Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Blogs
- :
- Technical
- :
- Design
- :
- Creating Reference Dates for Intervals
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Last week I wrote about how to create reference dates for exchange rates and warehouse balances: How to populate a sparsely populated field.
There is however also a second case where you want to create reference dates, but the data model is quite different. It is when you have a list of contracts with validity periods: Rental contracts, Insurances policies, Healthcare commitments, etc.
Each contract has a begin day and an end day. The analysts of an insurance company would probably want to ask the question: “How many valid insurance policies did we have on this specific day?” In other words, he wants to click on a reference date to see the count of policies that are associated with this date – even though this date doesn't exist in the source data.
The solution is to first load all policies in one table. Then load a second table that has one record per policy and date (Policies_x_Dates). This second table can in turn link to a master calendar.
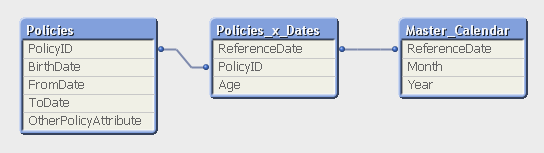
But the middle table does not exist in the source database. Instead, you must generate it using a While loop that loops over each record in the Policies table, i.e. each source record will be loaded several times. This way, you can load not only the “From” date and the “To” date, but also all dates in between:
Policies:
Load PolicyID, BirthDate, PolicyAmount, FromDate, ToDate, OtherPolicyAttribute
From Policies;
Policies_x_Dates:
Load PolicyID,
Age( FromDate + IterNo() – 1, BirthDate ) as Age,
PolicyAmount / (ToDate - FromDate + 1) as DailyAmount,
Date( FromDate + IterNo() – 1 ) as ReferenceDate
Resident Policies
While IterNo() <= ToDate - FromDate + 1 ;
Note that the Policies table has exactly one record per insurance policy, and the newly created Policies_x_Dates table has exactly one record per combination of policy and date. Note also that there are other fields that should be put in the Policies_x_Dates table, e.g., the age of the insured person, since this depends on the reference date. Further, it is possible to break up a cost or an income into daily amounts, which is useful when you want to show the correct amount distributed over the year.
The While loop is a very useful tool whenever you need to create additional tables in the data model. It is often a better option than the IntervalMatch.
Read more in Generating Missing Data In QlikView.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.