Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Data Modelling Help
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Data Modelling Help
Hey guys!!
Hope you all are having a happy weekend and those who are spending time helping this Brilliant communtity i need your suggestions here.
Lets say we have two tables 1 fact and 1 dimension(for simplicity)
fact:
A B C
1 .. ..
2 ... ...
3 ... ...
4 ... ...
DIMENSION:
A D E
1 .. ...
2 .. ...
The data in other column other than A doesnt really concern here so i have not updated here.so I have not update them. As you can see fact has more distinct value in Key column A than the dimension table .
What i want to ask is
1: if we get into this kind of scenerio than what would be the beter way to approach?
2: If subset ratio of dimesnion is not 100% (in this case here) will it create issue in our calculations?
3: Will this impact the result when we have large volume of data?
your suggestion and welcome and appreciated. Thanks in advance.
regards
Pradosh
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Best approach … will be difficult because it always depends on your data and the requirements to display them.
One approach could be like Gysbert hinted to clear out unneeded and/or invalid data. Another could be like showed from Sunny to display intentionally the data with all missing, invalid and erroneous data to display the failures within the processes which creates these data.
And a further way might be to check on possible data-failures and correct respectively repair them in some way and I think it's not unusual to combine these methods.
I use quite often a check on ID's like isnum(AnyID) to filter out invalid records (you could never find each potential issue and even with tremendous efforts you couldn't repair all of them) and another method is to fill missing values within the dimension-table maybe with something like this:
Dimension:
Load A, A as A2, D, E from DimSource;
Concatenate(Dimension)
Load A, 'Missing' as D, '#NV' as E from FactSource where not exists(A, A2);
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You're fact table contains A values that don't exist in your dimension table. That means if you use field D or E as dimensions in a chart you will get results that don't cover all the records in your fact table. Suppose you have to charts, one with A as dimension and one with D as dimension. Both chart use sum(B) as expression. The chart with A as dimension will have a different total than the chart with D as dimension. That may or may not be a problem. Perhaps your business is not interested in values of A that don't exist in the dimension table. In that case you could reduce the fact table to clear out records that don't have a matching A value in the dimension table.
talk is cheap, supply exceeds demand
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for your answer Gysbert. As you have mentioned already that the total could be different in different objects based on the dimension. I am still confused how to proceed .I was asked what is the best approach to go ahead in this case. If you can put some light into that and the reason for it .
I have thought of applying an inner keep . Is this the way to go ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I tried to recreate your scenario with a very a simple example. I guess it all comes down to what the users want to see ultimately. Take a look at the image below
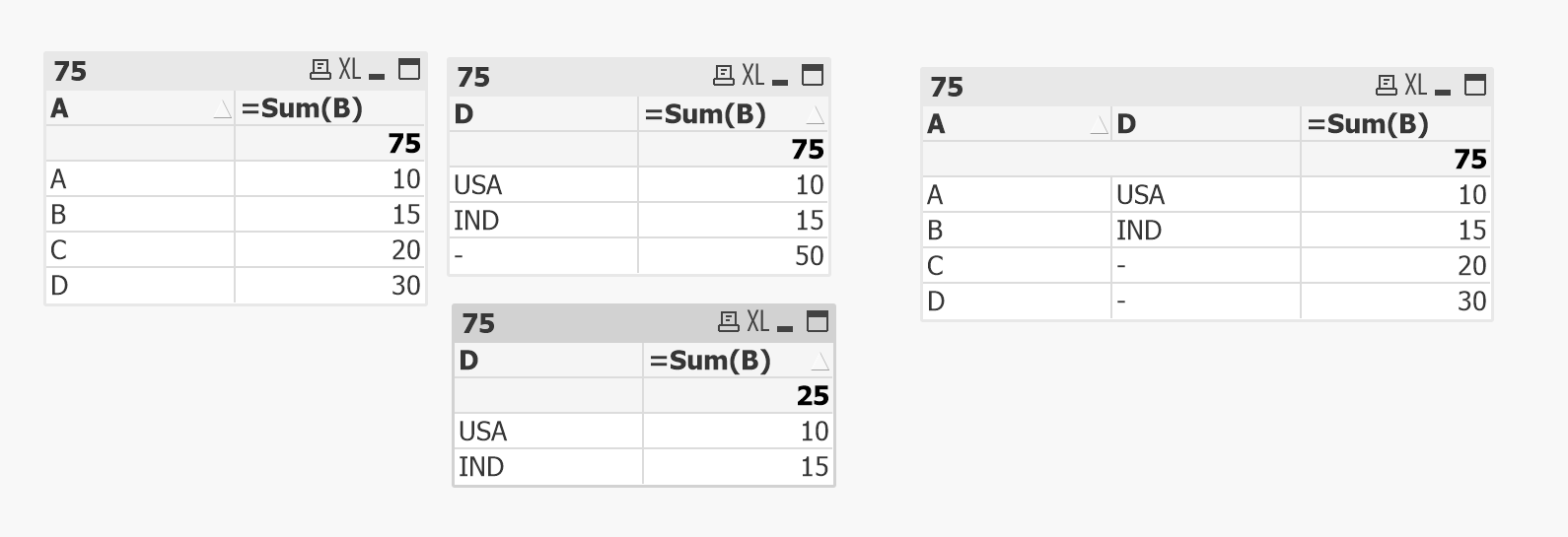
So, in the Above Image, Dimension D is only available for A and B under Dimension A. So, depending on the fact that if you are suppressing nulls for your dimension or not, you totals may or may not match. If you don't suppress null, then your chart is not necessarily wrong because what it is saying is that you have some value for USA, some for IND, rest of the value is for unavailable dimension value. If you wish to suppress null and still see total as 75, even that is doable using Dimensionality() function.
Anyways, my point is that your data is what it is... there is not much you can do for it. What you can do is to put it in a way that your user can understand (knowing the limitations).
Best,
Sunny
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Best approach … will be difficult because it always depends on your data and the requirements to display them.
One approach could be like Gysbert hinted to clear out unneeded and/or invalid data. Another could be like showed from Sunny to display intentionally the data with all missing, invalid and erroneous data to display the failures within the processes which creates these data.
And a further way might be to check on possible data-failures and correct respectively repair them in some way and I think it's not unusual to combine these methods.
I use quite often a check on ID's like isnum(AnyID) to filter out invalid records (you could never find each potential issue and even with tremendous efforts you couldn't repair all of them) and another method is to fill missing values within the dimension-table maybe with something like this:
Dimension:
Load A, A as A2, D, E from DimSource;
Concatenate(Dimension)
Load A, 'Missing' as D, '#NV' as E from FactSource where not exists(A, A2);
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In regular dimensional modeling which is good practice for Qlik Data Modeling the best practice is to replace possible null values so it is very clear that the dimensions are missing - just leaving them as NULL creates more confusion than not.
To do this in a script I made an example based on your data:
fact:
LOAD * INLINE [
A B C
1 .. ..
2 ... ...
3 ... ...
4 ... ...
] (delimiter is spaces);
DIMENSION:
LOAD *,A AS A_CHECK INLINE [
A D E
1 .. ...
2 .. ...
] (delimiter is spaces);
[Missing DIMENSION values]:
LOAD
A, '(A missing dimension key)' AS A_Txt
RESIDENT
fact
WHERE
Not(Exists(A_CHECK,A))
;
DROP FIELD A_CHECK;
Then it is easy to have a sheet with a table listing all the missing dimension keys that could be used to clean up the issue in the sources possibly.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you sunny. Using dimensionality()was a good idea.
regards
Pradosh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you everyone. Combining all of the ideas did give me the best approach..
regards
Pradosh