Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Cumulative % in Pivot table and QV Applicatio...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Cumulative % in Pivot table and QV Application not Utilizing full CPU
Dear All,
i have very big amount of data and below is the syntax for cumulative % calculation in a Pivot table for each column Dimension:
Cum% Expression is a below
=RangeSum(above(Count(DISTINCT ORDKEY),0,RowNo())) / Bottom(RangeSum(above(Count(DISTINCT ORDKEY),0,RowNo()))) *100
* Cumulative Count of Orders / Cumulative Count of Orders bottom value *100 . so i get the Cumulative %
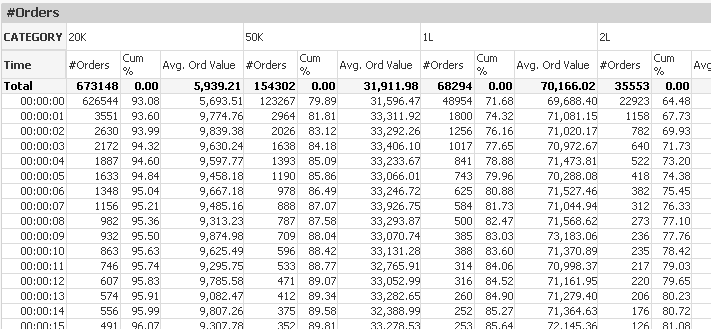
The Cumulative Calculation is taking large time because i have around 30 lakh record.
when i am viewing the CPU Utilization then it is not going beyond 25% -27%
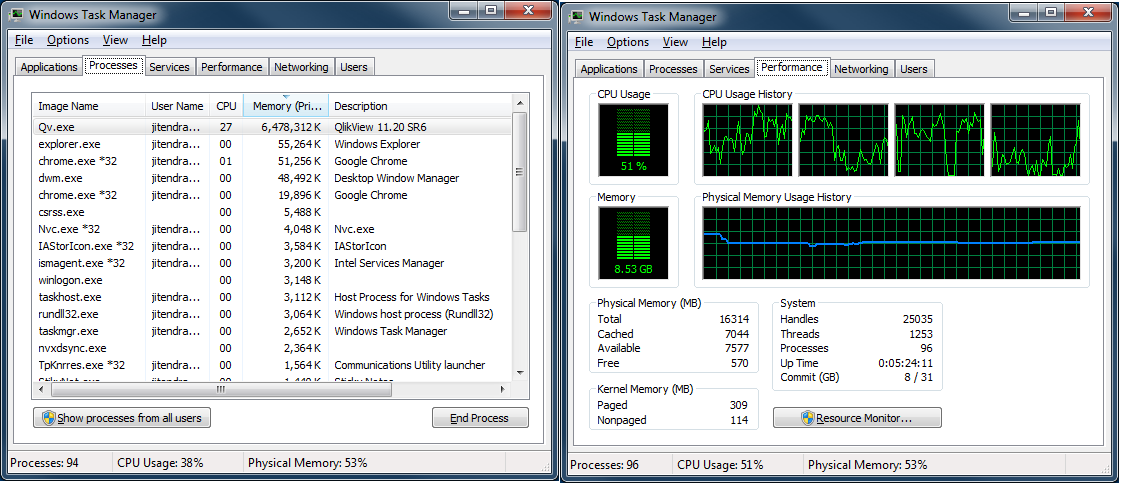
What needs to be done.
Kindly help.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The 25% is because of a single thread operation (100%/4cores=25%)
What is the datamodel like ?
Also see Quick Tips #5 - Expressions, count(distinct <fieldname>)
"It is not count(distinct <fieldname> that is single-threaded but the fact that fields often uses with this function are often located in distant tables, in the data model."
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can any one help me how to write optimized Expression for Cumulative % in Pivot table
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The 25% is because of a single thread operation (100%/4cores=25%)
What is the datamodel like ?
Also see Quick Tips #5 - Expressions, count(distinct <fieldname>)
"It is not count(distinct <fieldname> that is single-threaded but the fact that fields often uses with this function are often located in distant tables, in the data model."
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
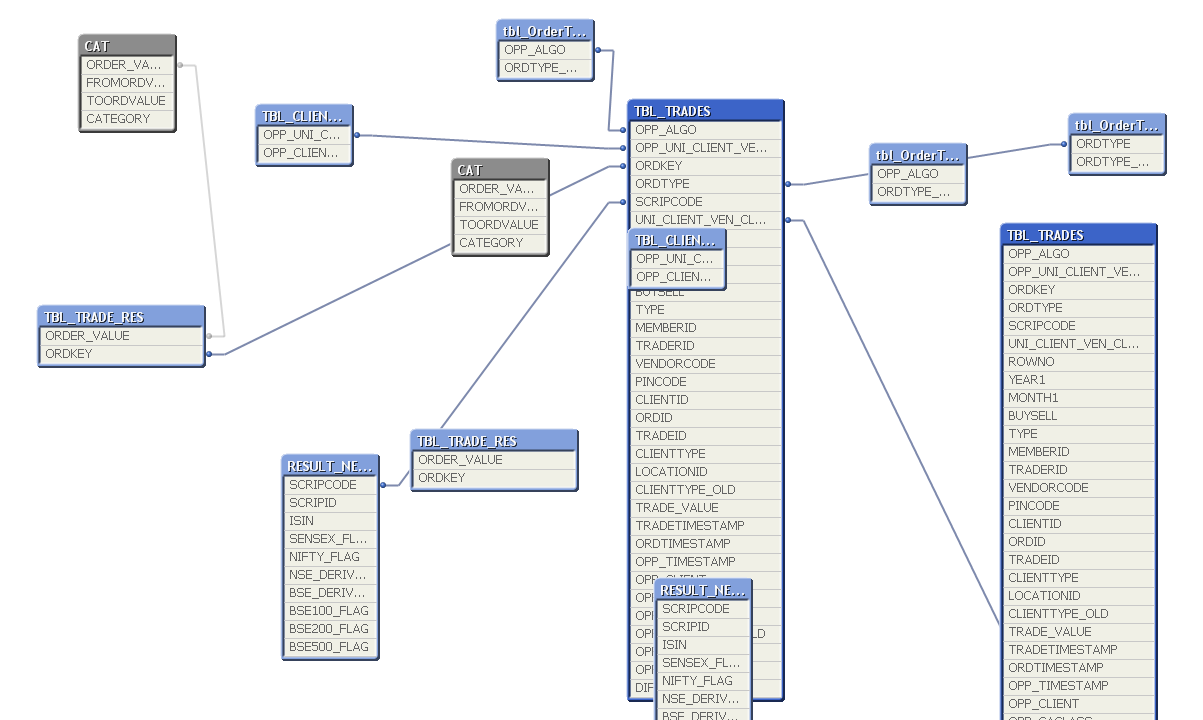
Below is the snapshot of the DATA Model TBL_Trades have the ORDKEY field
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Paul,
The ORDKEY is repeating in the TBL_TRADE table only. so i required to do Unique Count. If you have any idea kindly help
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There is also a ORDKEY in TBL_TRADE_RES, if this table cant be concatenated.
Add a extra field in the TBL_TRADE containing the ORDKEY for instance ORDKEY_COUNT
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Paul,
I get your point what u want to say. i will do the needful. Thanks for your Help.
Regards,
JKV