Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Star & snowflake schema
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Star & snowflake schema
Hi
When we should go for star schema and Snow flake schema in qlikview
Thanks
Rand
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
It depends on your business requirement and table structures. And the key fields that you have in the model and the keys that you defines. Mainly we try Start schema to design.
Regards,
Anand
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
OK . But i would like to know on which circumstances we wil go for snowflake and star schema
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
for better performance star Than Snowflake
when you have Big fact tables you could use snow flake to break dimension hierarchies-> country,state,city
single fact and dimension with no secondary dimension in Star but snow flake with secondary dimension
data retrieval will fast on selection in star schema as dimenion are closely connected to fact.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Rgv,
Kindly check the attached image for Star Schema vs Snowflake Schema. I hope this will help you to understand in better way.
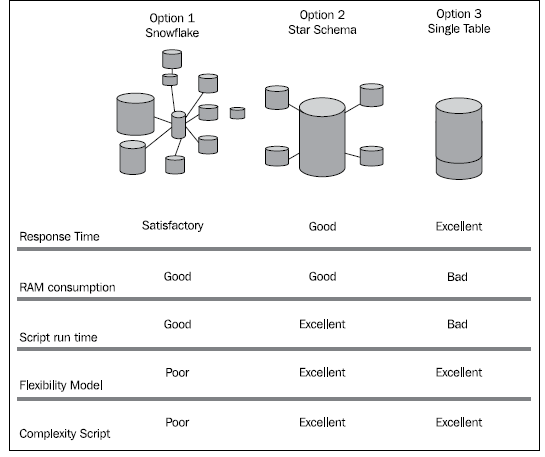
Kind regards,
Ishfaque Ahmed
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
it depends on your data model however most of the times it is preferred to use star schema having a single transaction table (fact table) with surrounding dimension/attributes table.
in general for qlikview it is better when you are writing an expression having a sum of two different columns of your data model that those two fields be in the same table, going from one table to another in qlikview consume more resources, however you do not want to end up with one single table in your data model as it will consume a lot of resources (RAM), therefore a star schema is the most appropriate one having only one link between the attribute tables and fact table.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Yes, there is no hard and fast rule where we should use star or snow flake schema.
As anand told it depends on your business requirement and table structures.
These data warehouse concepts are used to build data models in qlikview.
Merits of these concepts is to remove synthetic keys, circular loops, so performance is good
And minimum memory utilization is achieved.
Below are some differences for star and snow flake schema:
Star schema: It has single fact table connected to dimension tables like a star. In star schema only one join establishes the relationship between the fact table and any one of the dimension tables.
A star schema has one fact table and is associated with numerous dimensions table and reflects a star.
The Star Schema is highly denormalized.
A dimension table will not have parent table in star schema.
The dimensional table itself consists of hierarchies of dimensions.
Snowflake schema: It is an extension of the star schema. In snowflake schema, very large dimension tables are normalized into multiple tables. It is used when a dimensional table becomes very big. In snow flake schema since there is relationship between the dimensions Tables it has to do many joins to fetch the data. Every dimension table is associated with sub dimension table.
Snowflake schemas have one or more parent tables.
Hierarchies are split into different tables(Sub Dimensions).
The snowflake schema is normalized. So the data access latency is less in star schema in comparison to snowflake schema.
As the star schema is denormalized, the size of the data warehouse will be larger than that of snowflake schema.
Regards
Neetha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
When a dimension table is snowflaked, the redundant many-to-one attributes are removed into separate dimension tables. For example, instead of collapsing hierarchical rollups such as brand and category into columns of a product dimension table, the attributes are stored in separate brand and category tables which are then linked to the product table. With snowflakes, the dimension tables are normalized to third normal form. A standard dimensional model often has 10 to 20 denormalized dimension tables surrounding the fact table in a single layer halo; this exact same data might easily be represented by 100 or more linked dimension tables in a snowflake schema.
We generally encourage you to handle many-to-one hierarchical relationships in a single dimension table rather than snowflaking. Snowflakes may appear optimal to an experienced OLTP data modeler, but they’re suboptimal for DW/BI query performance. The linked snowflaked tables create complexity and confusion for users directly exposed to the table structures; even if users are buffered from the tables, snowflaking increases complexity for the optimizer which must link hundreds of tables together to resolve queries. Snowflakes also put burden on the ETL system to manage the keys linking the normalized tables which can become grossly complex when the linked hierarchical relationships are subject to change. While snowflaking may save some space by replacing repeated text strings with codes, the savings are negligible, especially in light of the price paid for the extra ETL burden and query complexity.
By Margy Ross
© Kimball Group
You can check Kimball data modeling
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you all for ur time
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It all depends on your Requirement and Data size , STAR will have better performance but in certain case it might add more data to the qvw ....
- « Previous Replies
-
- 1
- 2
- Next Replies »