Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Archive
- :
- Archived Groups
- :
- QlikView Application Architecture for Large Enterp...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
QlikView Application Architecture for Large Enterprise Applications
In large Enterprises where the reporting is based on huge and distributed dataset the architecture of the QlikView application is of prime importance to avoid overloading a QlikView document with huge amount of data and to enhance reusability of the data, data model and expression. In QlikView world three-layer architecture is widely used with which the reusability of the model and script is limited. In this article four layer QlikView application architecture is explained which will further optimize the application with increased reusability aspect so that QlikView application development time also can be reduced.
General Application Architecture
In QlikView world the general approach is three-layer architecture which is widely used. In three-layer architecture we have:
- Extract Layer: This layer directly interfaces with source which can be Database, flat file, data file etc. and retrieves data from the source and stores in QVD file
- Transform Layer: The QVD generated out of the Extract Layer is the source for transformation layer. This is the layer where different data transformation logics are implemented and again the data is stored in a QVD
- Application Layer: This layer fetches data from the transformation layer QVD and the Dashboards and reports are designed based on Transform Layer QVD
So the flow goes like as below: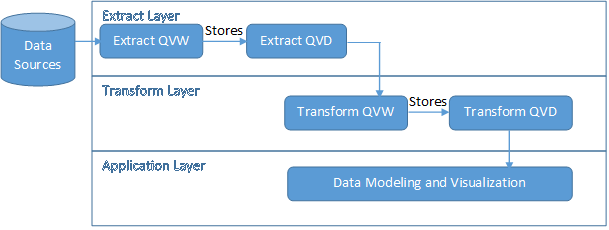 As you can see above that Data Modeling and Visualization is done at the application layer. The above architecture has below two concerns:
As you can see above that Data Modeling and Visualization is done at the application layer. The above architecture has below two concerns:
- Reusability of the data model is not possible if same model is required for another QlikView application
- There will be impact on the Application Optimization because complex script may have been involved to design the required model
The above two concerns can further be addressed using the below four-layer architectureFour Layer Architecture Described:In four-layer architecture just like three-layer architecture we have Extract and Transform Layer but in-between Transform Layer and Application Layer we introduce a Data Model Layer i.e. we are segregating the Data Model from the Application Layer so that this data model can be Binary Loaded in multiple QlikView applications. So the architecture would look something as below: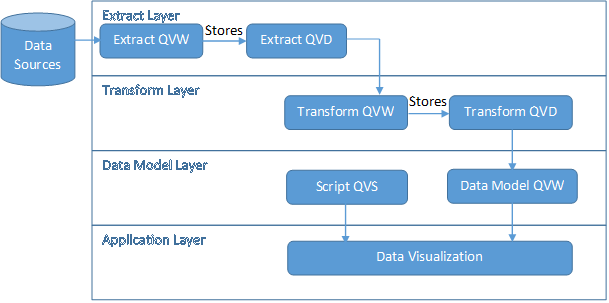 As shown above “Data Model Layer” has been introduced with two components Data Model QVW and the script file.In Data Model QVW we have to implement the model required for the Dashboard’s of related Subject area this Data Model then can be Binary Loaded in the Dashboard QVW. This separation of Data Model from Data Visualization will facilitate three advantages:
As shown above “Data Model Layer” has been introduced with two components Data Model QVW and the script file.In Data Model QVW we have to implement the model required for the Dashboard’s of related Subject area this Data Model then can be Binary Loaded in the Dashboard QVW. This separation of Data Model from Data Visualization will facilitate three advantages:
- Parallel work on the Data Model and Data Visualization can continue
- Due to Binary Load the Dashboard QVW load performance will be enhanced
- The Data Model can be reused across multiple related Dashboard’s
In Script file we should implement the expression components and this script file can be included in the Dashboard QVW and the expressions can be used in or as chart expressions. This again facilitates below benefits:
- Parallel work on expressions and Data Visualization can happen
- Expression Modularization is enabled
- Expressions can be reused across multiple Dashboards
So with this we conclude that four-layered architecture has many advantages in real world scenarios dealing with huge data sets spanning across multiple dashboards.
Tips and Tricks to Optimize Your QlikView Applications
- Drop the table as soon as its usage is consumed. Ex.
PRODUCT:LOADproductID,productName,soldDatefrom FileName.xslx(biff, embedded labels, table is product$);MAXDATE:LOADMax(soldDate) as MaxSoldDateResident PRODUCT;Drop table PRODUCT;LET vMaxSoldDate=peek (‘MaxSoldDate’,0, ‘MAXDATE’);
- Use SET instead of LET in script file to define the expressions in form of variables and use $ in the variable usage in charts so that all expressions are not evaluated at the time on include rather are evaluated at the time of its usage. This will reduce the CPU usage. Ex.
Use:SET vSetRolling12 = '{$<MonthID = {">=' & Chr (36) & '(=Max(MonthID) - 11) <=' & Chr (36) & '(=Max(MonthID))"},' & Chr (10) & 'Date =,' & Chr (10) & 'Year =,' & Chr (10) & 'Quarter =,' & Chr (10) & 'Period =,' & Chr (10) & '[Period (#)] =,' & Chr (10) & 'Month = >}';Don’t Use:LET vSetRolling12 = '{$<MonthID = {">=' & Chr (36) & '(=Max(MonthID) - 11) <=' & Chr (36) & '(=Max(MonthID))"},' & Chr (10) & 'Date =,' & Chr (10) & 'Year =,' & Chr (10) & 'Quarter =,' & Chr (10) & 'Period =,' & Chr (10) & '[Period (#)] =,' & Chr (10) & 'Month = >}';
- When data sources are different and are distributed then create multiple QVW’s in Extract layer so that they can be scheduled on server to be loaded in parallel
- To avoid overloading a single QVW with huge data set use of Document Chaining based on dates or subject areas is recommended so that data is distributed across multiple QlikView documents
http://myserver//QvAJAXZfc/opendoc.htm?document=DocumentName.qvw&host=Local&select=LB01,Value
- In scenarios where there are multiple fact tables use link tables.
- When concatenation is required sequence the load in a manner that the table with less columns should be loaded first and then load and concatenate the table with more number of columns or introduce columns with null values in the table with less number of columns and then load and concatenate
- Try and create a star schema for your data model
- Tags:
- Group_Documents
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Excellent work! Please keep sharing similar posts..
Cheers,
Rahul
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for a great architecture structure.
What are your thoughts in terms of using the 4 layer architecture for Qlik Sense Apps?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Absolutely this architecture can be leveraged in Qlik Sense applications because current versions of QlikView and Qlik Sense use the same engine thus till tier 3 the structure can still be in QlikView just the application layer would be Qlik Sense App instead of QlikView App