Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
Analytics & AI
Forums for Qlik Analytic solutions. Ask questions, join discussions, find solutions, and access documentation and resources.
Data Integration & Quality
Forums for Qlik Data Integration solutions. Ask questions, join discussions, find solutions, and access documentation and resources
Explore Qlik Gallery
Qlik Gallery is meant to encourage Qlikkies everywhere to share their progress – from a first Qlik app – to a favorite Qlik app – and everything in-between.
Qlik Community
Get started on Qlik Community, find How-To documents, and join general non-product related discussions.
Qlik Resources
Direct links to other resources within the Qlik ecosystem. We suggest you bookmark this page.
Qlik Academic Program
Qlik gives qualified university students, educators, and researchers free Qlik software and resources to prepare students for the data-driven workplace.
Recent Blog Posts
-
Improved in-app and space navigation, and more
Exciting New Features to Enhance Your Experience Welcome back, everyone! At Qlik, we’re committed to improving your experience every day. We understan... Show MoreExciting New Features to Enhance Your Experience
Welcome back, everyone!
At Qlik, we’re committed to improving your experience every day. We understand how valuable your input is, and we prioritize acting on it. Whether through comments, community interactions, or other channels, your ideas fuel our design work. Our goal is simple: to create intuitive, efficient, and tailored tools for your needs.
Let’s dive into what’s new and improved!
Key Updates and Features
- Customizable UI enhancements
Moving all app assets to one place was a long-term improvement. And we knew that this breaking change would be cumbersome for some of you long-term users.
In addition to solving that problem, we give you even more control over your interface:
Our new customizable UI features let you:
- Replace the Asset button with Bookmarks and Sheets as shortcuts to streamline navigation
- Change the logo in the top bar
- Remove other elements in the top bar, menu, etc - Space-nav
Instead of navigating via the logo as you could in the past, we’ve introduced a more innovative way to show which space your app belongs to. This feature lets you seamlessly navigate back to a pre-filtered catalog view of your space. - App Details at Your Fingertips
Say goodbye to back-and-forth navigation! You can now view all relevant app details directly within the app. From app ownership to key metadata, everything is at your fingertips.
Plus, you can take actions like favoriting or reloading apps without leaving the app. - Mini homes
Our new "Mini Homes" are designed to simplify asset creation and management in the Analytics Activity Center. With dedicated areas for key activities like visualizing, analyzing, and preparing data, Mini Homes provides focused environments that boost productivity.
We’ve expanded the Analytics Activity Center to include:
- Visualize and Analyze: Access pre-filtered views tailored to your activities.
- Prepare Data: Leverage scripts and upcoming features to handle your data.
- Predict: Create and manage machine learning models effortlessly.
- Answer: Build Assistants that can answer questions based on unstructured data
- Automations: Utilize our powerful application automation tools. - “Add New” button
Last but not least, we’ve added the “Add New” button, making creating new assets directly from the catalog easier than ever.
Improved consumer experience
We aim to reduce cognitive load and enhance usability for you and your end-users. By enabling deeper customization, simplifying navigation, and centralizing key actions, we help you focus on what matters most: delivering value to your audience.
A fully customizable experience
Customization is the cornerstone of these updates. With options to tailor every aspect of your app’s interface—from toolbar items to logos—you can create an app that’s uniquely yours. These changes empower you and ensure a cleaner and more intuitive experience for your consumers.
What’s next?
We’re not stopping here. More enhancements are planned to ensure that our product continues to exceed your expectations.
Stay tuned for updates, and keep sharing your valuable feedback!If you want to see a demo, please head over to Linkedin.
Thank you, and let me know in the comments below.
- Customizable UI enhancements
-
Public collections: A powerful way to organize content
Welcome back Fredrik! Please join me in welcoming Fredrik Lautrup back to the Qlik Design Blog as he covers, Public Collections: A powerful way to o... Show MoreWelcome back Fredrik!
Please join me in welcoming Fredrik Lautrup back to the Qlik Design Blog as he covers, Public Collections: A powerful way to organize content. Fredrik is a long time Qlikkie, leading our product designers in our Product Design Group. Fredrik’s analytics experience stems from working with many customers in areas of product design, security and licensing. He has worked with numerous enterprises in different roles - from IT, security to strategic information systems and is responsible for design and workflow of our products.
Get Organized!
Currently, Qlik Cloud offers ways to separate access control, organization, and quality processes through the solutions of spaces, collections, and publishing. We initially focused on getting the access control and quality process to the right level, and now it’s time to improve the organization.
In our initial releases, favorites and collections were all about “you.” This was your way to ensure you could find relevant content with minimal effort. This was not a corporate view, or a view pushed onto you.
Looking at how users use the platform, we’ve realized that there’s a big need for curated content delivered to users to help them find the right content. Introducing this capability would allow a curator to decide what’s relevant for their users based on their role.
Public Collections
To address this need, we recently introduced public collections. Administrators of content can create collections where they group content and make them public (available to all). Collections are not about access control, so people looking at the collections can still only see what they have access to and only collections where they can access content. The content is now organized by a curator in topics independent of how the content needs to be secured by spaces. A Collection is a flexible concept that allows you to organize your content in a way that makes sense for your users. It enables you to group content from multiple spaces, and the same content can be in many collections. This makes it a pure concept for organizing content.
When used correctly, you as a consumer of content no longer need to worry about the spaces. The spaces are there in the background for administrators to ensure you have access to the right content. Collections are there for your consumers to find content in logical groups such as topics, projects, teams, and more. You can see an illustration below of how it could work.
I hope you have enjoyed getting an insight into how we think when designing the eco-system for content. If you have questions or ideas, please do not hesitate to share them with us. Also please check out the SaaS in 60 video below to get a quick introduction on how Public Collections work.
View more in 60: https://www.youtube.com/playlist?list=PLW1uf5CQ_gSq6klZOXSpKQ0afQFJyqqEh

-
Qlik Digest - December 2024
One Company. One Vision. And a 9x Leader in the Gartner Magic Quadrant for Data Integration Tools. Qlik is proud to be recognized as a leader in the ... Show MoreOne Company. One Vision. And a 9x Leader in the Gartner Magic Quadrant for Data Integration Tools.
Qlik is proud to be recognized as a leader in the 2024 Gartner Magic Quadrant for Data Integration Tools. Find out why in your complimentary copy of the report.
14x Olympic Medalist. 16x World Record Breaker. And Qlik Connect Keynote Speaker
Katie Ledecky, an unparalleled force in global athletics, is renowned as one of the greatest athletes of her generation — and is joining Qlik Connect 2025.
With 14 Olympic medals and 21 World Championship titles — the most ever by a female Olympian — she has shattered records and set new standards of excellence. Ledecky's journey began at the 2012 London Olympics, where, at just 15, she became the youngest U.S. Olympian and won her first gold medal in the 800-meter freestyle, signaling the start of a historic career
The Gartner Hype Cycle for Data Management
2024 has been a transformative year for data management, with AI & cloud-driven innovation reshaping how we manage data. But with so many emerging technologies, how do you separate hype from real value?
The Gartner Hype Cycle for Data Management, 2024 offers critical guidance, helping organizations to stay ahead and drive real-world business impact. From real-time integration and AI-driven data quality to the rise of data products and emerging open formats like Apache Iceberg, the future of data management is evolving rapidly.Qlik Reporting Service: Announcing a PixelPerfect Update!
Qlik Reporting Service now has PixelPerfect authoring, report cycling, and report task history. Life is easier with real-time data, customizable templates, simple interfaces, and powerful analytics. All your reporting needs. All met by Qlik Cloud Analytics.
Qlik Replicate November 2024 General Availability Release
Qlik is uniquely placed by offering several methods of replicating data in real time, with ease, automation and the added ability to combine it with other data seamlessly. SAP and Oracle continue to be mission-critical systems for many organizations, and two new endpoints have been added to enable the most efficient ways to replicate data from these two powerhouses.
- New SAP OData source endpoint
- New Oracle XStream source endpoint
-
Talend Data Catalog 8.0 End of Support: December 31, 2024
This notice is to remind you that Talend Data Catalog version 8.0, released in April 2022, reaches the end of support on December 31, 2024, as detaile... Show MoreThis notice is to remind you that Talend Data Catalog version 8.0, released in April 2022, reaches the end of support on December 31, 2024, as detailed in the Talend Product Documentation. After this date, Talend Data Catalog version 8.1 will be the only regularly supported version.
If you are currently using Talend Data Catalog version 8.0, we encourage you to transition to fully supported Talend Data Catalog 8.1 as soon as possible. Talend Data Catalog 8.1 includes many new features and improvements that enhance your productivity and efficiency, not to mention that upgrading to a supported version helps ensure that your software stays relevant, secure, and usable for years to come. Head to Talend Data Catalog 8.1 for a list of new features in Talend Data Catalog 8.1. You can continue operating Talend Data Catalog 8.0, but it will no longer be supported by Qlik under the Support Policy.
Every active Talend Data Catalog subscription is entitled to a current Talend Data Catalog version 8.1 license. If you do not already have a Talend Data Catalog 8.1 license, please contact Qlik Customer Support via the customer portal to request one. The 8.1 license key is 100% backward compatible with 8.0. and can be safely applied to your 8.0 installation.
Finally, for all other upgrade and troubleshooting information, contact Qlik Customer support.
Thank you for choosing Qlik,
Qlik Support -
Football Betting Dashboard
Football Betting Dashboard 2Foqus WHAT IF: you would bet €10 on your favorite sports team for every game?⚽ Would you end up with a profit by the... Show MoreFootball Betting Dashboard2Foqus WHAT IF: you would bet €10 on your favorite sports team for every game?⚽ Would you end up with a profit by the end of the season? Let's find out! What IF analysis in combination with Football Betting Data, visualized using the powerful Layout Container.
WHAT IF: you would bet €10 on your favorite sports team for every game?⚽ Would you end up with a profit by the end of the season? Let's find out! What IF analysis in combination with Football Betting Data, visualized using the powerful Layout Container.
Discoveries
Flexibility and countless visualization possibilities with Layout Container in combination with a WHAT IF analysis
Impact
New ways to design dashboards using new visualization objects in this application
Audience
Primarily for Qlik developers, but also for any end users interested in exploring new possibilities with the tool.
Data and advanced analytics
Showcasing the power of WHAT IF analysis within Qlik
-
Reflecting on 2024 and Preparing for an Exciting New Semester with Qlik’s Academ...
As 2024 draws to a close, we reflect on the past year—on the memories made and the hard work put in. Students and educators are wrapping up their fina... Show MoreAs 2024 draws to a close, we reflect on the past year—on the memories made and the hard work put in. Students and educators are wrapping up their final classes and exams, while the holiday season offers a well-deserved break to recharge.
Before we know it, January will arrive, bringing with it the start of a new semester. But don't worry—Qlik’s Academic Program is here to help you hit the ground running. With a robust data analytics curriculum, access to free software, and data literacy courses, you'll be fully equipped for an exciting and innovative semester ahead.
Let us support your students by educating them about who we are, what we offer, and how our program can enhance their classes. Be sure to ask about our workshop, designed to help students gain confidence using our free software.
Feel free to reach out to me directly at brittany.fournier@qlik.com, and visit our academic page at https://www.qlik.com/us/company/academic-program for more information.
-
Simplifying GenAI Data Pipelines with Qlik Talend Cloud
Generative Artificial Intelligence (GenAI) and related applications have exploded into the tech scene over the last couple of years. While the techno... Show MoreGenerative Artificial Intelligence (GenAI) and related applications have exploded into the tech scene over the last couple of years. While the technology shows great promise, building data pipelines that leverage customers structured and unstructured data is a challenging and high effort integration activity.
Qlik Talend Cloud (QTC) Knowledge Mart data capabilities enable customers to simplify and accelerate the work needed to have their data flowing to Large Language Model (LLM) Retrieval Augmented Generation (RAG) based GenAI applications. In this blog we’ll cover this exciting new capability to simplify using your data with GenAI applications.
Watch a DEMO of this capability HERE!
Background – GenAI, LLM, RAG, Vector stores
Before diving into how QTC Knowledge Mart data capabilities assist, leveraging automation, in having enterprise data be made available seamlessly to RAG based GenAI applications, lets outline the technologies involved and the complexities found when building GenAI applications from scratch.
RAG is a method of implementing GenAI applications that ground the LLM with the data context that the LLM must use when answering a query. It is used in conjunction with LLMs to both avoid the need to train an LLM on customer specific data and limit the scope of the data the LLM will use to answer questions posted to it. While LLM based chat interfaces, such as ChatGPT, are the most readily recognizable element of a GenAI application, there are several precursor technologies and processes that need to be selected and integrated, typically with complex code-based methods.
Anatomy of a RAG based solution
A typical RAG based GenAI solution contains the following components and process flow.
To service a query from the user the RAG Application or Chat bot on enterprise data, the enterprise data needs to be loaded into a vector store with appropriate LLM embeddings. An LLM embedding refers to a vector representation of text (such as a word, sentence, or document) generated by a LLM like GPT, BERT, or other advanced models. The purpose of embeddings is to capture the semantic meaning of the text in a way that allows the model to perform various tasks, such as similarity search, classification, or language generation, more efficiently. An embedding is a high-dimensional numerical vector that represents a piece of data (like words or sentences) in such a way that semantically similar pieces of data are closer together in the vector space. This allows models to process and compare pieces of text effectively.
This vector is then passed to the LLM along with the text of the user query for the LLM to then use as the context against which the embeddings generated from the user query text to generate the response back to the user.
RAG based solution technology components
For this process to work, several technology decisions and integrations need to be made in advance.
- The data source systems that currently house the enterprise data needed to answer questions. There would be typically multiple databases and applications whose data need to be integrated to achieve coherent answers. This includes unstructured text data in documents and knowledgebases.
- The platform on which all this data will be integrated. Very popular cloud-based data platforms, E.g. Snowflake and Databricks.
- The Vector database on which to store the enterprise data embeddings. Cloud platforms (Snowflake Cortex, Databricks Mosaic) typically provide their own Vector DB and point solutions such as ElasticSearch, Pinecone, OpenSearch, etc. are also popular choices.
- The LLM to use to generate the enterprise data embeddings and completions for chatting. There are ample choices for this as well both through hyperscaler AI platforms (Azure OpenAI, Amazon Bedrock), cloud data platforms (Snowflake Cortex, Databricks Mosaic) and independent providers (OpenAI, Anthropic)
All of this together paints the following picture of the required integration.
An implementation of this solution requires large amounts of effort scripting/coding and specialized knowledge. As we’ll see next, Qlik Talend Cloud automates most of the integration and only requires configuration and selections of the technology to be utilized.
Qlik Talend Cloud – Knowledge Marts
Qlik Talend Cloud (QTC) is purpose built to simplify and accelerate the implementation of RAG based GenAI data integration pipelines by using a no code approach. Let’s cover each of the features and how they leverage automation to enable this capability in detail.
Data source connectivity
QTC offers no-code connectivity to hundreds of data sources, including enterprise systems, mainframes, SAP, databases, and SaaS applications. It offers efficient, zero footprint, and minimal impact near real-time log based Changed Data Capture (CDC) or incremental API to only send data and changes once, without the need to reload the same data over and over, from source to target. The intuitive interface allows for an easy implementation of this connectivity and movement process, as shown below.
More information available on the following link on qlik.com
Data preparation/transformation
Once the data is in the target cloud platform the next step is to prepare it for vectorization. This entails creating derived data sets with the appropriate field and record joining and filtering that feed the relevant bits of data for the LLM to use. QTC offers multi-modal transformation design experience ranging from no code Transformation Flows to pro-code GenAI assisted query crafting. Learn more about these feature on Qlik Community blog and online guide
Data modeling
Once the necessary data sets have been generated, we then define relationship metadata between data sets. This allows for the subsequent Knowledge Mart step to recognize the potential building blocks for the document to prepare and store in the Vector DB.
Knowledge Marts and Vector DB/LLM integration
The data to be vectorized needs to go through a process of parsing, chunking, embedding, and indexing. Structured data (from tables and columns) needs to be converted to document format prior to these steps. QTC shines in this area with an intuitive interface for determining the elements to include in the document. To get an idea with an example of the level of effort that QTC Knowledge Mart Tasks automate, for just one point solution LLM and Vector store integration, please refer to the following article.
- From a transformation step, we select the option to create Knowledge Mart
- The specify where to store the vectors
We can store vectors in either:
- External vector database
- Data project platform. This is dependent on the platform for the project this task is a part of. Either Snowflake Cortex or Databricks Mosaic.
- Qlik Answers knowledge base. For information on this option check out this blog
3. Specify the LLM connection. This connection and specified models will be used for both creating the embeddings for storing the document data in the Vector DB and also to power the completions of the chat interface available to the implementer to test the LLM. The options here depend on the prior choice of Vector DB.
- Using external LLM
- Using data project platform LLM. Refer to the following for more information on Databricks Mosaic or Snowflake Cortex
- In either case, a valid embeddings and completion model need to be specified
- Create Knowledge Mart documents. In this step we leverage the datasets and relationships defined in the transformation task to create the documents to be vectorized. We start with a parent data set, on the far right of the model diagram, and select the child elements to become part of the document
- We’re done! The next step is to prepare and run the task and test the data and LLM with the test assistant function.
Note: This interface is intended for the Knowledge Mart data implementer to test the integration of the data and processing components (LLM, Vector DB, etc.). It’s not intended to be and end user chat interface.
The completed pipeline would look like the following
Conclusion – Accelerating your GenAI journey
GenAI offers new and exciting capabilities to interact with data. Building the workflow that combines all the data sources, processing, and technologies typically entails a large effort. QTC accelerates enterprise GenAI implementations and allows for a faster time to value at a lower effort and cost than otherwise.
Whether using automatic ingestion of data from structured or unstructured sources, transformation into required data sets, the creation of a vector record with appropriate LLM embeddings, or the testing of chat answers, QTC lowers the barrier of entry and adoption to deliver RAG based GenAI solutions on your data. Reach out to your account team today to take advantage of this groundbreaking functionality.
Watch a DEMO of this capability HERE!
NOTE: Initial GA release (July 8th 2025) supports Snowflake/Cortex, OpenAI, Azure OpenAI, Amazon Bedrock, Elasticsearch, OpenSearch, and Pinecone. Support for other platforms mentioned will come in subsequent releases.
-
Updates to Qlik Cloud Security Roles
On April 16th, 2024, Qlik is launching a highly anticipated capability: custom security roles. What do custom security roles do? Custom security roles... Show MoreOn April 16th, 2024, Qlik is launching a highly anticipated capability: custom security roles.
What do custom security roles do?
Custom security roles introduce fine control of data export and access permissions within Qlik apps. This allows you to tailor permissions to your specific needs, enhancing data security and compliance.
The first delivery on April 16th includes the capability to control who can export content. Additional capabilities will be added soon after, such as who can create data connections, reports, and similar.
What does this mean for me?
As part of this update, the existing "has restricted view" space role will gain the ability to export data to Excel. This adjustment is in line with Qlik's capacity-based pricing model, ensuring basic users have essential tools.
If you do not wish for users with the "has restricted view" space role to be able to export data, you will need to edit the User Default role to deny download for all users, and then create a custom role that allows if for specific users and groups.
Stay tuned for more information and resources leading up to the April 16th launch. We are excited about these enhancements and the value they will bring to your data management and security efforts within Qlik.
Thank you for choosing Qlik,
Qlik Support -
Qlik Cloud 11 月の新機能
分析の新機能 ナビゲーションメニュー アセットパネルからシート間の移動をせずとも、シート内にナビゲーションメニューを追加して、直接移動を行う事が出来ます。シート内でのスタイルは、ドロワーメニューや、シート名を羅列した形式に表示することが可能です。 ナビゲーション メニュー UI 設定 アプリの... Show More分析の新機能
ナビゲーションメニュー
アセットパネルからシート間の移動をせずとも、シート内にナビゲーションメニューを追加して、直接移動を行う事が出来ます。シート内でのスタイルは、ドロワーメニューや、シート名を羅列した形式に表示することが可能です。
UI 設定
アプリの設定に UI 設定が追加されました。ナビゲーションバー、ツールバー、シートヘッダーのカスタマイズを行うことができます。 アプリ全体に適用されます。
新しいアセット パネルのプレビュー
新しいアセットパネルのプレビュー モードが開始されました。編集モードのアセットパネルのプレビューアイコンをクリックして表示することができます。新しいアセット パネルは、1 月にすべてのユーザーに提供される予定です。
分析タイプによる構築
チャートの種類からビジュアライゼーションを作成する代わりに、構築する分析タイプから開始することもできます。分析では、項目と選択した分析タイプに基づいてチャートが構築されます。生成されたチャートをカスタマイズすることもできます。分析は、データに対して実行する分析の種類がわかっているものの、それをビジュアライゼーションで構築する方法がわからない場合に役立ちます。
下記の分析タイプのチャートを作成することができます。
タブ付きコンテナ
古いコンテナ オブジェクトからタブ付きコンテナへと改良されました。編集画面の詳細モードでのみ使用可能です。タブ付きコンテナ内では、チャートやマスタービジュアライゼーションをタブ毎に設定し、それぞれをコンテナ内で表示することができます。表示条件により、タブの表示・非表示を切り替えることができます。タブを非表示にしてユーザーに表示を選択させず条件に応じて切り替えることもできます。
GetUserAttr 関数
ユーザーのメールアドレス、サブジェクト、ユーザーが属するIDプロバイダのグループを返す GetUserAttr 関数 が追加されました。チャートでもスクリプトでも使用することができます。
構文: GetUserAttr(‘属性名’)
- スクリプトの例 Let vUserEmail = GetUserAttr('userEmail’)
- チャートの数式の例 =GetUserAttr('userEmail’)
ユーザーの属性情報に基づいて、ロケールや言語を適用する、軸やメジャーやシートの表示・非表示をコントロールするなど、高度なアプリケーションの制御に使用することができます。
テーブルの改善
新しいストレートとピボット テーブルで、見出し項目の列にドロップダウンが追加され、サイクリック グループの軸を素早く切り替えられるようになりました。
ピボットテーブルでは行のインデント表示ができるようになりました。インデント状態では画像やリンクは表示できません。
PixelPerfect テンプレートの利用
レポートの作成におけるテンプレートとして新たに PixelPerfect テンプレート (.qpxp) が追加されました。テンプレートは、アプリ内の PixelPerfectデザイナーを使用して開発され、ピクセル固有のレポートを行う事が可能となりました。
AutoML のアップデート
データドリフト監視
時間の経過とともに、特徴量のデータの分布や大きさの変化にモデルが対応しきれずに精度が劣化してしまうデータドリフトが起こる可能性があります。データ ドリフトは集団安定性指数 (PSI) として計算されます。PSI 値を確認することで、特徴の重大なデータ ドリフトを特定できます。PSI 値が 0.25 以上の場合は、モデルの再トレーニングまたは新しい実験の作成を検討してください。
Monitoring data drift in deployed models
運用監視
- デプロイメントのリクエスト、予測、予測失敗の数を表示します。
- 予測イベントをトリガー別に分析します (たとえば、最初に手動で実行されたイベントの数とスケジュールに従って実行されたイベントの数など)。
- 各予測イベントと重要な詳細を示す詳細なログを表示します。
Monitoring deployed model operations
異常の検出と処理
インテリジェントなモデル最適化により各特徴を評価し、トレーニングに影響を与える可能性のある異常を特定します。これらの値は、学習済みモデルの性能に対する異常値の影響を軽減するために重み付けされます。
その他
- マスタアイテムに登録した軸が選択ツールに表示されるようになりました。
- 変数ダイアログの値が、変数入力コントロールなど、アプリ内での変更に応じて変化するようになりました。
データ統合の新機能
Talend Data Integration GitHub 構成のサポート
Talend Data Integration で Github との接続をサポートしました。これによりクラウドにあるリソースを GitHub 上でバージョン管理 / コード管理し、共同開発や、ブランチ、スペース、テナント間での資材を共有することができるようになりました。Github によるバージョン管理は、 Qlik Talend Cloud Standard エディション以上で利用できます。
GitHub Organization のリポジトリへ接続を行い、 Data Ingtegration の各プロジェクトの変更に対して commit/push 、リモート先の変更を pull、ブランチの切り替えや、プロジェクトからブランチの作成をサポートします。プッシュしたリソースはオブジェクト毎に Json ファイル形式で管理されます。
スキーマの自動進化のサポート拡張
Talend Data Integration におけるスキーマ進化が以下においてもサポートされるようになりました。
- レプリケーションプロジェクト - データ レイクランディング タスク (レプリケーションタスクは以前からサポート)
- パイプラインプロジェクト - ランディングタスク / ストレージ タスク
QVD ファイルのデータ品質計算をサポート
Qlik Talend Data Integration における、これまでサポートされていたデータセットタイプに加え、QVDをはじめとしたデータ品質を計算できるようになりました。
- 登録されたデータセットのプルアップ計算を可能にする、SQL データベース
- QVD、CSV、XLS、XLSX ファイルなどのファイルベースのソース
- プッシュダウン計算による Snowflake データセットの継続的なサポート

-
【オンデマンド配信】アフター AI :混乱の渦中でデータ・インサイト・アクションを変革
AI は現実に。その先は? 2024年が生成 AI の急速な普及が落ち着いた年だったとすれば、2025年は多くの企業がアフター AI の世界で自社の方向性を模索する年になると予測されます。AI は、社会とビジネスに根本的な変革をもたらしています。その一方で、これまで以上に不明確性が増し、AI の進... Show MoreAI は現実に。その先は?
2024年が生成 AI の急速な普及が落ち着いた年だったとすれば、2025年は多くの企業がアフター AI の世界で自社の方向性を模索する年になると予測されます。AI は、社会とビジネスに根本的な変革をもたらしています。その一方で、これまで以上に不明確性が増し、AI の進化だけでなく、企業の成長にとっても脅威となっています。
「アフター AI :混乱の渦中でデータ・インサイト・アクションを変革」では、データの世界の AI に関する 3 つのトピックと関連するトレンドを深掘りします。混乱の渦中でも AI を活用して優れた成果を創出し、ビジネス価値を最大化するためのトレンドを考察します。
※ 参加費無料。パソコン・タブレット・スマートフォンで、どこからでもご視聴いただけます。日本語字幕付きでお届けします。
今すぐ視聴する
「企業は、AI 活用の岐路に立っています。持続可能で経済的かつ安全な方法で AI を活用し、価値を引き出す必要があります。」 - Qlik トレンド Web セミナー講演者:Qlik マーケットインテリジェンスリード Dan Sommer -
Navigating Qlik Cloud's newest user experience. Better findability, smoother nav...
Today, users will navigate a smoother journey across our entire Qlik Cloud platform, unifying both Qlik Cloud Analytics and Qlik Talend Cloud. We have... Show MoreToday, users will navigate a smoother journey across our entire Qlik Cloud platform, unifying both Qlik Cloud Analytics and Qlik Talend Cloud. We have balanced aesthetics with functionality to create an experience that is both visually appealing and highly usable. Let's take a look…
The waffle menu is your navigation anchor
Meet the new top-left "waffle" menu, your consistent navigation anchor throughout Qlik Cloud. This feature enhances findability by offering easy access to your "recent" assets, ensuring you always know where you are and where you can go next. Whether you're diving into automations or exploring AutoML, the waffle menu is always within reach.
An Activity Center tailored for your tasks
Our new Activity Centers are now more activity and goal-driven, providing creators with upgraded tools and a comprehensive capabilities page. This streamlined space is designed to help you understand and optimize your efficiency without the clutter of unnecessary buttons.
***Please note that these Activity Center navigation updates can be toggled on or off for two months, until the beginning of September, giving your organization the necessary time to become familiar with and aware of the new design.
📹 See how to toggle on and off hereCustomizable sheet navigation
Navigating through numerous sheets in an app can be daunting. Our improved sheet navigation allows you to organize sheets into groups, making it easier to manage and publish them. You can now create, rename, delete, and publish groups and individual sheets, addressing one of our most requested features.
Insight Advisor chat now helps without disruption
We've redesigned the Insight Advisor chat to improve usability, allowing you to get help without leaving your current context. This update makes it easier to author analyses and boosts awareness and usage of chat and search features as we roll out even more NLP capabilities.
Improved search functionality
Finding content has never been easier with our significantly upgraded search functionality. This enhancement streamlines the process of navigating and locating the assets you need, saving you time and effort.
Expanded Catalog and public collections
Our Catalog now supports a wider range of asset types, catering to both analytics and insight-seeking users. You can add these assets to public collections or a custom tenant-wide home page in the Insights Activity Center, with options like public monitored charts (coming soon) and links to sheets.
New panel design and sheet grouping
The side panel design consolidates sheets, bookmarks, and more into one place, offering various size options and better content organization. Additionally, the new sheet grouping feature simplifies navigation for apps with many sheets and allows for bulk publishing, enhancing both private and public sheet management.
The redesigned Data Integration ‘Home’
***Coming soon
Soon, we'll début a new Data Integration 'Home'. We've taken the best of both worlds, combining the previous 'Getting Started' and 'Home' pages into a single, cohesive destination. It's like having your favorite coffee shop and office rolled into one - everything you need, right where you want it. As you grow from novice to expert, you can customize your view, hiding the 'Getting Started' section when you're ready. But don't worry, this page will always remain your launchpad for all things Data Integration.
With quick access to your recent work and important notifications front and center, this is one 'Home' improvement you won't want to miss!
To learn more about these updates check out the links below:
- Qlik Cloud's New Look | Support Blog
- ‘What’s New in Qlik Cloud’ | Help Page
Videos: -
DC Messenger
DC Messenger Differentia Consulting DC Messenger was built to simplify access to Qlik data by integrating it with WhatsApp, making data-drive... Show MoreDC MessengerDifferentia ConsultingDC Messenger was built to simplify access to Qlik data by integrating it with WhatsApp, making data-driven insights accessible from anywhere. It allows users to ask questions about their Qlik estate, receiving tailored visualizations, answers from Qlik Answers assistants, key statistics, and performing actions like app reloads directly within the messaging app.Differentia Consulting designed DC Messenger for business users and analysts, the app bridges the gap between technical tools and everyday accessibility. DC Messenger has streamlined decision-making by providing quick, actionable insights, enhancing productivity and responsiveness.
Discoveries
Some of the discoveries from using this app include:
• Improved accessibility to Qlik insights
• Simplified interaction with data through WhatsApp over traditional BI tools
• Real-time app reloads via messaging enable teams to react quickly to changes in data, boosting operational efficiency
Impact
DC Messenger has made it easier for our team to access Qlik data and perform actions without needing to log into the platform. This has saved time and allowed users to quickly get the answers or updates they need, even when they're away from their desks.
Audience
Can send messages to up to 100,000 unique numbers in a 24-hour period.
Data and advanced analytics
• Various structured datasets contained in the Qlik estate
• Roughly 100 files of unstructured data accessible via Qlik Answers
• Five different LLMs are accessible for users to query and use for analysis
-
Techspert Talks - Qlik Cloud App Navigation Showcase
Hi everyone, Want to stay a step ahead of important Qlik support issues? Then sign up for our monthly webinar series where you can get first-hand insi... Show MoreHi everyone,
Want to stay a step ahead of important Qlik support issues? Then sign up for our monthly webinar series where you can get first-hand insights from Qlik experts.
The Techspert Talks session from December was a Qlik Cloud App Navigation Showcase.
But wait, what is it exactly?
Techspert Talks is a free webinar held on a monthly basis, where you can hear directly from Qlik Techsperts on topics that are relevant to Customers and Partners today.In this session, we will cover:
- Exploring Cloud Analytics Navigation
- New developments for better flow
- Tricks for moving around quicker
Click on this link to watch the recording.

-
【新着レポート】Qlik、データ統合ツールで 9 年連続リーダーの 1 社に!
Gartner 社は、「2024年 Gartner® データ統合ツールの Magic Quadrant」を発表しました。Gartner 社が評価した 20 社のデータ統合メーカーの中で、Qlik は 9 年連続でリーダーの 1 社に評価されました。 分析や AI にビジネスに適した信頼できるデ... Show MoreGartner 社は、「2024年 Gartner® データ統合ツールの Magic Quadrant」を発表しました。Gartner 社が評価した 20 社のデータ統合メーカーの中で、Qlik は 9 年連続でリーダーの 1 社に評価されました。
分析や AI にビジネスに適した信頼できるデータを提供するには、適切なデータ統合ソリューションの選択が不可欠です。自社のビジネスニーズに最適なソリューションを選択するには?ぜひ、本レポートをご参考ください。
-
データ統合市場における Gartner 社 のインサイト
-
Qlik がリーダーの 1 社に評価された理由
-
データ統合市場における各メーカーの評価
-
-
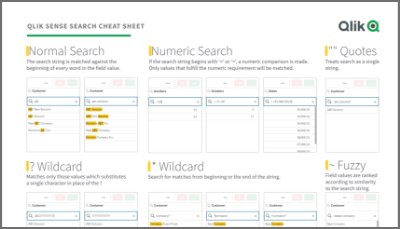
Qlik Sense Cheat Sheet version 2.0
It was back in 2015 when I first published the original Qlik Sense Search Cheat Sheet. Since then, and thanks to lots of individual contributors here ... Show MoreIt was back in 2015 when I first published the original Qlik Sense Search Cheat Sheet. Since then, and thanks to lots of individual contributors here in the Community, the Search Cheat Sheet has suffered several transformations to make it more complete and truthful.
@afurtado wrote me an email a few weeks ago because he was interested in getting the document localized for the Brazilian folks out there. In addition to thank him for his contribution and sending him the file I decided that it was about the time to get the Search Cheat Sheet an update.
Today I want to introduce a new version of the document. I added the compound search section to it (@jayanttibhe thanks for the tip), and I redesigned and rationalized the position of each element for better comprehension.
As an extra, I made the document multilanguage ready. So, if someone wants to translate the Cheat Sheet to other language (currently available in English, Spanish and Portuguese) please let me know in the comments section and I'll gladly tell you how to help us.
Hope you like it, and please share it.
Arturo
Updates:
Feb 28: French version thanks to @arychener
Feb 25: Italian added thanks to @AntonioCostantino . Russian translation updated
Feb 13, 2020: Cheat sheet includes now the ^ Wildcard to be consistent with Qlik Help. Russian language added thanks to the contribution of @martynova
Jan 29, 2020: German language added thanks to the contribution of @g_mitschke

-
New DevOps Features to Future-proof your Data Pipelines
Introduction: In the era of artificial intelligence (AI), the need for accurate, high-quality, real-time data has never been greater. Qlik Talend Clo... Show MoreIntroduction:
In the era of artificial intelligence (AI), the need for accurate, high-quality, real-time data has never been greater. Qlik Talend Cloud, our market-leading data integration and quality solutions offering, utilize AI-enriched, no-code pipelines to rapidly deliver real-time trusted data throughout your organization — driving AI innovation, intelligent decisions, and business modernization.
Just a few months ago, we announced the general availability of Qlik Talend Cloud and we are making it increasingly easier for developers and data engineers to build, manage and fine tune their high-performance data pipelines to support their enterprise needs and use cases.
New DevOps Capabilities
Today, we are excited to announce several new Dev-Ops capabilities and innovations that would make it even simpler and easier for our customers to adopt and manage Qlik Talend Cloud for ingesting, transforming, modeling, collaborating and working with data for analytics and AI needs.
Some of the key new capabilities that are being launched include:
- Automated Schema Evolution
- Version Control with GitHub
- New Import/ Export APIs
Let’s dive into each of them a little bit more.
1. Automated Schema Evolution
In modern data ecosystems, data sources and business requirements are often dynamic, so being able to evolve schemas—i.e., the structure of data—without interrupting the flow of data is critical for smooth operations.
Schema evolution allows users to easily detect structural changes (aka schema drift) to multiple data sources and then control how those changes will be applied to your project. At Qlik, we previously supported schema evolution and schema drift for Replication pipelines with a manual process for multi-step data pipelines where data engineers had to manually monitor and make relevant changes to the pipelines.
Today, we are thrilled to launch Automated Schema Evolution, featuring the ability to detect and automate all of the DDL changes that were made to the source database schema and dramatically simplify the efforts required to modify the pipelines.
Any changes in the data structure at the source database will automatically be picked up and applied to the target structure - including the Type 2 history, a comprehensive live view of the architecture - and the changes applied to the pipelines without any manual interventions.
What this enables is a much more automated and well-oiled data operations, with fewer errors and things breaking downstream, and a storage (bronze) layer that is always up to date - even when new values or columns are added to the source.
So, if a new column is added to the source database, it is automatically detected and captured with Type 2 history and the appropriate changes are reflected in the tables in the landing and storage zones, without the need for any data reloads. Also, for any changes beyond the bronze layer, users get notifications/alerts to schema changes in the bronze layer so they can react quickly to make changes to downstream pipelines.
Here is a quick demo on the new Automated Schema Evolution functionality:
With Automated Schema Evolution, users can set distinct rules and have access to a series of more fine-grained controls for schema evolution. These include the specific actions that need to be taken for various DDL events – such as automatically adding a column to the target, or suspending a table on rename etc. These configurations allow users to prevent downstream impact and control behavior in the target data platform.
See example below.
Automatic schema evolution is now generally available, and you can learn more about the feature in the Qlik help/documentation page here.
2. Version Control with GitHub
Version Control empowers developers to work concurrently on different aspects of a project—such as adding new features or fixing bugs—without disrupting the main version of the project. This approach supports incremental, collaborative, and secure development, allowing teams to release updates progressively while maintaining stability.
Today we are excited to launch Version Control for Qlik Talend Cloud Pipelines through efficient and secure GitHub integration and branching support.
Every Qlik Talend Cloud user in the organization can utilize their GitHub account with a personal access token to connect their projects to any authorized GitHub repository.
More importantly, with the new ‘branching’ feature, it enables multiple developers to:
- Create branches to isolate a feature or edit a project without affecting the ‘Main’
- Customize the schema prefix to be added to all branch datasets to avoid conflicts
- Switch between branches, share branches, or apply changes from GitHub to the working branch or ’Main’
- Delete branches, if need be, when the specific activity is completed
This parallel development model allows team members to sync their changes efficiently and collaborate without conflicts and putting each other’s work at risk.
Users can even open an existing project located on a GitHub repository. This allows sharing projects across spaces and tenants.
Here is a quick demo on the new Version Control functionality:
Using GitHub, developers can submit pull requests, where other team members can review and approve the code before it’s merged back into the main project. This review process ensures collaborative quality control and reduces the risk of introducing errors while enabling developers to safely commit and push the changes to the central repository.
Version control, branching and schema prefixes further enhances security as well, minimizing the risk of data loss or corruption, while fostering collaborative engagement.
The Version Control feature is now generally available now in Qlik Talend Cloud Standard edition (and upwards). For more details on the Version Control feature, and how to get started, please visit the documentation page here.
3. New Import / Export REST APIs
Along with the other DevOps innovations, we are delighted to announce the launch of a new set of REST API endpoints for importing and exporting Pipelines or projects in QTC. This will in turn enable users to start building and managing their data pipelines using a Continuous Integration/ Continuous Deployment (CI/CD) approach.
These new APIs programmatically reproduce the capabilities available within the user interface; and allow programmers to manage projects across tenants and spaces for deployment purposes in an easy-to-use fashion.
In just a few API calls, users can now read project variables (referred to as bindings), export and re-import projects.
The export API creates a ZIP file containing all necessary project contents for re-import. Besides all project-related resources (including tasks, datasets etc…), the export API also generates a separate “bindings” file whose purpose is to list all project parameters and variables for users to customize on re-import.
To import a project, users have the choice of either creating a new project (using the dedicated API) or importing within an existing project. In the latter case, users only need to read/update the bindings and import the project contents to overwrite the existing one.
The list of Import/ Export APIs endpoints that we are launching include:
API
Description
Command
Export API Definition
Exports the project content as a ZIP file.
GET /v1/di-projects/{projectId}/actions/export
Get Project Binding
Retrieves the bindings for the specified project.
GET /v1/di-projects/{projectId}/bindings
Create a New Project
Creates a new data integration project with the specified parameters.
POST /v1/di-projects
Update Project Binding
Updates the bindings for the import of the specified project.
PUT /v1/di-projects/{projectId}/bindings
Import Project Content
Imports project content into an existing project from a ZIP file.
POST /v1/di-projects/{projectId}/actions/import
Please find below a quick demo of the new Import/ Export APIs:
This feature is available now generally available, and you can find more details on the Export/ Import APIs, visit the documentation page here.
Summary
These new DevOps features in Qlik Talend Cloud represent a significant step forward in simplifying and optimizing data pipeline management. By automating key processes like schema evolution, integrating robust version control capabilities, and enabling seamless CI/CD workflows through new APIs, we're empowering data teams to work faster, smarter, and with greater confidence.
As businesses continue to rely on real-time, trusted data for AI-driven decision-making, these innovations ensure that your data pipelines are not only resilient and scalable but also future-proof. Whether you're managing complex data environments or developing cutting-edge analytics solutions, these enhancements make it easier to adapt, collaborate, and stay ahead of the curve. We’re excited to see how these new features will help you unlock even greater value from your data, driving innovation and business transformation.
Authors: Vijay Raja, Vincent Menard
Here are some useful resources to learn more:- Learn more about Qlik Talend Cloud
- Check out the Guided Tours
-
Making it easier to share and find insights
We know that finding what you need to make a decision can be hard, that being data, an app, a sheet, or a specific visualization. We have, therefore... Show MoreWe know that finding what you need to make a decision can be hard, that being data, an app, a sheet, or a specific visualization.
We have, therefore, set out to create a suite of features that help analytic creators to curate content for their consumers.
These features helps the users to more efficiently find what they need to gain an insight, to take that decision, or to dig even deeper if needed.
The demo includes an example of how to build a bespoke landing experience for your consumers using:
The suite of features: includes:
- Public monitored charts
- Links to sheets
- Link to external content
- Public collection
- Custom tenant home pageThey are all designed to help you craft a personalized landing experience in Qlik. These features make it effortless for your analytic consumers to find insights, streamline their decision-making process, and act faster with confidence.
If you want to see a 10 minute demo please head over to LinkedIn
-
Introducing explore.qlik.com
We’re excited to announce the launch of our enhanced Demo Site - explore.qlik.com, designed to showcase the full potential of Qlik’s product portfoli... Show MoreWe’re excited to announce the launch of our enhanced Demo Site - explore.qlik.com, designed to showcase the full potential of Qlik’s product portfolio in an interactive and engaging way!
Powered by Qlik’s newly released Anonymous Access, explore.qlik.com will allow visitors the ability to experience our solutions firsthand.
Explore.qlik.com is designed to assist visitors to easily find the content that is most relevant to them. Through live demos, guided experiences, and videos, visitors can “feel” all Qlik’s products. It's the perfect experience to showcase the value that Qlik offers.
Key Highlights:
- Powered by Qlik Anonymous Access: Scalable to meet the site’s traffic demands.
- Interactive Experience: Feel the power of the Qlik product portfolio.
- User-Friendly Design: A seamless, easy-to-navigate layout designed for all types of users.
What You Can Do Now:
- Explore: Jump in and explore all the content on explore.qlik.com.
- Share: Share content links.
What’s Next:
- Downloads: Log in and download content.
- Additional Filters: Continue to enhance the user experience by adding additional filters, empowering visitors to quickly discover the content that’s most relevant to their interests and needs.
We believe this new resource will be a game-changer in how we engage with our audience. It’s live, it’s exciting, and it’s ready to impress!
Check out explore.qlik.com now and start exploring.

-
Upcoming change to variables in bookmarks and subscriptions in Qlik Cloud Analyt...
With a Qlik Cloud Analytics update on the 10th of December 2024, Qlik introduces a new feature which changes how variables are used in bookmarks. Deve... Show MoreWith a Qlik Cloud Analytics update on the 10th of December 2024, Qlik introduces a new feature which changes how variables are used in bookmarks.
Developers now have a setting available for each variable to decide whether or not the variable should be included in bookmarks.
The default is set to No, meaning variables are not included.
Previously, a user had to check ”Save all variable states” on bookmark creation to include variables. This way of working is not recommended, since it is the app developer who knows which variables need to be saved.
For more information about the change and to join the active discussion, continue to App Development: Upcoming change to variables in bookmarks and subscriptions in Qlik Cloud Analytics.
Thank you for choosing Qlik,
Qlik Support -
Using the Qlik Talend Cloud to Find Answers
With Qlik Talend Cloud, Data Integration pipelines can be created to curate data for AI Retrieval Augmented Generation (RAG) solutions. You can reduce... Show MoreWith Qlik Talend Cloud, Data Integration pipelines can be created to curate data for AI Retrieval Augmented Generation (RAG) solutions. You can reduce time to value for gaining insight into your enterprise data using Generative AI by leveraging Qlik Answers. QTC will automate loading structured and unstructured data sources to create knowledge base assistants that users can prompt for questions and retrieve answers. QTC will simplify the complexity of transforming data by chunking data for vector embedding and building the context for prompts, within an easily deployable conversational agent.
Introducing Qlik Answers
Qlik Answers is a plug-and-play, generative AI-powered knowledge assistant that provides users with the ability to gain answers to questions from the user’s sourced content. Generative AI is used to personalize answers to prompted questions of the indexed data sets within the user created knowledge base. Qlik Answers is available in the Qlik Talend Cloud and can be used with Data Integration pipelines to provide an end-to-end solution for your RAG use cases.
Qlik Talend Cloud brings it all together
The capabilities of QTC allow you to use automation to create a data pipeline that can ingest data from any supported source into a target for integration with Qlik Answers.
Using QTC we can show an example of loading structured data to a Databricks target and leverage the data for Qlik Answers (Hawaii resorts structured location data set used for source data.)
Setting up and running Qlik Talend Cloud Services
Create a Databricks target data pipeline to onboard the Hawaii resorts source data into a Databricks Delta table.
Create an AI-ready transformation off the Storage task within the QTC data pipeline to ingest data for Qlik Answers knowledge base utilizing an AWS S3 object store.
Add the Hawaii location reserve dataset to the transformation for preparation and loading.
The complete data pipeline is shown below.
The reserve data will be loaded in the AWS S3 location after the data pipeline is completed.
Upload the unstructured data set to the same AWS S3 bucket location. (Hawaii location Brochure unstructured pdf file.)
Within QTC choose Analytics tile and create a Knowledge Base with the files in the AWS S3 location.
Index the source files and create the Qlik Assistant
Use the assistant to ask questions on the indexed data sets. The following screenshots demonstrate the value of having that data in Qlik Answers (or other Retrieval Augmented Generation (RAG) solutions) by showing end users using the assistant to answer questions using that data. Of course, QTC Pipelines will keep that data up to date, so the answers will remain as valuable in the future as they are today.
Example 1 Chat with the chat bot.
Showing the unstructured source data used in the chat bot.
Example 2 Chat with the chat bot.
Showing the structured source data used in the chat bot.
Conclusion
With Qlik Talend Cloud, data pipelines can be used to create a no-code Retrieval-Augmented Generation (RAG) solution for data within your organization. QTC data pipelines will automatically ingest data that is structured into a target location that can be combined with unstructured data for use within Qlik Answers. Qlik Answers will simplify leveraging GenAI with the creation of a chatbot which can be used to directly prompt curated data sets for answers.
AI-Ready tasks are currently in private-preview in Qlik Talend Cloud. For more information or to take part in the private preview contact your Qlik account representative.