Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Picking just 1 value of a Unique ID
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Picking just 1 value of a Unique ID
Hello all, I am building my first app and I'm almost there but I need help. I have about a 100,000 rows and approx 3 thds have duplicate primary IDs. I need to filtered the ID column down to a unique ID per row. I do not care which other values are removed. It's just important to have a unique set of IDs...See below.
ID Cd Name
1261 TT John
1261 FF John
1261 RR John
2 TT Shawn
3 RR Billy
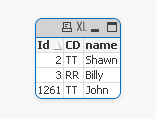
I would like to see...
ID Cd Name
1261 TT John
2 TT Shawn
3 RR Billy
This information is in a straight table. Best approach to handle this situation?
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
t1:
load * inline [
ID , Cd, Name
1261 , TT , John
1261 , FF , John
1261 ,RR , John
2 , TT , Shawn
3 , RR , Billy
3 , RR , Billy
3 , RR , Billy
3 , RR , Billy
]
;
store t1 into tmp.qvd (qvd);
DROP Table t1;
t1: load * from tmp.qvd (qvd) where not exists(ID);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi John,
This is easy to do with the use of distinct load.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As long as it's sorted as you would expect - go to Dimension Limits and select the ID dimension then Restrict to only show First 1 value.
Remember to deselect the "Others" option at the bottom
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The above values are distinct but I would like to select one of a repeating ID unless I'm just missing something...?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
t1:
load * inline
[ID , Cd, Name
1261 , TT , John
1261 , FF , John
1261 ,RR , John
2 , TT , Shawn
3 , RR , Billy
]
;
t1:
LOAD
FirstValue(ID) AS Id,
FirstValue(Cd) AS CD,
FirstValue(Name) AS name
resident t1
GROUP BY ID;
drop table t1;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
When you say you don't care which values are removed, do you just need a list of unique IDs or a unique ID attached to one valid record each?
If just unique IDs, just load the ID field and precede it with Distinct (so Load Distinct ID from...)
If the second, for any non ID field, you'll want to aggregate by using something like Max(), Min(), MaxString(), FirstValue() etc. - that would just pull one value for each field. Then after your From statement, include a 'Group By ID;' to ensure you only get one for each ID.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would generally try to add something that indicated where a field that had be cleansed like this has duplicates in it, in case someone asked where John's FF (or similar) had gone.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Correct, I need a unique ID attached to one valid record.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would assign a unique id to each row using RecNo(). Then you can select the first row for each ID like this:
t1:
load *, RecNo() as RecId inline [
ID , Cd, Name
1261 , TT , John
1261 , FF , John
1261 ,RR , John
2 , TT , Shawn
3 , RR , Billy
]
;
INNER JOIN(t1)
LOAD
min(RecId) as RecId
RESIDENT t1
GROUP BY ID
;
-Rob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have over a hundred thousand records/rows that are being extracted from SQL. Would you still use incline as your approach?
- « Previous Replies
-
- 1
- 2
- Next Replies »