Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Should We Stop Worrying and Love the Synthetic...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Should We Stop Worrying and Love the Synthetic Key?
Synthetic keys have a bad reputation. The consensus seems to be that they cause performance and memory problems, and should usually or even always be removed.
I believe that the consensus is wrong.
My understanding of a synthetic key is that it’s a pretty basic data structure. If you load tables like this:
TableA: FieldA, FieldB, FieldC
TableB: FieldA, FieldB, FieldD
What you’ll actually get is this:
TableA: SyntheticKey, FieldC
TableB: SyntheticKey, FieldD
SyntheticKeyTable: SyntheticKey, FieldA, FieldB
Where neither the synthetic key nor the synthetic key table can be directly referenced, only the original fields.
Well, that doesn’t sound like a bad thing. If I had two tables that I legitimately wanted to connect by two fields, that’s pretty much what I would do manually. As far as I can tell, QlikView is simply saving me the trouble.
Two tables can be connected by one field. That shows up as a connection. Two tables can be connected by two or more fields. That shows up as a synthetic key.
Now, maybe you should NOT connect two particular tables by one field. If so, that’s a data model problem that should be fixed. And while you could say that THAT connection is a problem, you should never say that CONNECTIONS are a problem.
Similarly, maybe you should NOT connect two particular tables by two or more fields. If so, that’s a data model problem that should be fixed. And while you could say that THAT synthetic key is a problem, perhaps you should never say that SYNTHETIC KEYS are a problem.
Synthetic keys should be no more a problem than automatic connections between tables are a problem. Either can cause problems when they result from a bad data model, when there are too many or the wrong connections. But neither should cause problems when they result from a good data model. You should not remove all synthetic keys any more than you should remove all connections between tables. If it is appropriate to connect two tables on two or more fields, I believe it is appropriate to use a synthetic key.
What does the reference manual have to say on the subject?
"When two or more input tables have two or more fields in common, this implies a composite key relationship. QlikView handles this through synthetic keys. These keys are anonymous fields that represent all occurring combinations of the composite key. When the number of composite keys increases, depending on data amounts, table structure and other factors, QlikView may or may not handle them gracefully. QlikView may end up using excessive amount of time and/or memory. Unfortunately the actual limitations are virtually impossible to predict, which leaves only trial and error as a practical method to determine them.
Therefore we recommend an overall analysis of the intended table structure by the application designer. Typical tricks include:
· Forming your own non-composite keys, typically using string concatenation inside an AutoNumber script function.
· Making sure only the necessary fields connect. If you for example use a date as a key, make sure you do not load e.g. year, month or day_of_month from more than one input table."
Yikes! Dire warnings like “may not handle them gracefully” and “may end up using excessive amount of time and/or memory” and “impossible to predict”. No WONDER everyone tries to remove them!
But I suspect that the reference manual is just poorly written. I don’t think these warnings are about having synthetic keys; I think they’re about having a LOT of synthetic keys. Like many of you, I’ve gotten that nasty virtual memory error at the end of a data load as QlikView builds large numbers of synthetic keys. But the only time I’ve ever seen this happen is when I’ve introduced a serious data model problem. I’ve never seen a good data model that resulted in a lot of synthetic keys. Doesn’t mean they don’t exist, of course, but I’ve never seen one.
I’d also like to focus on this particular part, “Typical tricks include: Forming your own non-composite keys”. While I agree that this is a typical trick, I also believe it is useless at best, and typically A BAD IDEA. And THAT is what I’m particularly interested in discussing.
My belief is that there is no or almost no GOOD data model where this trick will actually improve performance and memory usage. I’m suggesting that if you have a synthetic key, and you do a direct one to one replacement with your own composite key table, you will not improve performance or memory usage. In fact, I believe performance and memory usage will typically get marginally worse.
I only have one test of my own to provide, from this thread:
http://community.qlik.com/forums/t/23510.aspx
In the thread, a synthetic key was blamed for some performance and memory problems, and it was stated that when the synthetic key was removed, these problems were solved. I explained that the problem was actually a data modeling problem, where the new version had actually corrected the data model itself in addition to removing the synthetic key. I then demonstrated that if the synthetic key was reintroduced to the corrected data model, script performance was significantly improved, while application performance and memory usage were marginally improved.
load time file KB RAM KB CalcTime
synthetic key removed 14:01 49,507 77,248 46,000 ms
synthetic key left in place 3:27 49,401 77,160 44,797 ms
What I would love to see are COUNTEREXAMPLES to what I’m suggesting. I’m happy to learn something here. I’ve seen plenty of vague suggestions that the synthetic keys have hurt performance and wasted memory, but actual examples seem to be lacking. The few I ran across all looked like they were caused by data model problems rather than by the synthetic keys themselves. Maybe I just have a bad memory, and failed to find good examples when I searched. But I just don’t remember seeing them.
So who has a script that produces a good data model with a composite key table, where removing the composite key table and allowing QlikView to build a synthetic key instead decreases performance or increases memory usage? Who has an actual problem CAUSED by synthetic keys, rather than by an underlying data model problem?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi John,
We are in 2016 and this topic still hot (at least for me), allow me to give my personal experience in this matter so you might use it as an example. (FYI I do agree 100% with your post).
I do have quite some experiences modeling relational databases (+5 years, and in school with high marks) so that's why this topic falls in my range.
Currently I'm following a video course about QlikView and I got a bit disappointed with the section regarding synthetic keys.
That's the example (roughly) used to explain why we should remove the keys.
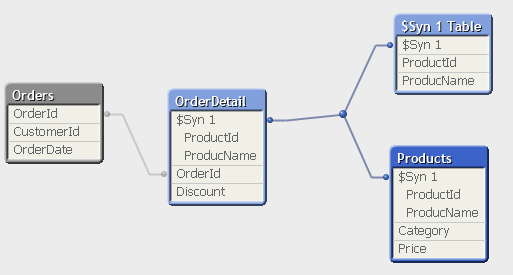
Obviously this problem is not the synthetic key, this problem is the bad modeling. What this model tells me is that you have 2 different tables that holds a combination of ProductId and ProductName in 2 different locations, that's a red flag that calls for trouble, what if you typo in Products table one of the names? Or you mistakenly give the Id to another product? Well you are open for troubles.
So yes, in this case, you need to avoid this synthetic key as it would enhance your mistake. How? Pretty simple Normalization. So then you get something like this:
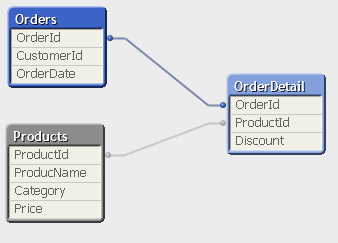
In this case Order Detail doesn't need any ProductName, so I explicitly state that Products is my only and valid source for giving a name to the ProductId, and I simply don't care about OrderDetail's ProductName, because is not valid.
Now, when you should not remove the synthetic keys, an that's an example I work daily.
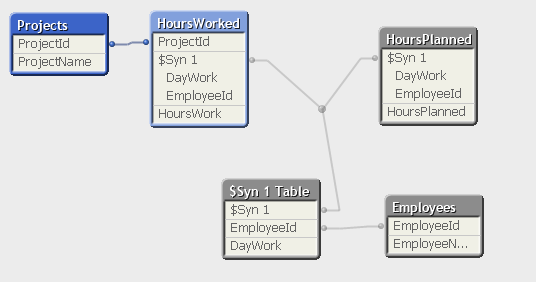
Now here the synthetic keys are very helpful, if I have to parse the whole HoursWorked and the HoursPlanned and create a unique key to link those 2 tables, is very difficult. So in this case I thank the synthetic keys!
If anyone has a better way to solve that, without synthetic keys (concatenate the 2 tables didn't work so I had to dismiss that option, very long story to place it here), I'm open to try it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi jmolinaso,
I didn't quite agree with John 6 years ago, and I'm not quite in agreement with you now. Let me explain to you why.
First, let me say that - yes, in this straw-man example with two keys and four tables, the Synthetic Key works as well as the manually produced Link Table, so why bother? Having said that, here are my arguments against the concept of embracing synthetic tables:
1. If your dataset has any chances to get larger (more than a few millions of rows), then this structure, just as well as the Link Table structure won't fly, from the performance standpoint:
- It is a known fact that QlikView works well with a single large table in the dataset, and it doesn't work with two or more large tables. In your example, if the tables of HoursWorked and Hours Planned are both large, then the Synthetic table is the third large table making the whole structure even worse.
- It is known that calculating expressions with metrics coming from multiple tables is notoriously slow, and the overhead grows with the number of links that separate the metrics in the data structure. In your example, any calculation that might involve both HoursWork and HoursPlanned, are going to be slow.
- It is known that the Cardinality of your fields make a huge impact on the memory footprint of your database. Synthetic Keys (as well as concatenated Link Keys) increase the initial Cardinality of the key fields by a huge factor. For example, in your case - if you have 10,000 employees and 2,000 days (approx. 6 years), the corresponding Synthetic Key will have up to 20 million distinct values. If you had a few more common keys to add into the mix, the result would be even worse. So, your Synthetic key now consumes about 70% of your memory footprint. Would I dare to say that it's a good thing? - perhaps not.
2. Even if performance is not such a big concern, let's think about complexity of your data model. Your example is extremely simple, and yet the Synthetic key makes it look more tangled. Reasonably complex data models can get a lot more tangled with one or more synthetic tables added to the mix.
3. If complexity of your data model leads to several Synthetic keys being built on top of one another, then it's a known fact that performance is likely to degrade substantially.
4. Finally, even if none of the above is a concern to you, then I'd argue that leaving Synthetic Keys in your data models is a manifestation of a sloppy programming style where you don't care to be explicit in your scripting. It's the same degree of sloppiness as not naming your tables explicitly and letting QlikView assign default names instead; or using meaningless and cryptic names for your fields and variables. It's about being sloppy vs. being explicit. IMHO, it's worth writing a few more lines of script to be more explicit rather than sloppy.
Last point - you mentioned that "concatenating the two tables didn't work"... I have to say that perhaps it introduced additional challenges that you didn't care to overcome, but I have never seen a QlikView data model that could not be transformed into a single-fact star with enough efforts. For large data sets, it's an absolute necessity. Whether it's worth your effort or not - that a completely different story. If you are curious, I'm explaining all the related data modelling techniques in my book QlikView Your Business.
Cheers,
Oleg Troyansky
Check out my new book QlikView Your Business - The Expert Guide for QlikView and Qlik Sense
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sorry that I'm late to get back to this - lots of overtime recently.
If you read the whole thread, you may realize that while Oleg and I may still not see eye to eye on synthetic keys, he significantly influenced my opinion. I argued with him because he is one of the people I most respect, and in the end, it was my opinion that changed rather than his, even if it didn't come to match his exactly.
Magnus Åvitsland also changed my point of view by showing me a case where a composite key performs significantly better than a synthetic key, one of the two main things I challenged someone to show me in my initial post.
I still have synthetic keys in a few data models (the vast majority do not have them). They're still in my toolbelt. I might use them again. But they now feel dirty to me. They work. Those data models and apps perform just fine. But I'm left with a bad taste in my mouth that I didn't find a better solution. It feels, as Oleg says, "sloppy". I don't want to convert to composite keys, but surely there's a better way to model the data that avoids either. That I didn't think of one in the time I was able to devote to the problem feels like my failure as a designer and programmer. Mild failure. I'm not beating myself up over it. But I'm not proud of my synthetic keys either.
I did poke around at your data model when you first posted. It did feel like there would be a good way to concatenate the hours worked and hours planned to accomplish the sorts of things you were likely after. But I didn't come up with what I considered a satisfactory solution in the time I allowed myself to think about it. Perhaps I should have at least posted that much.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi John,
Thanks for the valuable insights. Can you please share the code/methodology used to calculate:
load time file KB RAM KB CalcTime
synthetic key removed 14:01 49,507 77,248 46,000 ms
synthetic key left in place 3:27 49,401 77,160 44,797 ms
It'd be grateful as it will function as a great add on while scripting.
Thanks and Regards,
Gagan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Gagan
A comment: The code for this example is not really relevant.
The takeaway should be: Handle synthetic keys when they occur.
This can be done in a couple of different ways - depending on your data:
1) Eliminate redundant datafield(s)
2) Concatenate or Join tables
3) Create Composite-key
It depends entirely on your data and data model.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi John (or Others),
I have found that automatically generated synthetic keys have their problems which are not just about performance, but accuracy. I have an extremely terrible example, proving that it has made an unknown mistake in a very complicated structure: Stacked $Syn Keys with Null Values
I know my data modeling does have very serious problems, but that's not an excuse to avoid product defects. The point is that the application doesn't report any errors, and the "problematic data model" has even passed functional tests.
If the program doesn't work properly because of hardware resource problems, it should report the problem in time; but that's not the case. The program runs steadily with this logic error.
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
"Unfortunately the actual limitations are virtually impossible to predict, which leaves only trial and error as a practical method to determine them."
It is terrible! It's like we're walking on a minefield. We are never sure whether we will step on the mines next. So I never walk minefields - completely abandon the use of synthetic keys!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
all is fair in love and war
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I could not agree. Qlik showed quite obviously (after a reload and within the tableviewer) that there are (multiple) synthetic keys and/or circular loops and that this might cause problems. Surely Qlik could break this with a runtime-error but I think this wouldn't be very user-friendly because after such a "failed" load the tableviewer makes it very easy to detect these issues so that you could correct them instantly.
In your case is not only the datamodel poorly built else also the testing has failed - has anyone ever looked per tableviewer into the datamodel and could comprehend and explain which data are there and how the are related to eachother? It's the first step before creating any object/calculation within the UI.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I had skipped this one, a post 8 years old somehow didn't pop up in my following list.
As Marcus mentions, the synthetic key is by no means an error, as it can be used on purpose, as John suggested in the original post.
The load will not fail because it is not a syntax error and QlikView cannot guess whether this is or not a data model error.
I don't see how this can be considered a product defect. As also mentioned in the other post, the complexity comes from the immense combinations and dependencies within your data model to see whether or not the synthetic key will cause problems, e.g.: how many combinations are possible, are the values numeric or strings, how long are these values, how many and how fast is the processor, how much memory does the computer have and a long etc. It will behave very similar to when you OUTER JOIN two tables, it can take forever and even not be possible with your computer resources or it can take a second or two.
Last but not least, this was written after QlikView 9 was released. Back then, the Ajax client (called Zero-footprint Client) was barely a thing. Performance wise, things have changed significantly since, especially in QlikView 12.x and the introduction of the new QIX engine.