Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Blogs
- :
- Technical
- :
- Design
- :
- To Join or not to Join
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
The QlikView internal logic enables a data model with several associated tables. It not only allows – it encourages you to use several tables when building a data model.
This is very different from many other BI or query tools where, when several tables are used, they are all are joined together into one table. The most obvious example of this difference is a simple SELECT statement. With it, you can use several tables as input and join them, but the output is always one single, denormalized table.
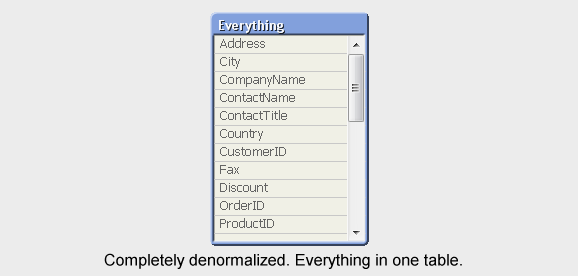
With QlikView, in contrast, you can have a multi-table relational data model that is evaluated in real-time. The associations are evaluated as joins at the moment when the user makes a selection in the application. At the same time, all objects, some with complex calculations based on these joins, are recalculated.
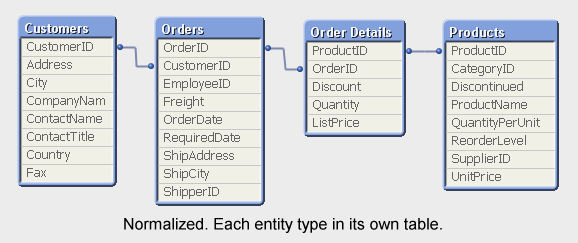
When creating the QlikView data model, you have a choice of loading the tables as several entities or joining some of them together. Joining in the script means that the result of the join is stored in the QlikView data model as one single table.
So what should you do? Is it better to keep the data model normalized (many tables) or is it better to de-normalize (fewer tables)?
My view is that it usually is better to keep the data model as normalized as possible. A normalized model has many advantages:
- It is memory efficient.
It is, by definition, the data model that uses least memory. - It is CPU efficient.
In most cases, QlikView calculations in a normalized model are as efficient - or only marginally slower - as in a denormalized model. In some cases the normalized model is faster. - It is easier to understand and manage.
It should be possible for other developers to read your script: A simple script with as few transformations as possible, is a script that is easy for other developers to understand and maintain. - It minimizes the risk for incorrect calculations.
Joins potentially change the number of records in the tables, which means that a normal Sum() or Count() function cannot always be used – they would sometimes return an incorrect result. You may counter that there is always a way to write a correct formula, but my point is that it should also be easy. Expressions in server objects will be written by users that do not have special knowledge about the data model in the app.
But it is not a clear-cut case.
Often there is a trade-off between memory efficiency and CPU efficiency. In other words, there are cases where you can decrease response time by letting the data model use more memory; where performance will be better if you make the join in the script.
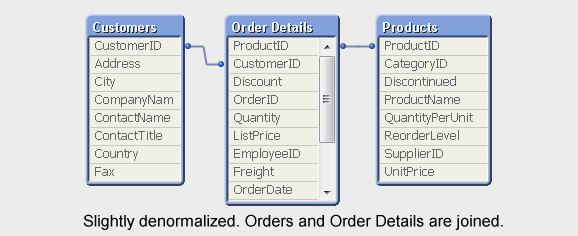
One such case is if you have two very large fact tables, like Order Headers and Order Details. An other is if you have chart expressions containing fields from different tables. Then QlikView has to perform the join in memory generating a virtual table over which the summation will be made. This can be both memory and CPU demanding, so you might get a better performance if you have made the join already in the script. But the difference is sometimes only marginal. You need to test, to be sure.
Bottom line is that you’ll have to weigh pros and cons. Don’t join unless you have to. If performance is important and you experience a noticeable improvement when you join, then you probably should join. But ask yourself what the implications are. Is the script still manageable? Can a user understand how the formula should be written?
The best join is often the one that never is made. Often – but not always.
See more about this topic in the Technical Brief about Joins and Lookups
- « Previous
-
- 1
- 2
- 3
- 4
- Next »
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.