Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView Administration
- :
- Re: Join takes its time
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Join takes its time
Hi All!
Im trying to join these tables to get one fact table in order to compare different versions of a forecast. This is what I am trying to do:
Facilities:13 000 rows
LEFT JOIN
Forecast: 780 000 rows
However it takes ages (1 hours) and they share only one key Facility_ID. Ive got 32 GB ram.
Can anyone help me understand whats going wrong?
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
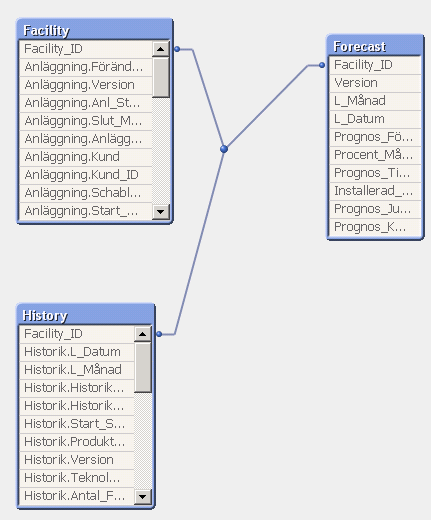
Can you share your script and the data model snapshot how it looks ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
why not doing it the other way around.
Forecast
left Join
Facilities
If you use few fields from Facilities, use applymap instead.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi!
It looks like this from the start. Im just making a simple join like this:
Forecast_temp:
LOAD
Facility_ID,
Föränd,
Vers,
FROM
Facility.QVD(qvd);
LEFT JOIN (Forecast_temp)
LOAD
Facility_ID,
Vers,
FROM
Forecast.QVD(qvd);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Staffan
Thank you for you answer.
I have tried the other way. And also removing several fields. It still takes a lot of time. I am removing all the fields that I use Apply mapp on.
If concatenate it goes really fast. However I want for each facility its forecasted values (each month).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What happens if you dont use joins? Did you try like below?
Facility:
LOAD
Facility_ID,
Föränd,
Vers,
FROM
Facility.QVD(qvd);
Forecast:
LOAD
Facility_ID,
Vers AS ForecastVers
FROM
Forecast.QVD(qvd);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You Join on two fields, FacilityID and Vers, do a composite key instead, FacilityID &'|'& Vers in both.
Forecast_temp:
LOAD
Facility_ID & '|' &Vers as %Key
Föränd
FROM
Facility.QVD(qvd);
LEFT JOIN (Forecast_temp)
LOAD
Facility_ID & '|' &Vers as %Key
FROM
Forecast.QVD(qvd);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is Facility_ID a unique key to Facility.qvd? You have 13000 unique facilities? If it were not a unique key, it could easily explain what you're seeing. Say you had 130 unique facilities, 100 rows for each, some data fields that are different, even if they aren't different for the data you're using. For instance, the facilities table has a row per facility per month, and you have 100 months of history in the table. Then you'd see 78,000,000 rows being generated, which might take ages to load, and you definitely wouldn't have what you wanted when it finished.
I also agree with Staffan with joining in the other direction. I'd agree with applymap too, but if the data is as described, and that's a unique key, this should go so fast you probably wouldn't notice any difference.
Also, I'm doubting the "they only share one key" bit when you have Vers being loaded from both QVDs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi John,
No its not unique for the table. This is the tricky part, there is a unique set for each version of the data. So whenever the business adjusts the forecast values or the values for the facility we get a new version. However version and facility_id is unique in facility table and corresponds to 12 months of data in the forecast table, so 12 rows per facility per version.
Yes version is the same but I have tried without version. I will try again. How can I apply mapp here?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi again,
So I created a composite key of Facility_ID and version and loaded distinct values from the facility and works just fine now. However I would like your opinions about how to approach the rest, Apply map and only keep IDs?
- « Previous Replies
-
- 1
- 2
- Next Replies »