Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Getting rid of synthetic keys
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Getting rid of synthetic keys
CASES:
LOAD
CASEID,
CATEGORYID;
SQL SELECT
CASEID,
CATEGORYID
FROM ICMSCITRIX.dbo.TBLCASE;
CHARGEOFFS:
LOAD
CASEID,
// AutoNumber (CASEID & '-' & CATEGORYID) As CaseCateKey,
CHARGEOFFAMOUNT,
CHARGEOFFDATE,
CHARGEOFFGL,
CHARGEOFFSETRU,
INCIDENTCOUNTERID,
CATEGORYID,
Date (monthstart (CHARGEOFFDATE) , 'MMM_YYYY') as ReportMonthYear,
'ICMS' AS SYSTEM;
SQL SELECT
CASEID,
CHARGEOFFAMOUNT,
CHARGEOFFDATE,
CHARGEOFFGL,
CHARGEOFFSETRU,
INCIDENTCOUNTERID,
CATEGORYID
FROM ICMSCITRIX.dbo.TBLINCIDENT
WHERE CHARGEOFFDATE >= '1/1/2012'
AND CHARGEOFFDATE <= '12/31/2012'
AND CHARGEOFFGL IN (860360, 980360, 990360, 970360, 860500);
RECOVERIES:
LOAD
CASEID,
DATEOFRECOVERY,
ITEMIZEDRECOVERYGL,
ITEMIZEDRECOVERYLOSSLOCATION AS LOCATIONID,
TOTALRECOVERY,
Date (monthstart (DATEOFRECOVERY) , 'MMM_YYYY') as ReportMonthYear;
SQL SELECT CASEID,
DATEOFRECOVERY,
ITEMIZEDRECOVERYGL,
ITEMIZEDRECOVERYLOSSLOCATION,
TOTALRECOVERY
FROM ICMSCITRIX.dbo.TBLITEMIZEDRECOVERY
WHERE DATEOFRECOVERY >= '1/1/2012'
AND DATEOFRECOVERY <= '12/31/2012'
AND ITEMIZEDRECOVERYGL IN (860360, 980360, 990360, 970360, 860500);
Directory;
LOAD REPORTGROUPING,
CATEGORYID,
Type
FROM
[..\ICMS_Categories.xlsx]
(ooxml, embedded labels, table is ReportGroupings);
Directory;
LOAD L6,
L5,
LOCATIONID
FROM
[..\ICMS_Location.xlsx]
(ooxml, embedded labels, table is LOCATION);
PAYMENTS:
LOAD
CASEID,
PAYMENTAMOUNT,
PAYMENTDATE,
Date (monthstart (PAYMENTDATE) , 'MMM_YYYY') as ReportMonthYear;
SQL SELECT
CASEID,
PAYMENTAMOUNT,
PAYMENTDATE
FROM ICMSCITRIX.dbo.TBLRECOVERYPAYMENT
WHERE PAYMENTDATE >= '1/1/2012'
AND PAYMENTDATE <= '12/31/2012';
RECOVERYCASE:
LOAD
CASEID,
COSTCENTER,
LOSSLOCATIONID AS LOCATIONID;
SQL SELECT
CASEID,
COSTCENTER,
LOSSLOCATIONID
FROM ICMSCITRIX.dbo.TBLRECOVERYCASE
WHERE COSTCENTER IN ('860360', '980360', '990360', '970360', '860500');
My script is shown above. I need to get rid of the synthetic keys shown in the image below. Any suggestion will be appeciated. Thanks!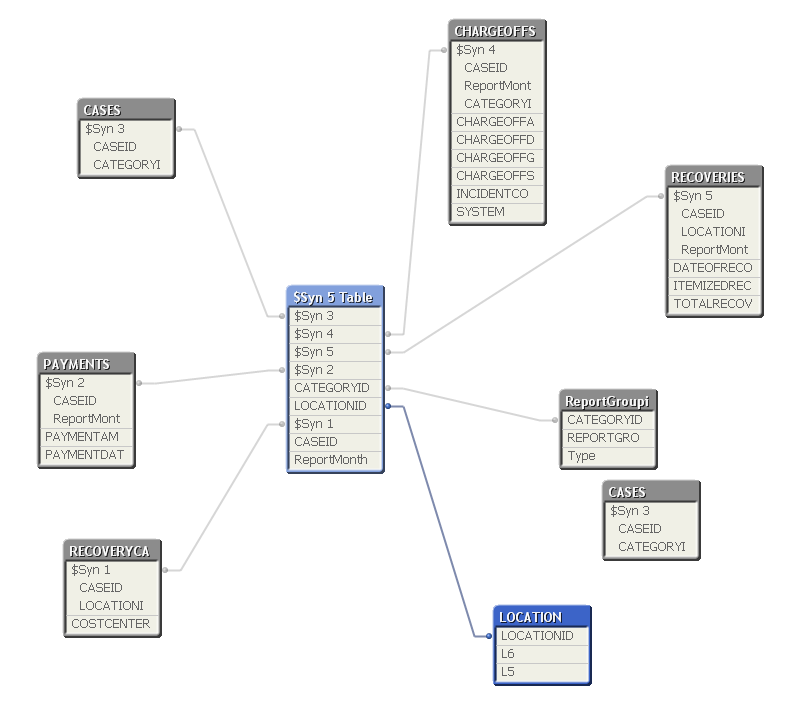
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would first try to check which fields are real key fields and which not. Try to remove data redundancy.
For example, you have several tables with CaseID and CategoryID (same for CaseID and LocationID).
If the CategoryID is the same per CaseID, it would be sufficient to store the information once, not in several tables (I guess I would keep the CategoryID in Cases table and remove the field from ChargeOffs table. In general, store the CategoryID in the table that keeps all distinct values for CasesID)
Similar for LocationID.
If you need a combined key, create a combined one (using e.g. autonumber() ).
Think about joining / concatenating tables where appropriate.
Hope this helps,
Stefan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You have to create a Link_Table, regards!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is Link_table create from qlik. In a project qlik you don't have a synthetic keys, beacuse the synthetic keys consume a lot of memory and the performance of file is very very worse when you have a big data.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would first try to check which fields are real key fields and which not. Try to remove data redundancy.
For example, you have several tables with CaseID and CategoryID (same for CaseID and LocationID).
If the CategoryID is the same per CaseID, it would be sufficient to store the information once, not in several tables (I guess I would keep the CategoryID in Cases table and remove the field from ChargeOffs table. In general, store the CategoryID in the table that keeps all distinct values for CasesID)
Similar for LocationID.
If you need a combined key, create a combined one (using e.g. autonumber() ).
Think about joining / concatenating tables where appropriate.
Hope this helps,
Stefan