
"Year",
"Plan Name",
"Review Period Start Date",
"Review Period End Date",
"Final Evaluation Workflow State"
FROM [lib://AttachedFiles/OPR 2017.xlsx]
(ooxml, embedded labels, table is [OPR 2017]);
OPR 2018
load *, keepchar("Last Published OPR Rating 2018",'4A4B3A3B21A1B') as "OPR 2018";
LOAD
"Employee Global ID" as "Global ID",
Capitalize(Name) as "Full Name",
"Position Title of Record",
"Summary Competency Rating - Numeric Value",
"Summary Competency Rating - Scale Value",
"Preliminary OPR Rating",
"Last Published OPR Rating" as "Last Published OPR Rating 2018",
"Year",
"Plan Name",
"Review Period Start Date",
"Review Period End Date",
"Final Evaluation Workflow State"
FROM [lib://AttachedFiles/OPR 2018.xlsx]
(ooxml, embedded labels, table is [OPR 2018]);
I hope that is clear enough, let me know if you need anymore info.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try to make only the columns that you think should be equal to match column names.
This happens because you want two informations from the same line. The program sees that, and to not lose data, it makes separate lines.
Like this:
OPR 2017
load *, keepchar("Last Published OPR Rating 2017",'4A4B3A3B21A1B') as "OPR 2017";
LOAD
"Employee Global ID" as "Global ID",
Capitalize(Name) as "Full Name",
"Position Title of Record 2017",
"Summary Competency Rating - Numeric Value 2017",
"Summary Competency Rating - Scale Value 2017",
"Preliminary OPR Rating 2017",
"Last Published OPR Rating" as "Last Published OPR Rating 2017",
//"Year", // you don't need this anymore
"Plan Name",
"Review Period Start Date 2017",
"Review Period End Date 2017",
"Final Evaluation Workflow State 2017"
FROM [lib://AttachedFiles/OPR 2017.xlsx]
(ooxml, embedded labels, table is [OPR 2017]);
Another approach would be to create another table that understands that it is the same person, like this:
//Load a list of names from any table:
new_table:
LOAD
2017 as Year1,
2018 as Year2,
"Employee Global ID" as EmployeeID
resident "OPR 2017";
So, the problem with your data is that Qlik can't group lines if it will lose data. And it tries to when the column names are the same.
The first approach with change the names to fix that.
The second will create another table and make a correlation between all the tables possible.
I hope this helps.
Like, mark as helpful, mark as the answer. It helps a lot!
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you very much.
That did the trick, I also understand the issue now. thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
1 more question.
So now everything is nicely merged, I have one more preference.
Currently in the OPR files I have some people that should no longer appear in the results.
Only the people from the 1st data source with name etc.. should show up in the list.
As I am using the data load editor I am unable to make associations in the data manager.
How can I edit my data load to only show the people from the first data source, and where applicable show the matching OPR scores if they are present in both the 1st data source and the OPR score list.
Thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
On the LOAD editor,
add a line like this:
"Employee Global ID" as IDfrom2017,
With this you will have IDs from a unique column from each table. Then you can use it in your code :
if ( IDfrom2017 <> null() , DO TRUE, DO FALSE )
I hope this helps.
Like, mark as helpful, mark as the answer. It helps a lot!
Thanks
- « Previous Replies
-
- 1
- 2
- Next Replies »