Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- rest connector pagination
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
rest connector pagination
Hi,
I try to use the Rest Connector pagination
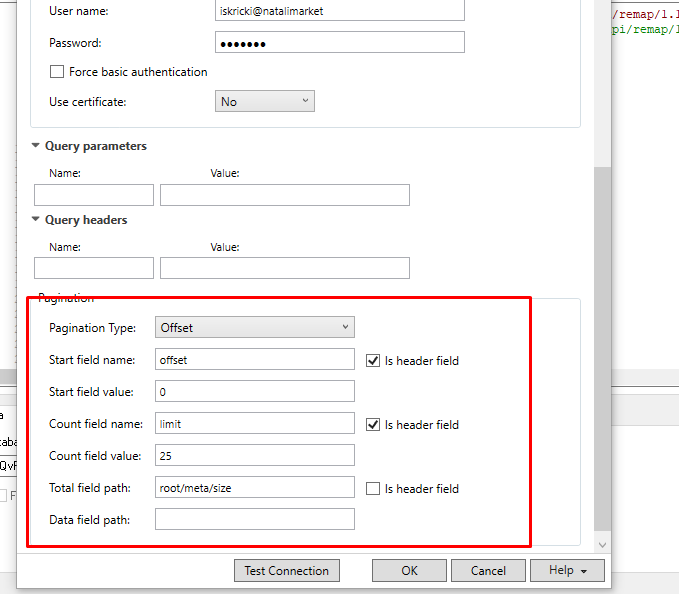
After load I get in table 8475 lines
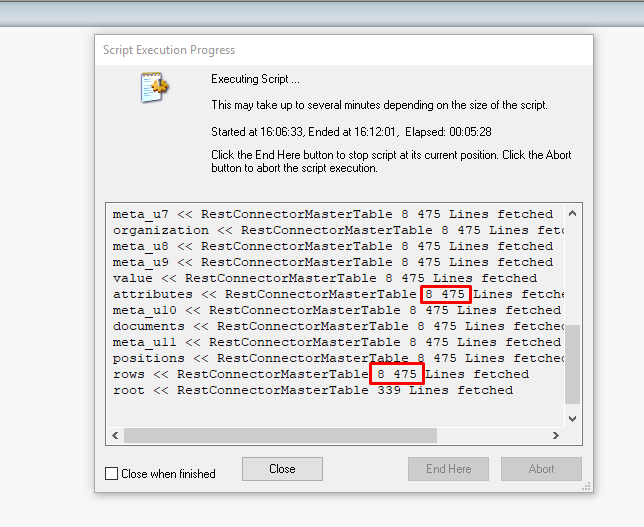
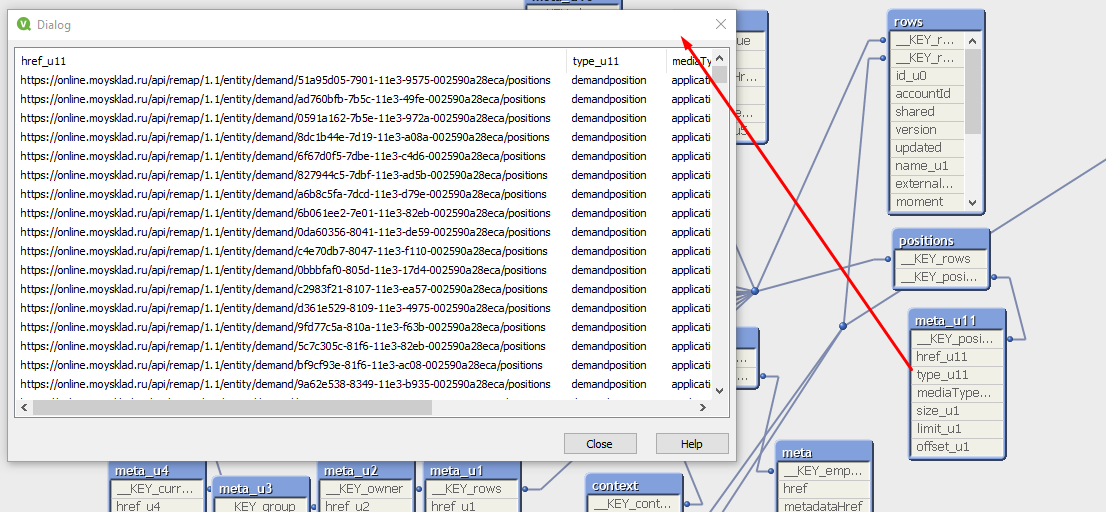
But in this tables I get not distinct lines ( only 25 distinct lines)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Maryna,
I had also a lot of trouble using the pagination in REST API.
I had a similar problem :
I am using REST API with JIRA.
I used Pagination : None and the pagination was managed in the script.
The code was :
// Implement the logic to retrieve the total records from the REST source and assign to the 'total'
// Getting the "total" value from the first API URL call
totalTable:
SQL SELECT
"total" AS "total_u1"
FROM JSON (wrap on) "root";
//This variable is a total of JIRA entries. Will be used later in 'For' loop
LET total = Peek('total_u1',0,'totalTable');
DROP Table totalTable;
LET totalfetched = 0;
LET startAt = 0;
LET pageSize = 999;
FOR startAt = 0 to total
TRACE "startAt: " $(startAt);
RestConnectorMasterTable:
SQL SELECT
"expand" AS "expand_u0",
"startAt",
"maxResults",
"total" AS "total_u1",
"__KEY_root",
(SELECT
...
...
FROM JSON (wrap on) "root" PK "__KEY_root"
WITH CONNECTION(
QUERY "startAt" "$(startAt)"
);
// Change URL included in 'WITH CONNECTION' as needed to support pagination for the REST source.
// Please see the documentation for "Loading paged data."
startAt = startAt + pageSize;
NEXT startAt;
all the pages have been read, but on each page the identifiers are repeated.
So instead of having the identifiers from 1 to 5000, I have 5 times 1, 5 times 1.... 5 times 1000.
The solution was to use Pagination "Offset":
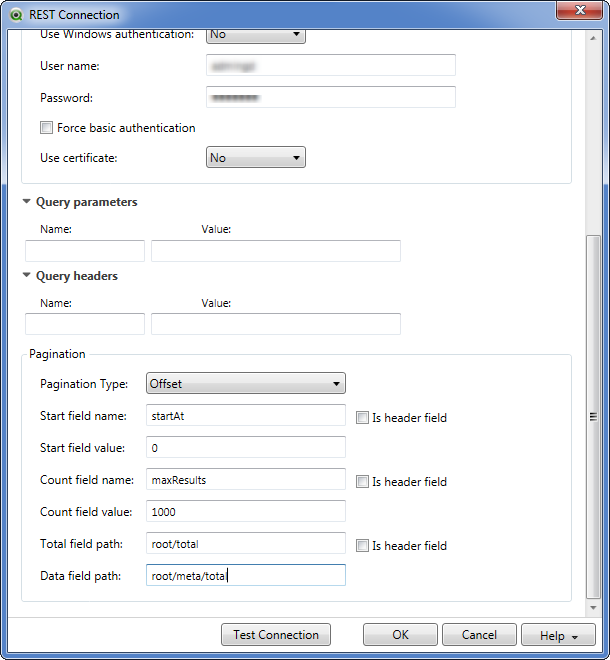
What is really strange, this solution works on our server.
Bur when I try to use this solution on my desktop, it does not get all the JIRA issues (if gets only 9400 out of 46000 ?!!!!).
And the best part is : The solution with pagination "None" and the scripting works fine.
Maryna, you could maybe try out the solution with the scripting...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Tanja,
Recently we got the requirement to connect to JIRA in Qliksense. We have connected to JIRA successfully using Rest connector.
Here I have one doubt. we have multiple APIs in JIRA Site to connect like Projects,Issues and comments.
first we have tried to extract the Issues. So entered the below URL and by enting Username and PW created a connection
and extracted the ISSUE root tables.
https://xxxxxxxxxxxxxxx/rest/api/2/Issues
Next to extract Project again do we have to create a new connection, because for Projects we have the different api url like below
https://xxxxxxxxxxxxxxx/rest/api/2/Project
Please let me know for each api extraction do we have to create a new connection or is there any better way.
Also right now we are pulling the apis just by entering the URL,Username and Password. We haven't used the Pagination. Without pagination do we assume we were pulling all the records in the API? Please help me on this.
Thanks in advance.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Manitha,
I don't think it's possible to avoid multiple connections if you have different URLs.
In QlikView, if you don't use pagination, you will be pulling the maximum number of records determined by JIRA (generally 1000 records).
If you have a lot of records you will probably need pagination.
As you're using QlikSense this might be different, so you should verify that you're pulling everything in one call.
Kind regards,
Tanja
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Manitha,
"
- 1. Still now i am following the procedure like this.
I have created three different Jira connections by entering Issues ,Projects and Search APIs on URL's as separate and pulling the tables into QVDs. In the created connection I am entering only URL like https://xxxxxxxxxxxxxxx/rest/api/2/Issues and selecting Method as GET then entering username and Password.
Please confirm is this correct procedure
"
I found a page with a lot of information concerning REST API :
"
- 2. In the Search Api which is like below https://xxxxxxxxxxxxxxx/rest/api/2/search contains the many tables like
Customfield_10409,Customfield_11102 etc... and one Fields table contains customfield_11100 as records.
Could you please explain about this API with custom fields what is the best way to join all these tables under search api.
"
If you need to read a lot of tables (Customfield_10409,Customfield_11102 etc... ), QlikView generates the script for you and reads the neccessary fields. Those tables are linked to a table named [fields].
If I need to do a join afterwards, I use the LOOKUP function :
JIRA_API_WATCHES:
NoConcatenate LOAD
__KEY_fields
, WATCHES
FROM [$(RepertoireQVDBRUT)JIRA_API_WATCHES.qvd](qvd);
JIRA_API_FIELDS :
NoConcatenate LOAD
[RESOLUTIONDATE]
, [CREATED]
, [DESCRIPTION]
, [SUMMARY]
,[RESOLUTION]
, [__KEY_issues]
, Lookup('WATCHES', '__KEY_fields', __KEY_fields, 'JIRA_API_WATCHES') as [WATCHES]
FROM [$(RepertoireQVDBRUT)JIRA_API_FIELDS.qvd](qvd);
Kind regards,
Tanja
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Tanja