Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics & AI
- :
- Products & Topics
- :
- Connectivity & Data Prep
- :
- Re: Direct Discovery of AWS Redshift - QS Applicat...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Direct Discovery of AWS Redshift - QS Application Filtering Slow
Hi All,
I am currently querying the following table of approx. 200m records in redshift from an EC2 instance within the same region, but filtering on the charts is returning really slow. Performance on the ec2 instance and redshift cluster is good, but interestingly I cannot see the queries triggering on the AWS Redshift console when I filter charts.
Filtering on the charts is really slow, with them rendering after 1 minute or more.
Does anyone know why this might be?
Redshift Table:
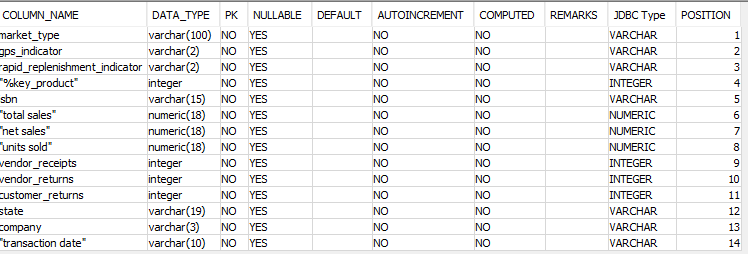
The AWS ec2 instance spec:
m4.16xlarge | 64 vCPU | 256 Gib Memory |
The AWS Redshift cluster:
dc2.large | |
7 EC2 Compute Units (2 virtual cores) per node | |
15.25 GiB per node | |
160GB SSD storage per node |
The DIRECT QUERY code from my Qlik Sense application:
LIB CONNECT TO 'Amazon Redshift ODBC DSN 2 (qlik-sense_administrator)';
direct QUERY
DIMENSION
"market_type" as MARKET_TYPE,
"gps_indicator" as GPS_INDICATOR,
"rapid_replenishment_indicator" as RAPID_REPLENISHMENT_INDICATOR,
"%key_product" as %Key_Product,
isbn as ISBN,
state as State,
company as Company,
"transaction date" as "Transaction Date"
MEASURE
"total sales" as "Total Sales",
"net sales" as "Net Sales",
"units sold" as "Units Sold",
"vendor_receipts" as VENDOR_RECEIPTS,
"vendor_returns" as VENDOR_RETURNS,
"customer_returns" as CUSTOMER_RETURNS
FROM publytics."public"."sales_str2";
The Data Model (ONLY THE FACT TABLE IS NOT IN-MEMORY AND QUERIED FROM REDSHIFT):
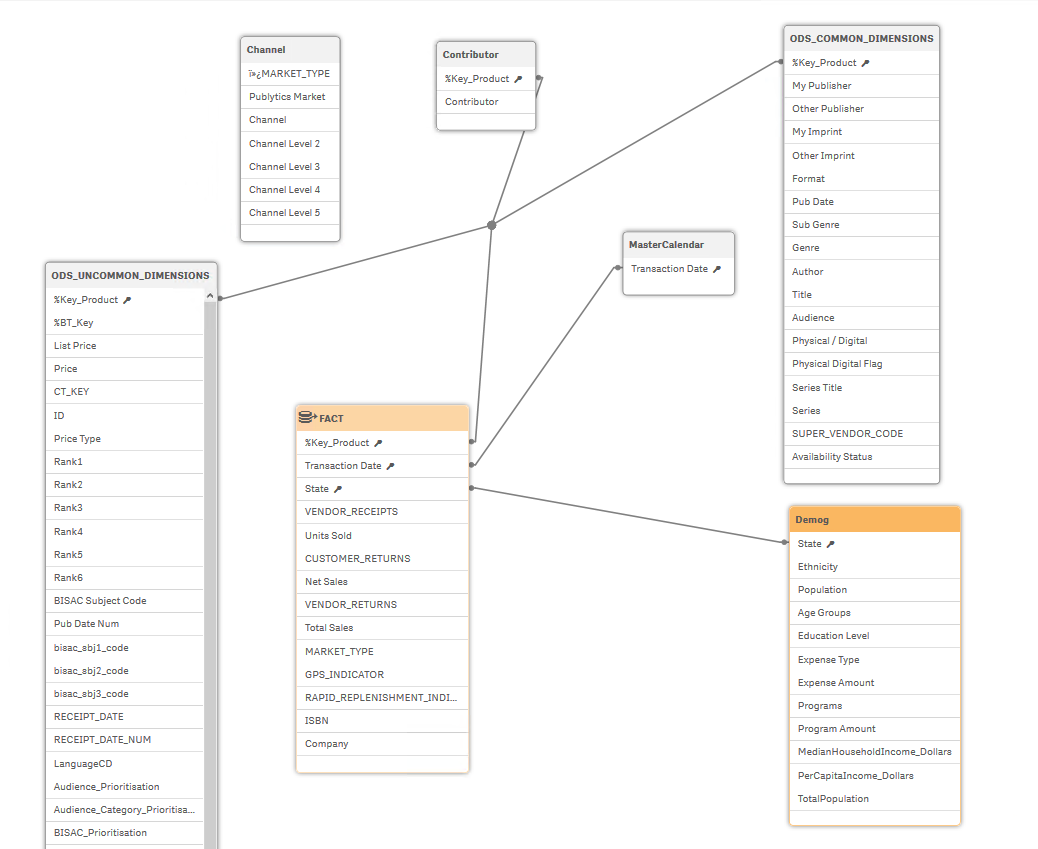
Any suggestions welcome,
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Cam1988,
I am also having the exact same issues.
Did you manage to resolve this issue or perhaps share your workarounds that you might have done to improve performance.
Thank you,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
are you able to improvise performance?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@BITechie Unfortunately we couldnt, we ended up not going the Direct Discovery route.
We ended up using Dynamic Views and ODAG(with the detail app still pointing to redshift in case a user requires a more detailed selection) for our requirements.
we also used a tool called Dremio as a semantic layer for our QVD generation( This improved perfomance significantly as opposed to generating the QVD's directly from the huge redshift table)