Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Filtering data using one checkbox
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Filtering data using one checkbox
I have a big project with a lot of table. I have done an example to simply what I really want to obtain. Below is attached.
Suppose I have two tables, "Job_Data" and "Personal_Data" which are related through a filed called "ID"
Both tables have their own data. Both tables have a bit column (0 or 1 possible values). For "Job_Data" table is "Consultant" which indicates if the person is a consultant, and for "Personal_Data" table is "license_car" to indicate if that person can drive a car.
So, according this model, I am trying to filter the data from both tables using one checkbox.
This checkbox will filter data by taken into account below posible cases:
| Consultant | license_car |
|---|---|
| 0 | 0 |
| 0 | 1 |
| 1 | 0 |
| 1 | 1 |
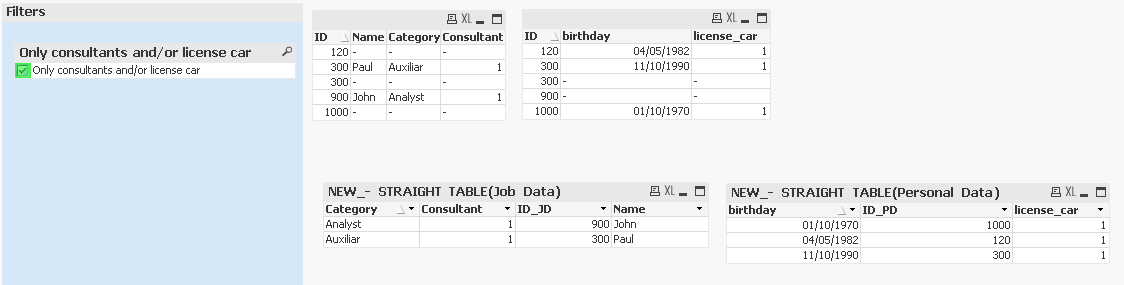
So I have created one checkbox "Only consultants and/or license car".
So according to the sample attached:
- If I check this checkbox:
- For table "Job_Data" I want to show the registers with "ID" 300 and 900 because "Consultant" field is marked as 1
- For table "Personal_Data" I want to only show registers with "ID" 120, 300 and 1000 because their "license_car" field is marked as 1. However I do not want to show "ID" 200 and 900 because in this case their "license_car" field is 0.
- If I uncheck this checkbox:
- I want to show all data for both tables independently of the values for "Consultant" and "license_car" fields.
So how can I do this? Preferably, I would like to use an expression through the checkbox if possible and not script.
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Then let the COMMON Table behave like the link table
[Job_Data]:
LOAD *,ID as ID_JD INLINE [
ID, Name, Category, Consultant
1000, 'David', 'Auxiliar', 0
900, 'John', 'Analyst', 1
200, 'Anne', 'Manager', 0
120, 'Peter', 'Director', 0
300, 'Paul', 'Auxiliar', 1
]
;
[Personal_Data]:
LOAD *,ID as ID_PD INLINE [
ID, birthday, license_car
1000,01/10/1970, 1
900, 12/01/1980, 0
200, 23/05/1960, 0
120, 04/05/1982, 1
300, 11/10/1990, 1
]
;
COMMON:
LOAD * INLINE [
ID,hobby
1000,xyx
900,abc
200,efg
120,pla
300,gdf
];
left join (COMMON)
LINK_TABLE:
Load ID,ID_JD,Consultant as Consultant_License RESIDENT [Job_Data];
Concatenate
Load ID,ID_PD,license_car as Consultant_License RESIDENT [Personal_Data];
Drop Field ID FROM [Job_Data];
Drop Field ID FROM [Personal_Data];
If a post helps to resolve your issue, please accept it as a Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Tony,
Please find the below attachment and let me know.
Thanks
Kumar KVP
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In fact, what I want is internally filter my data model according to the checkbox, value (checked/unchecked). The expression of the checkbox may be another (I don't know).
So:
- If I check this checkbox basically I want Qlik to automatically filter my data model in order to take into account only the data with "ID" 300 and 900 because "Consultant" field is marked as 1 (which come from table "Job_Data"), and those which come from table "Personal_Data", that is, those which have "ID" 120, 300 and 1000 I also want to include them in my data model because their "license_car" field is marked as 1. However I do not want to include in my data model those which have "ID" 200 and 900 (from table "Personal_Data") because in this case their "license_car" field is 0.
In other words, in this case, I want Qlik to include in my data model the data for IDs 300,900 (table "Job_Data") and also include data corresponding to IDs 120,300 and 1000 that come from table "Personal_Data". However, data for IDs 200 and 900 that come from table "Personal_Data" I want Qlick to automatically exclude from my data model.
- If I uncheck this checkbox:
- I want data model to take into account all the data that come from both tables independently of the values for "Consultant" and "license_car" fields.
Is it possible?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Check the Attached, you need a link table to manage this
Listbox
=if(Consultant_License=1,'Only consultants and/or license car')
/////// SCRIPT/////////////////////////
[Job_Data]:
LOAD *,ID as ID_JD INLINE [
ID, Name, Category, Consultant
1000, 'David', 'Auxiliar', 0
900, 'John', 'Analyst', 1
200, 'Anne', 'Manager', 0
120, 'Peter', 'Director', 0
300, 'Paul', 'Auxiliar', 1
]
;
[Personal_Data]:
LOAD *,ID as ID_PD INLINE [
ID, birthday, license_car
1000,01/10/1970, 1
900, 12/01/1980, 0
200, 23/05/1960, 0
120, 04/05/1982, 1
300, 11/10/1990, 1
]
;
LINK_TABLE:
Load ID,ID_JD,Consultant as Consultant_License RESIDENT [Job_Data];
Concatenate
Load ID,ID_PD,license_car as Consultant_License RESIDENT [Personal_Data];
Drop Field ID FROM [Job_Data];
Drop Field ID FROM [Personal_Data];
/////// End of SCRIPT/////////////////////////
If a post helps to resolve your issue, please accept it as a Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi rrodriguez75
Have you checked the attached?
I'd like to add that never use table box to verify the data as a table box is only a collection of listboxes and not exact representation of your data.
If a post helps to resolve your issue, please accept it as a Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Your solution works well. But this sample is a piece of my big data model. In my entire data model both tables, Job_Data and Personal_Data are related as well through a common table, let's say "Common". So in this case your solution generates a circular reference.
Personal_Data <-------> LINK_TABLE <----------> Job_Data
| |
| |
--------------------> COMMON <----------------------
Imagine "Common" table has columns:
- ID
- Hobby
But I do not want to replicate table "Common" to avoid the circular reference. Any method to avoid circular reference without replicating data?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Then let the COMMON Table behave like the link table
[Job_Data]:
LOAD *,ID as ID_JD INLINE [
ID, Name, Category, Consultant
1000, 'David', 'Auxiliar', 0
900, 'John', 'Analyst', 1
200, 'Anne', 'Manager', 0
120, 'Peter', 'Director', 0
300, 'Paul', 'Auxiliar', 1
]
;
[Personal_Data]:
LOAD *,ID as ID_PD INLINE [
ID, birthday, license_car
1000,01/10/1970, 1
900, 12/01/1980, 0
200, 23/05/1960, 0
120, 04/05/1982, 1
300, 11/10/1990, 1
]
;
COMMON:
LOAD * INLINE [
ID,hobby
1000,xyx
900,abc
200,efg
120,pla
300,gdf
];
left join (COMMON)
LINK_TABLE:
Load ID,ID_JD,Consultant as Consultant_License RESIDENT [Job_Data];
Concatenate
Load ID,ID_PD,license_car as Consultant_License RESIDENT [Personal_Data];
Drop Field ID FROM [Job_Data];
Drop Field ID FROM [Personal_Data];
If a post helps to resolve your issue, please accept it as a Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Great! One last thing, the resulting table is called 'COMMON' but how can I change the table name (for example to RESULT_TABLE)? Using below is not working:
[RESULT_TABLE]:
left join (COMMON)
LINK_TABLE:
Load ID,ID_JD,Consultant as Consultant_License RESIDENT [Job_Data];
Concatenate
Load ID,ID_PD,license_car as Consultant_License RESIDENT [Personal_Data];
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Change the Name of the Table you are joining to
using above sample;
[Job_Data]:
LOAD *,ID as ID_JD INLINE [
ID, Name, Category, Consultant
1000, 'David', 'Auxiliar', 0
900, 'John', 'Analyst', 1
200, 'Anne', 'Manager', 0
120, 'Peter', 'Director', 0
300, 'Paul', 'Auxiliar', 1
]
;
[Personal_Data]:
LOAD *,ID as ID_PD INLINE [
ID, birthday, license_car
1000,01/10/1970, 1
900, 12/01/1980, 0
200, 23/05/1960, 0
120, 04/05/1982, 1
300, 11/10/1990, 1
]
;
RESULT_TABLE:
LOAD * INLINE [
ID,hobby
1000,xyx
900,abc
200,efg
120,pla
300,gdf
];
left join (RESULT_TABLE)
LINK_TABLE:
Load ID,ID_JD,Consultant as Consultant_License RESIDENT [Job_Data];
Concatenate
Load ID,ID_PD,license_car as Consultant_License RESIDENT [Personal_Data];
Drop Field ID FROM [Job_Data];
Drop Field ID FROM [Personal_Data];
If a post helps to resolve your issue, please accept it as a Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
But without modifying the inline table name.
- « Previous Replies
-
- 1
- 2
- Next Replies »