Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- Deployment & Management
- :
- Re: 8 node limit for Qlik Sense architecture
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
8 node limit for Qlik Sense architecture
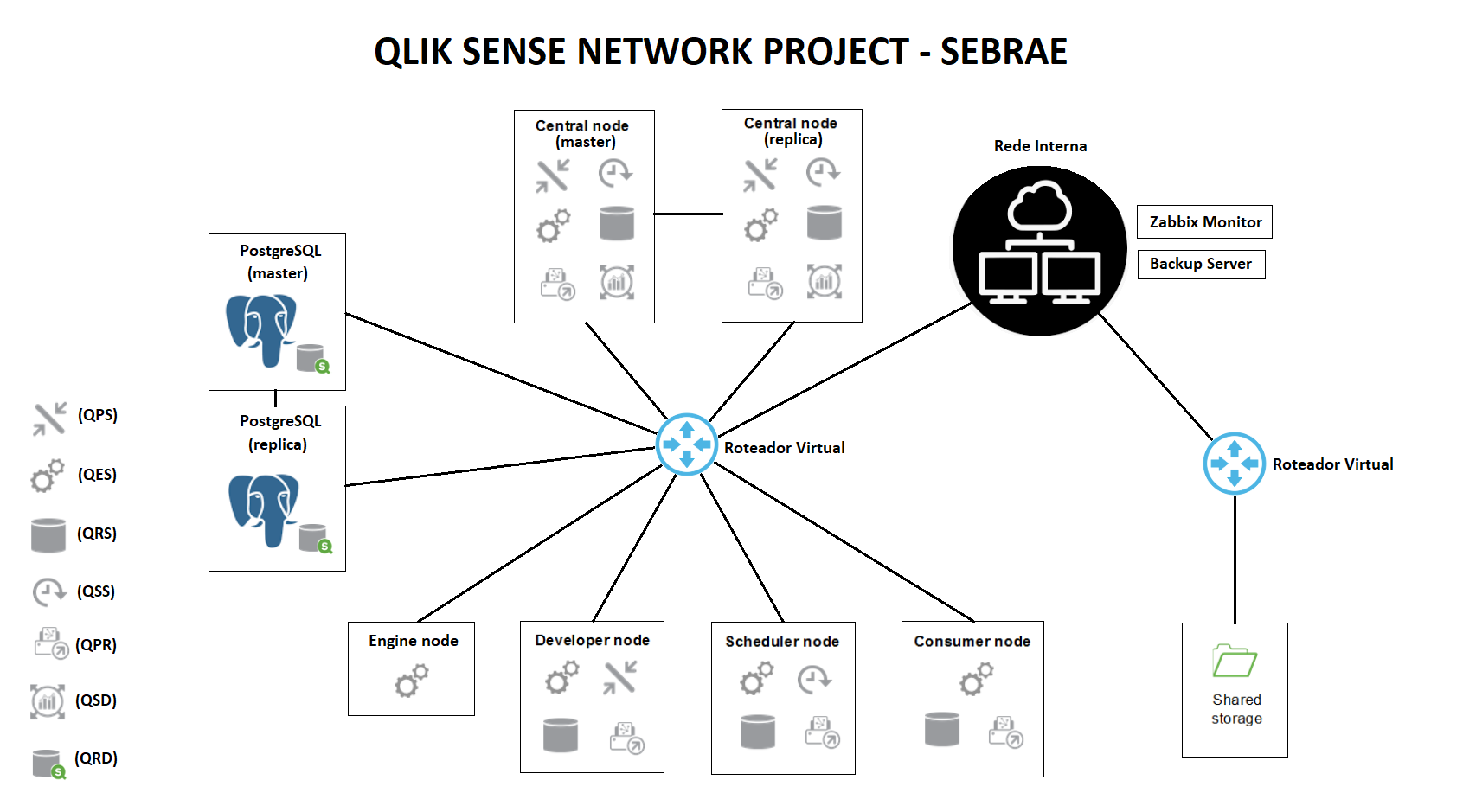
After reading several documents, I have now formulated what I believe is the best possible Qlik Sense architecture (illustration below).
By this I mean best practices recommended by Qlik via various documents have been incorporated. For example the deployment guide for AWS mentions the benefits of having a external load balancer (nginx or haproxy) and it makes a lot of sense. The STT published in October mentions the possibility of having a active secondary node.
It would be nice to get some feedback on this illustration. I'm however wondering if the "8 node maximum" limit is going to stay long because with that my architecture would not scale horizontally. ie. I can only have two proxy nodes and two engine nodes and not more.

If I make the secondary node also a scheduler, I could add another engine node but that's about it.
Is the 8 node limit therefore hard coded or is it just a soft limit defined by qlik support. In the beginning the above configuration will be more than sufficient for my client, but before I propose this I would like to know if scaling beyond 8 nodes would be a reality in the future.
I have also seen some hints suggesting an architecture based on containers would be available in the near future which suggests that we would be able to scale beyond 8 nodes. Would be nice to hear some thoughts from the experts on this board.
References
1. STT - Failover in Qlik Sense.
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Levi,
12 nodes is the limit for Engine nodes. What about scheduler and proxy? Or is it we can have 12 nodes max in overall architecture.
Thanks,
Jai
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The current feedback from the R&D team is 12 nodes, period.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, my name is Leonardo, and im planning a very big archtecture at this moment, and woud like to know if your archtecture worked fine. How is the behaviour, what were the difficulties, why didnt you propouse a deployment and a consumer node?
I'am planning to use fallover as master and replica, if master falls down replica assumes all the roles, but not for all the nodes, just for central and DB PostgreSQL.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Leonardo,
Regarding your question, we have set up the following environment:
- 1 H/A virtual machine node which hosts the repository DB as well as the shared folder (encrypted & h/a storage)
- 2 external (DMZ) Proxy Nodes - (accessed by external users)
- 2 internal Proxy Nodes - (accessed by internal users) - the NLB feature of Windows Server O/S was utilized
- 2 nodes for Central & Failover
- 6 Engine Nodes (1 per Customer Department)
In this case we faced the following:
- Extensive network & firewall configuration. (URL: https://help.qlik.com/en-US/sense/September2018/Subsystems/PlanningQlikSenseDeployments/Content/Sens...)
- Creation of custom security rules to create different user types (e.g . developers, consumers).
- Creation of custom load balancing rules to serve certain applications on specific Nodes of the deployment.
- Creation of custom properties for the Department as well as User Types.
- Enable only TLS v.1.2.
- Removal of Qlik service account from the Local Administrators group on each machine.
- Use of 3rd party certificate by the Proxies.
- Use of Qlik-Cli to automate certain administrative tasks (e.g. automatically move applications between test & production environment).
- Installation & configuration of 3rd parth ODBC drivers to access specific data sources.
- Creation of a stress test plan by utilizing Qlik Scalability Tools and Hardware Benchmarking Package.
According to the following documentation entry:
Title: Persistence
The requirements for the share are:
- The Qlik Sense nodes in the cluster must have network latency below 4 milliseconds to connect to the file share server. Performance can degrade if this is not the case.
- The bandwidth to the file share must be appropriate for the amount of traffic on the site. The frequency and size of the apps being saved after reloading, and opened into memory, drives this requirement. 1 Gigabit networking is suggested.
I wish you an error-free Qlik Sense deployment!
Best regards,
iLiAS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your replay and help Ilias,
Its a great archtecture you have!
I have some questions about it:
1 - Why didnt you use a local network storage as the shared folder?
2 - These proxyes are HA? using Windows NBL?
3 - these 6 engine nodes... how are they organized, like 2 for external user access panels, 1 develeper, 1 scheduler... ?
Thanks for your help!
Best Regards,
Leo
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Regarding your questions:
1. The customer has attached the UNC Shared Folder on a Highly Available, encrypted storage mechanism.
2. We have two Proxy nodes, which receive user requests via Windows NLB Feature. So, end-users access a virtual IP and then redirected to one of those nodes.
3. The Engine Nodes are assigned on the following way: 1 node per department (# of Depts = 5) + 1 spare node.
Finally, we have separate / isolated Qlik Sense Servers for development purposes of each department.
Thanks,
iLiAS
- « Previous Replies
-
- 1
- 2
- Next Replies »