Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Blogs
- :
- Technical
- :
- Design
- :
- Basics for complex authorization
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
In the simplest case, the authorization table defining who-gets-to-see-what is just a two column table linking user names to e.g. regions. But sometimes you need a more complicated logic. It could be that you have users that are allowed to see all products but just within one region, and at the same time all regions but just for one product. In other words, you want to make the reduction in several fields with the possibility of OR-logic.
QlikView can do this and here’s how you do it:
- Create an authorization table by loading the authorization data into QlikView after concatenating the reducing fields into one single generic authorization key:
Load USER, REGION &'|'& PRODUCT as %AuthID From AuthTable ;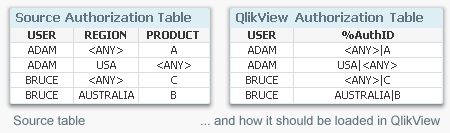
- Create an authorization key in the table with the most detailed transactions:
Load *, Region &'|'& Product as AuthID From OrderDetails ;
If you don’t have all the necessary keys in the table, you can fetch fields from other tables using Applymap. See more about Applymap here: - Create an authorization bridge table linking the two above tables. Since the %AuthID field can contain generic symbols such as '<ANY>', several load statements are needed to create the bridge table:
Load Region &'|'& Product as AuthID, Region &'|'& Product as %AuthID From OrderDetails ;
Load Region &'|'& Product as AuthID, Region &'|'&'<ANY>' as %AuthID From OrderDetails ;
Load Region &'|'& Product as AuthID, '<ANY>'&'|'& Product as %AuthID From OrderDetails ;
Load Region &'|'& Product as AuthID, '<ANY>'&'|'&'<ANY>' as %AuthID From OrderDetails ;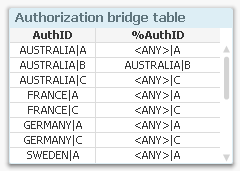
- Reduce the file on the USER field using either Section Access or QlikView Publisher.
Using the above method you can create quite complex security models. For instance, you can use generic symbols also for product groups. Read more about generic keys in this Technical Brief.
Good luck!
Further reading related to this topic:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.