Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Blogs
- :
- Technical
- :
- Design
- :
- Excluding values in Set Analysis
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
In Set Analysis, it is straightforward to make selections; to define the criteria for inclusion. But it is not as straightforward to define an exclusion. But there are in fact several ways to do this.
First of all, an inclusion can be defined the following way:
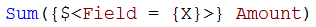
This expression is equivalent to saying “Sum the Amounts where Field equals X”.
But if you want to say the opposite – “where field does not equal X” – it becomes more complicated. The relation “not equal to” is not a Set operation. However, one way to do this is to use the implicit exclusion operator:
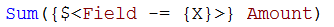
Note the minus sign in front of the equals sign. This will create an element set based on the existing selected values, but with the value X removed.
A second way to do this is to use the unary exclusion operator:
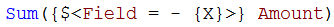
This will return the complement set of X and use this as element set in the set expression.
In many situations the two methods return identical sets. But there are cases when they are different. In the table below you can see that it makes a difference if there already is a selection in the field.
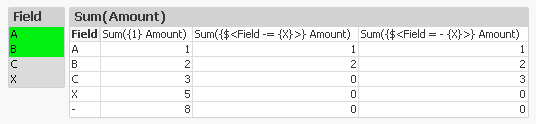
Note the difference on the row with the C. Since the implicit operator (the 2nd expression) is based on current selection, also the value C is excluded from the calculation. This is in contrast to the unary operator (the 3rd expression) that creates a completely new element set, not based on current selection.
We can also see that both of the above expressions exclude records where the field is NULL (the line where Field has a dash only). The reason is simple: As soon as there is a selection in the field, the logical inference will exclude NULL in the same field.
So what should you do if you want to exclude X but not NULL?
The answer is simple: Use another field for your selection. Typically you should use the primary key for the table where you find the Amount.
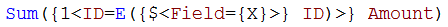
Here you need to use the element function E(), that returns excluded values. Hence, the above Set expression says: “Select the IDs that get excluded when selecting X.”
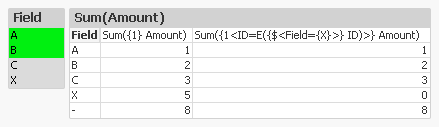
The table confirms that we get the records we want: X is excluded but NULL is still included.
With this, I hope that you understand Set Analysis somewhat better.
Further reading related to this topic:
- « Previous
-
- 1
- 2
- 3
- 4
- Next »
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.