Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Import File containing field (US) and Row (RS)...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Import File containing field (US) and Row (RS) separator
Hi,
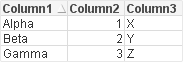
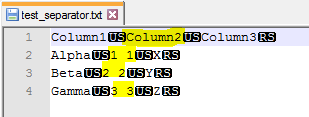
my txt file contains both field (US) and row (RS) separators:
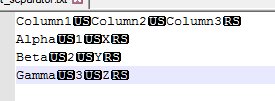
I can only define one separator within the wizard for importing tables:
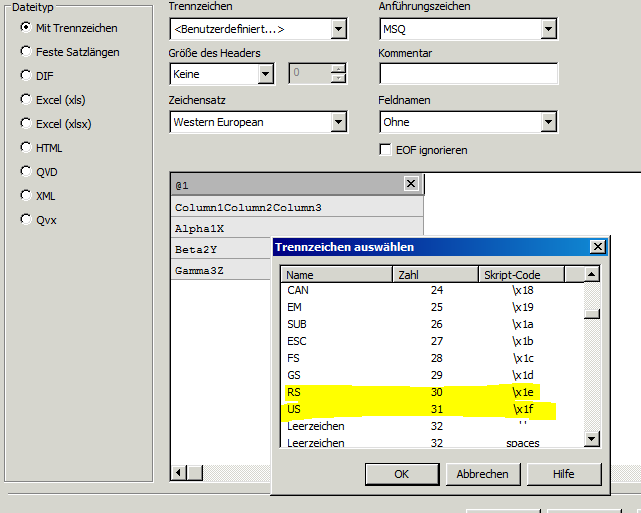
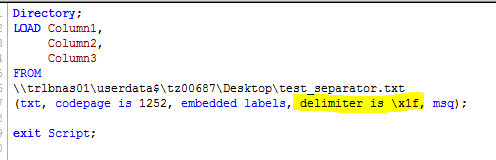
If I choose US (\x1f), the load script generates an error (field not found) for the last column (Column 3), because it cannot resolve the "RS" separator.
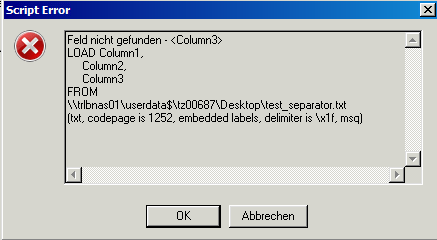
How can I import this file to QV? Is it possible to define both field and row separators within the table import wizard?
Many thanks,
Paul
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Like previous mentioned you might need a load-chain. Maybe by loading the file at first without any delimiter with fixed lenghts and on this happens some transformations, maybe something like: replace(@1, ' ', ' ') or something similar. After that you stored the table as txt-file again and load it normally with a delimiter.
Such transformations could be quite difficult if simply measure like this replace didn't work - therefore the easiest way might be to change the source (maybe a different output format like xml could be useful).
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Would you be able to share the sample text file so that we can test this at our end?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sure, here you go. Please note that I can only see this special kind of separators using Notepad++. Also, I have done some more tests in the meantime and it seems that the error is occurring due to the column names, not the data itself.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You couldn't apply two delimiters at the same time. This meant you might need a load-process with several chained loadings. What happens if you simply load: Load * From ... with and without embedded labels?
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
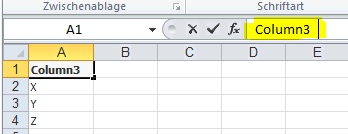
Marcus, thanks for your help. Load * from is working even with embedded levels. As you can see in the screenshot, QlikView is creating automatically a large space after the column name "Column 3" in order to resolve the RS tag. I tried to copy the label including the space to the QV load script, but it's not working.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Paul,
try this
LOAD Column1,
Column2,
Column3
FROM
File
(txt, codepage is 1252, embedded labels, delimiter is spaces, msq);
Regards,
Antonio
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Nice - that's working. Many thanks 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
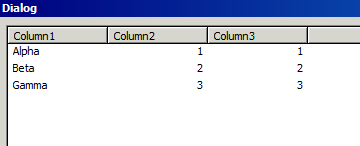
However, this solution only works if there are no spaces in the data. If there are spaces, the result is wrong.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Like previous mentioned you might need a load-chain. Maybe by loading the file at first without any delimiter with fixed lenghts and on this happens some transformations, maybe something like: replace(@1, ' ', ' ') or something similar. After that you stored the table as txt-file again and load it normally with a delimiter.
Such transformations could be quite difficult if simply measure like this replace didn't work - therefore the easiest way might be to change the source (maybe a different output format like xml could be useful).
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks!