Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Discover
- :
- Blogs
- :
- Product
- :
- Design
- :
- Who do the Kudu that you do?
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
In this edition of the Qlik Design Blog, our Emerging Technology Evangelist, David Freriks is back discussing integration between Qlik and Kudu.
Navigating the analytics labyrinth with integration of Kudu, Impala, and Qlik
![]() Using Hadoop for Big Data analytics is nothing new, but a new entity has entered the stale file format conversation with the backing of Cloudera – you might have heard of it, it’s called Kudu.
Using Hadoop for Big Data analytics is nothing new, but a new entity has entered the stale file format conversation with the backing of Cloudera – you might have heard of it, it’s called Kudu.
What is Kudu?
Let’s first take a step back and think about the dullest topic in the universe, file system storage formats. Flat files, AVRO, Parquet, ORC, etc. have been around for a while and all provide various advantages and strategies for data access optimizations in an HDFS construct. However, they all suffer from the same issue… static data that can only be appended to – unlike a real database.
So, enter Kudu – defined by Apache: “Kudu provides a combination of fast inserts/updates and efficient columnar scans to enable multiple real-time analytic workloads across a single storage layer.” Deconstructing that message – Kudu acts as a columnar database that allows real database operations that aren’t possible in HDFS file formats. It is now possible to interact with your Hadoop data where INSERTS, UPDATES, DELETES, ALTERS, etc. are now available as data operations. This means not just read/write capabilities for Hadoop , but also interactive operations without having to move to Hbase or other systems. IoT use cases, interactive applications, write-back, and traditional data warehousing are now possible without adding layer upon layer of additional technologies.
Now that we have a general understanding of what Kudu can do, how does this benefit Qlik? Kudu is fast, columnar, and designed for analytics – but with the ability to manipulate and transform the data to power new use cases.
Let’s start simple by showing how easy it is to move some data from an Impala table on Parquet into Kudu.
Starting in Hue we need to do some basic database-like work. To put data into a table, one needs to first create a table, so we’ll start there.
Kudu uses standard database syntax for the most part, but you’ll notice that Kudu is less specific and rigid about data types than your typical relational database – and that’s awesome. Not sure if your data is a varchar(20), or if it is smaller or larger? No worries, with Kudu – just declare it as a basic string.
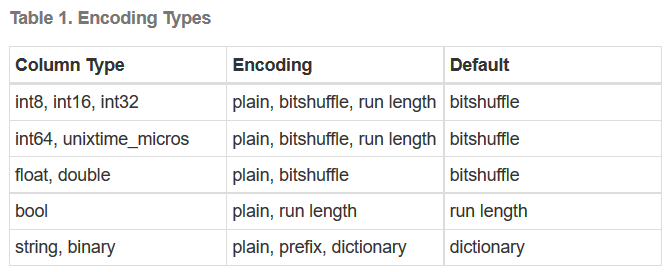
Numerical data are basic as well, there a just few types to choose from based on the length of the number. This makes creating columns and designing a schema very, very straightforward and easy to setup. It also reduces data type problems when loading data.
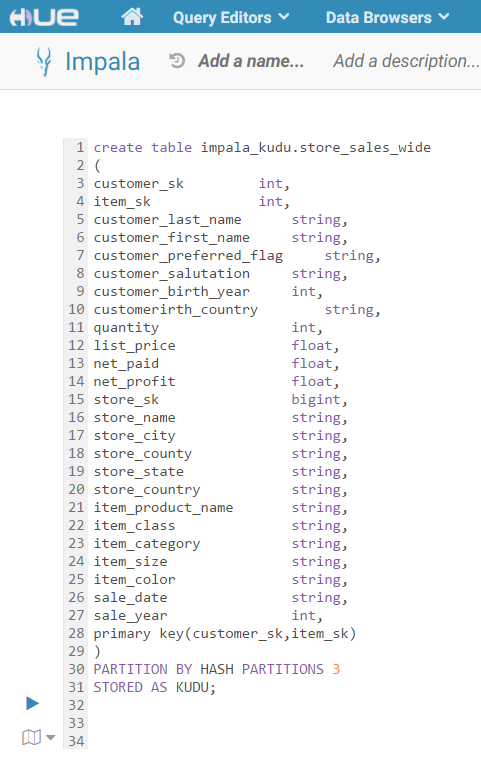
Having a general understanding of table creation, we will go ahead and create a table we are going to copy from Parquet. It’s worth noting there are some differences here versus creating a Parquet table in Hue.
• First: A Kudu table needs to have at least 1 primary key to be created.
• Second: A Kudu table needs a partition method to distribute those primary keys
Referencing the schema design guide, we are going to use a HASH partition and use the number 3 (since we have 3 worker nodes).
In summary, we have a bunch of strings, a few integers, and some floating decimals to represent prices and profit. We’ve identified our keys and specified our partitions – let’s roll!
The query runs for a second and viola – we have our new (albeit empty) table. Next, we need some data. We have an existing table that we would like to copy over into Kudu. We will run another query to move the data and make a little tweak on the keys to match our new table.
We had to cast our customer_sk and item_sk columns from string in Parquet to int in Kudu but that’s pretty easy to do as shown in the SQL here.
We run the INSERT query and now we have our data moved over into Kudu, and even better – that table is now immediately available to query using Impala!
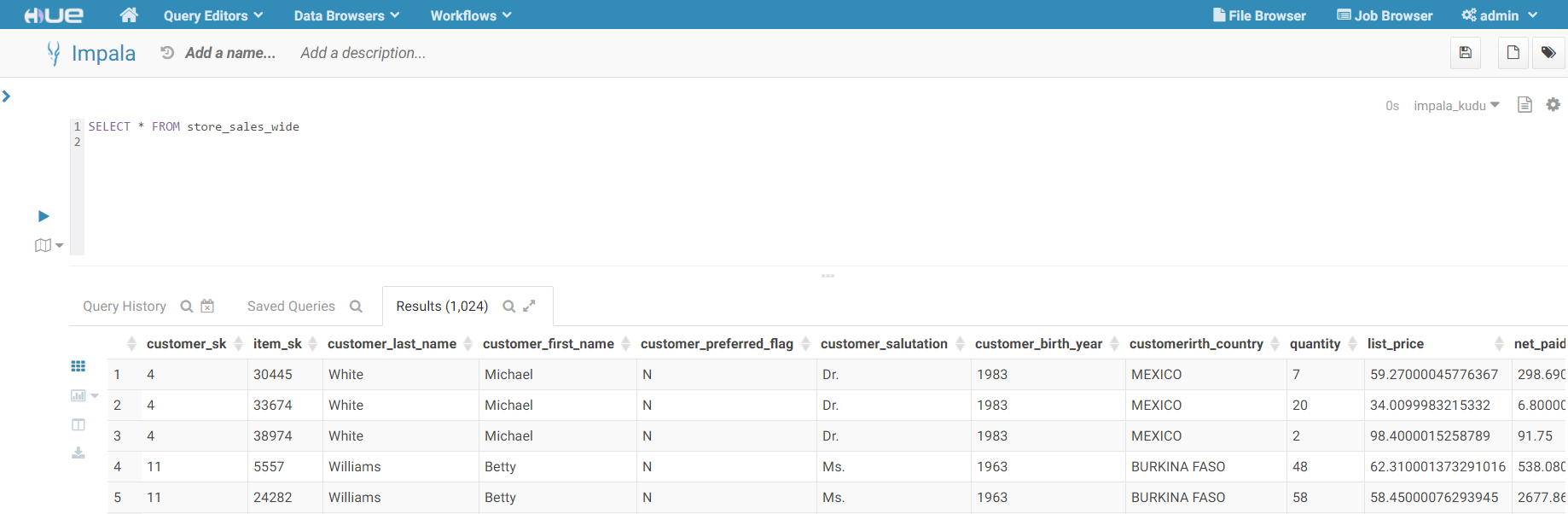
Enter Qlik
With the data loaded into Kudu and exposed via Impala – we can now connect to it with Qlik and start building visualizations.
Using the latest Cloudera Impala drivers , we start the process of building a Qlik app by connecting to our new data set.
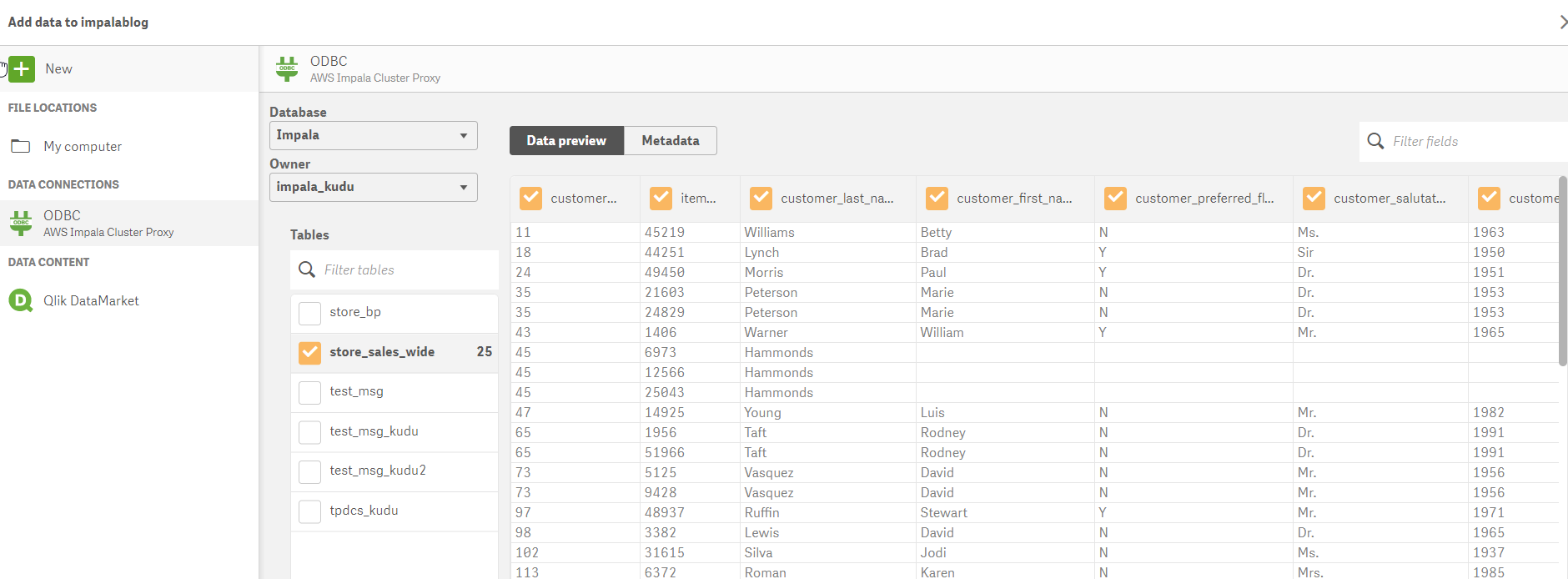
Opening Qlik Sense, we will create a new connection to our cluster and select our new table.
Once we have the table and columns selected – we can modify the load script created by the data manager to directly query Kudu (versus loading the data into memory) to take advantage of the speed and power of Impala on Kudu.(we do this using Direct Discovery - NOTE the Direct Query syntax) This change is accomplished with a slight alteration in the syntax to identify dimensions and measures.
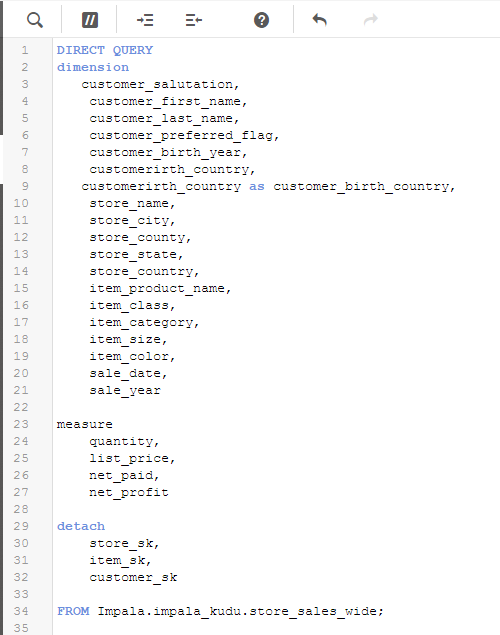
We now have live queries running against Kudu data sets through Impala.
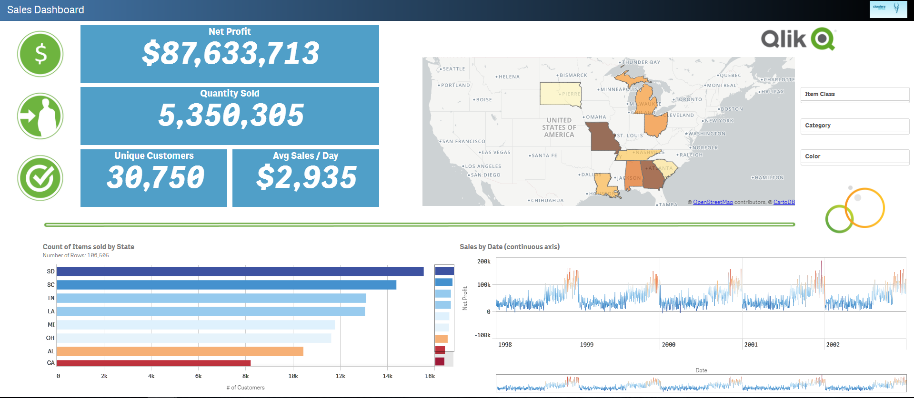
The great part about Kudu is that we’re just getting started with the possibilities of how we can leverage the technology with Qlik. Some things we’re cooking up for the not too distant future involve write-back with Kafka and Qlik Server Side Extension integration – so stayed tuned.
Please visit cloudera.qlik.com for more demos and to see the Kudu demo in action.
Regards,
David Freriks (@dlfreriks) | Twitter
Emerging Technology Evangelist
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.