Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Remove duplicates from string
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Remove duplicates from string
I have the following string contained in a field:
[1,3,4,8,10,27,27,28,29,12]
I'd like to be able to remove all the duplicate values within this string to end up with:
[1,3,4,8,10,27,28,29,12]
The string itself will always be in this format, with numbers ascending but can be of any length and have any number of duplicate values. Is there a way to achieve this in the script?
Thanks.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can do this in script something like below:
tmpRecords:
Load SourceStr,
SubField(SourceStr, ',') as OneValue
Inline [
SourceStr
"1,3,4,8,10,27,27,28,29,12"
"1,1,4,4,10,28,28,28,29,12"
"1,3,4,5,5,7"
];
NewTable:
LOAD SourceStr,
Concat(distinct OneValue, ',') as CleanStr
Resident tmpRecords
Group by SourceStr;
DROP Table tmpRecords;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Load your field with DIstinct key word
Source:
LOAD distinct * Inline
[
Number
1
3
4
8
10
27
27
28
29
12
];
Regards
Anand
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Would something like this help ?
load
subfield ( String , ',' ) as Sub ,
String
;
LOAD * INLINE [
String
'1,3,4,8,10,27,27,28,29,12'
];
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can do this in script something like below:
tmpRecords:
Load SourceStr,
SubField(SourceStr, ',') as OneValue
Inline [
SourceStr
"1,3,4,8,10,27,27,28,29,12"
"1,1,4,4,10,28,28,28,29,12"
"1,3,4,5,5,7"
];
NewTable:
LOAD SourceStr,
Concat(distinct OneValue, ',') as CleanStr
Resident tmpRecords
Group by SourceStr;
DROP Table tmpRecords;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Ersen, that's exactly what I was looking for.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
RESULT
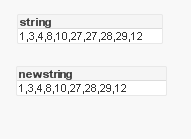
SCRIPT
a:
load * inline [
string
'1,3,4,8,10,27,27,28,29,12'
];
b:
load newstring, rowno() as id;
load subfield(string, ',') as newstring resident a;
c:
load concat(newstring, ',', id) as newstring;
NoConcatenate load newstring, min(id) as id resident b group by newstring;
drop table b;