Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Performance issues related to "Link table / star s...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Performance issues related to "Link table / star schema" model
Please see below script that I used to implement Link table model --
[TEMP_MAC_EVENT_MEETING]:
LOAD
*,
Month(MEETING_DATE) as MEETING_MONTH,
if(InYearToDate(EVENT_START_DATE,$(LAST_WORKDAY_VAR),0,1)=-1,1,0) AS EventYTDFlag,
if(InYearToDate(EVENT_START_DATE,$(LAST_WORKDAY_VAR),-1)=-1,1,0) AS EventPrevYTDFlag,
if(InYearToDate(MEETING_DATE,$(LAST_WORKDAY_VAR),0,1)=-1,1,0) AS MeetingYTDFlag,
if(InYearToDate(MEETING_DATE,$(LAST_WORKDAY_VAR),-1)=-1,1,0) AS MeetingPrevYTDFlag,
....
....
FROM
$(QVD_FOLDER)MAC_EventMeeting.qvd (qvd);
[MAC_EVENT_MEETING]:
Load
*,
RowNo() as %Key2
resident
[TEMP_MAC_EVENT_MEETING]
where
not isnull(CMU2_ID);
drop table [TEMP_MAC_EVENT_MEETING];
[BlockLoss]:
LOAD
*,
left(MTH_YR,4) as BLOCK_LOSS_YEAR,
RIGHT(MTH_YR,2) as BLOCK_LOSS_MONTH,
...
...
RowNo() as %Key3
FROM
$(QVD_FOLDER)BlockLoss.qvd (qvd);
[DEAL_ALLOCATION]:
LOAD
CMU2_ID,
INTRMDT_TRD_ID,
INTRMDT_SRC_SYSTM_NM,
...
...
RowNo() as %Key4
FROM
$(QVD_FOLDER)DealAllocation.qvd (qvd);
Link:
LOAD
%Key2,
CMU2_ID,
MEETING_DATE as CalendarDate
RESIDENT [MAC_EVENT_MEETING];
concatenate (Link)
LOAD
%Key3,
CMU2_ID,
BLOCK_LOSS_DATE as CalendarDate
RESIDENT [BlockLoss];
concatenate (Link)
LOAD
%Key4,
CMU2_ID,
RPRTNG_DT as CalendarDate
RESIDENT [DEAL_ALLOCATION];
drop field CMU2_ID from [MAC_EVENT_MEETING];
drop field CMU2_ID from [BlockLoss];
drop field CMU2_ID from [DEAL_ALLOCATION];
Also attached is the data model..
Lot of the charts are made up of big expressions... Below is one example... these are first 6 lines of the expression which is about 60 lines long.
if(count({$<ConfFlag={1}>}total distinct EVENT_ID)>0,
(count({<ConfFlag={1}>}distinct EVENT_ID) /
count({$<ConfFlag={1}>}total distinct EVENT_ID) * ACI_1_1_1_WEIGHT), 0)
+ if(count({$<ConfFlag={1}>}total distinct CLIENT_CONTACT_NAME)>0,
(count({<ConfFlag={1}>}distinct CLIENT_CONTACT_NAME) /
count({$<ConfFlag={1}>}total distinct CLIENT_CONTACT_NAME) * ACI_1_1_2_WEIGHT), 0)
...
...
...
...
Before implementing Link Table model, application used to perform fairly quickly, but now I notice that peformance has slowed down quite a bit... Can someone please suggest any ideas to improve the performance? Am I correctly generating %key columns? I read about autonumber() but not sure if that will help here..
Thanks in advance for any suggestions!
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would always try and avoid link tables as I can't believe the multitude of links they create won't slow down the whole application. Instead, try concatenating all the different transaction-type tables together and add a FACT_type to each section. This way you end up with just one central fact table that can join to the dimensions, including date.
Jason
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jason, thanks for your reply..
Link table approach resolves quite a few issues that I experience otherwise... converting this model to concatenate would involve lot of testing.. so I will keep that as last option..
Any suggestions to improve it by keeping link table approach...?
I started using autonumberhash128() instead of RowNoI() to create a key on every row.
example -
[MAC_EVENT_MEETING]:
Load
*,
autonumberhash128(CMU2_ID, EVENT_ID,MEETING_ID) as %Key2
resident
[TEMP_MAC_EVENT_MEETING]
where
not isnull(CMU2_ID);
But this didnt make any difference in performance.. since I reloading data from resident tables, its not loaded in "qvd optimized" fashion.. does that affect runtime performance? I am hoping that it just affects load time..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Well if you have to keep the link table approach then consider moving as much as possible into the script in the first place. I don't think I've ever seen a 60-line expression before! Surely you can move some of that into the script?
Also, DISTINCT COUNTs are the most inefficient way of calculating. COUNT is better, but SUM is best. In the script, put a counter field into each table (1 AS Counter_Event, for example) and then SUM(Counter_Event) rather than COUNT(DISTINCT Event_ID).
Non-optimized loads only slow down load-times and have no direct bearing on UI performance.
Jason
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
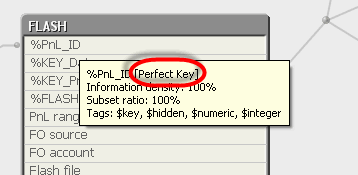
are you using perfect keys?
-----------------------
QlikView pre-calculates all of the links among tables so that it is fast when tables are joined to calculate an expression. However, this is truer if every link key is a perfect key in one of the tables it connects. For instance, in the data model below, ShipperKey links Shipper and SalesFacts tables and the closer ShipperKey is to a perfect key in table Shipper, the faster the join can be calculated. When ShipperKey is a perfect key in Shipper, each record in Shipper is linked to multiple records in SalesFacts, making the link to be one-to-many, which is ideal for QlikView.
If the key field linking two tables is not a perfect key, then each record in either table is linked to multiple records in the other table (many-to-many), this is very in-efficient in QlikView.