Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Data reload takes more time and hanging at las...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Data reload takes more time and hanging at last
Hi,
I have a huge report (with 26 QVDs of 700mb size in total) whose data were changed in 2 of the QVDs and reloaded. Before changing the data it took 1 hour 45 mins to reload completely , but after changing the data it took 7 hours and hung my laptop completely yesterday. Then I tried to reload again last night , after 14 hours of loading it hung my laptop again. I am not sure whether there is some problem with the new data or the data model. Please help in identifying the issue.
PFA script attached.
Regards,
James
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi James, if the script hangs before reaching the end of script the synthetic keys doesn't seems to be causing the issue. (but -almost always- is better to look a way to avoid them).
When I found this kind of issues I try to isolate the load of the table I'm suspicious is causing the trouble (TABLE_Eina_EineFL in your case) in a new document and check if some of the joins is unexpectedly duplicating records.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi James,
You have syntetic tables, and one seems that is the issue.
See this line:
10.06.2016 12:35:08: $Syn 1 = CustomFLMaterial+CustomFLSalesOrganization+CustomFLBusinessLine+CustomFLMaterialCategory+CustomFLDchainSpecStatus+CustomFLMUGDescription+CustomFLMonthNo+CustomFLYearNo+CustomFLEineFLPlant+CustomFLEinePlant+CustomFLEinaVendor+CustomFLPlant 10.06.2016 12:37:33: $Syn 2 = Material+sap_delivering_plant
Review this, it seems that you have added one more field in auto concatenated tables.
Regards!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
My suggestion is one reason is whatever Manuel said.
Can you please share me the Data model as well. so that, we can look what kind fact table and Synthetic keys are formed.
Please share me the clip of Data Model.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
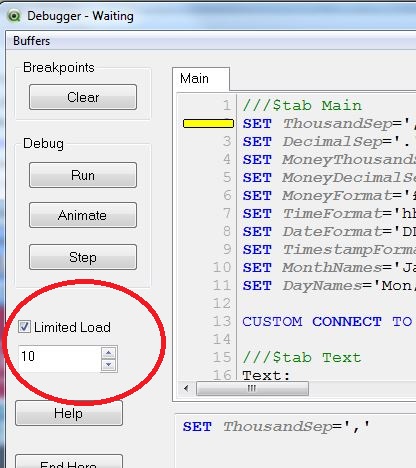
Can you run the script in Debug mMode and set a Limited Load of 10, 5 or even 1 row per table.
The number of rows being loaded is not important, it is the association between the tables.
This load will allow you to see what synthetic keys you have in your model and resolve them, as generating the synthetic keys is what is taking the time & resources in your data load.
See the earlier post by linking to data modelling best practices.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From the comments of Manuel below seems it has something related to syn keys. As a best practice is good to add the 'concatenate (TableName)' to ensure the control of what we want and avoid let this decission to the script autonomous logic.
Just to comment: this log has many 'table not found' errors -probably caused beacuse the limited load doesn't load records with the required conditions-... I can't be sure if the full execution is like this one but it seems this will also happening in full execution. Are you sure the reload hangs in the TABLE_Eina_EineFL before reaching the autoconcatenated tables?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
TRACE & Logging
Firstly add some trace commands so you can follow the progress of your script.
And enable the document log so you can see which parts of your script are taking time to execute.
Use Tabs
I would also suggest separating your load script into multiple tabs so there is one logical task or even one table per tab, to make testing simpler. Add a trace commands to identify the start of each tab as a minimum.
Form the Tab menu, you can use Insert Tab at Cursor to split your load into different tabs.
The load scripts executes the tabs in sequence from left to right, Tab 1 top to bottom, then tab 2....
Name your tables
I would also name each table you are loading rather than relying on the default name based on the FROM table as I find it more reliable to control the table names myself. Obviously this only applies to the topmost preceeding load.
TABLENAME:
load
...
Use EXIT SCRIPT for debugging.
Add a new tab "## Exit Script ##" which contains the following commands
TRACE ;
TRACE === EXIT SCRIPT === ;
exit script ;
This tab will exit the script cleanly and can be promoted and demoted between the tabs so you can control the data load rather than loading everything and seeing what works (or not!).
Demote the EXIT SCRIPT tab so you just load your mapping tables & first table load tab.
Run the script to load the first table, if it works, promote the EXIT SCRIPT tab, and load the next table.
If the load fails or you have synthetic keys, fix the issues before loading the next table and debugging will be much simpler.
I find moving an EXIT SCRIPT tab through the script tab by tab invaluable when testing.
Fix the errors early on and they do not propagate through the model.
Use FIRST N to limit data.
If a global Limited Load from debug does not load valid data for testing you can use a FIRST command to limit the rows from a large table for testing. This has to prefix each load you want to limit. The number is an integer with no thousand separator e.g. FIRST 10000
REMEMBER TO REMOVE ANY FIRST N COMMANDS WHEN TESTING IS FINISHED - USE SEARCH & REPLACE!
Avoid using Joins
I see you have some joins of tables that only have a few columns - I would not use a join but would use a mapping load even if it needs 5 or 6 mapping tables to get the result as this is faster than using joins.
For example this join could be done using 2 mapping tables Material_2_MUG_Desc & Material_2_Mat_Desc
LEFT JOIN(TEMP_CustomFLWithOutTPData)
LOAD Material,
[MUG Description] AS CFLMUGDescription,
[Material Description] AS CFLMaterialDescription
RESIDENt TABLE_PDM;
For more details see this post Don't join - use Applymap instead
Try using QVDs instead of RESIDENT load
It may be worth testing using QVDs instead of resident tables.
I have found in some cases it is faster to store a table to QVD, drop the original table and reload the QVD compared to using RESIDENT.
Finally read the Best Practices for Data Modelling that has been posted earlier in this thread.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
To all ,
I have a big doubt regarding the QVW size before and after editing script for loading some more qvds. Actual size of my qvw was 191 mb and after adding load statements for some more qvds made the qvw file size to 306 mb. But the load was not completed successfully at all. How does this size change occurred ?
-James
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Colin Albert / Ruben Marin ,
Any idea about this size change ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If the load wasn't completed I don't have a clue about size change. The last modified date coincides with that failed load? some scheduled task overwriting the file?
Is the ErrorMode set to 0? this will ignore errors on reload.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If the reload fails, then the QVW will not be overwritten and the file should remain as-is before the reload started.
I do not know why you are seeing a change in file size.
When the reload was not successfull, did the task indicate as failed with a red X in the status window or was the task showing as successful in the task history?
- « Previous Replies
-
- 1
- 2
- Next Replies »